
Wikisource:Scriptorium/Archives/2016-10
| Please do not post any new comments on this page.
This is a discussion archive first created in , although the comments contained were likely posted before and after this date. See current discussion or the archives index. |
Announcements
I have mail stating that User:Eclecticology (Ray Saintonge) died on 12 September. I'm sure we'll want to remember him for his contributions here, and on WikiLivres. I met him at Wikimania 2007, and he was a pioneer of the DNB project here (before that had formal existence). Charles Matthews (talk) 09:03, 14 September 2016 (UTC)
- @Charles Matthews: Thanks for alerting us. He did a lot for our work in promoting free culture. —Justin (koavf)❤T☮C☺M☯ 13:53, 14 September 2016 (UTC)
- Very sad news. Electron (talk) 08:34, 16 September 2016 (UTC)
Proposals
Exemption Doctrine Policy (EDP)
Some creative commons or public domain documents or texts include images, that are of unknown copyright status, or use non-commercial licenses, or are copyrighted.
Therfore; the English Wikisource community to further the mission of hosting texts, does allow the uploading of images, in creative commons or public domain documents, that may be of unclear copyright, or are copyrighted. under a fair use rubric.
Such fair use will be minimal in that the images are integral to the text, and used in context. Such images will have a custom NC tag Template:Fair Use - [1] [2] to make clear and explicit that downstream re-users will have to evaluate the copyright and limit their use of the images to non-commercial uses, or gain permission from the copyright holder.
Editors will have to upload images locally, with the fair use license, and then insert in the appropriate place in the text.
Questions comments
- I am no expert on copyright, but it makes sense to me that a free-license or public domain text that quotes or embeds small amounts of copyrighted material under "free use" should still be hostable, so I would tentatively support this. —Beleg Tâl (talk) 17:13, 1 September 2016 (UTC)
- For what it's worth, Commons will host the file if you first modify it to strip out the non-free images/text/whatever.
- the motivation for this proposal is when commons deletes images from books, for example here [3] Slowking4 ‽ RAN's revenge 15:24, 10 September 2016 (UTC)
![[3]](https://commons.wikimedia.org/wiki/Commons:Deletion_requests/File:Christ%27s_Entry_Into_Brussels_in_1889.jpg){kind=link}
- I think this actually needs a lawyer. This isn't just a question of editors' policy, but a liability concern. Mukkakukaku (talk) 17:32, 1 September 2016 (UTC)
- the lawyers at the WMF give us the option of adopting a EDP [4]. see the discussion at meta m:Non-free_content. Slowking4 ‽ RAN's revenge 03:04, 10 September 2016 (UTC)
- Question: You say this: "Such fair use will be minimal in that the images are integral to the text, and used in context". What if the image is not integral to the text? As an example, I have a government report that is released as fair use with the exception of logos of government organizations. Since these logos are purely decorative and not actually the topic of the report, what should we do in this situation? (This is a somewhat poor example since we've got fair use copies of these logos created by Wikimedia users, but I don't have another example readily at hand. General situation: there is a non-free image that serves a purely decorative purpose, like say a photo on the cover page or something.) Mukkakukaku (talk) 08:04, 10 September 2016 (UTC)
- I would say that such images are integral to the text. It's the same idea as how when we proofread a text, we exclude things like handwritten notes, bookplates, "digitized by Google", etc.--those are not integral to the text, as they are not part of the work being transcluded, but rather added in later. A decorative image that is included in the publication by the publisher is definitely part of the work, and I would say that if such a policy were adopted these images should also be included. (Note: not speaking for User:Slowking4 here.) —Beleg Tâl (talk) 10:59, 10 September 2016 (UTC)
- logos of government organizations are PD in the US. you cannot release a document as fair use except for images. fair use is case law not a license. when i say integral i mean inline and a part of the whole, logos that indicate the government org in a concise way that words could not convey; i tend to reject the all images are purely decorative argument: the logo provides information like a book cover. in the example,[5] we have a CC document with images from others, those would be integral. Slowking4 ‽ RAN's revenge 11:22, 10 September 2016 (UTC)
![[5]](https://en.wikisource.org/wiki/File:OCW_consortium_screenshot.png){kind=link}
- I am no lawyer, so I can't comment as to the case law bit. But the branch of the Australian government that investigates their plane crashes releases its reports under the Creative Commons Attribution 3.0 Australia Licence, with the exception that the following are not released under that license: "the Coat of Arms, the ATSB logo, photos and graphics in which a third party has copyright". The brief "discussion" on Commons is here. So it does happen that a work is released in part, minus the images. --Mukkakukaku (talk) 14:18, 10 September 2016 (UTC)
- and we could create a "fair use" crown copyright like here [6] for items outside limits of [7] Slowking4 ‽ RAN's revenge 15:24, 10 September 2016 (UTC)
- I am no lawyer, so I can't comment as to the case law bit. But the branch of the Australian government that investigates their plane crashes releases its reports under the Creative Commons Attribution 3.0 Australia Licence, with the exception that the following are not released under that license: "the Coat of Arms, the ATSB logo, photos and graphics in which a third party has copyright". The brief "discussion" on Commons is here. So it does happen that a work is released in part, minus the images. --Mukkakukaku (talk) 14:18, 10 September 2016 (UTC)
Bot approval requests
Removal of local authority control data
The following discussion is closed:
there being no objections, this has started — billinghurst sDrewth 10:47, 22 September 2016 (UTC)
I am proposing that we strip all local authority control parameters from our author-used {{authority control}} template (ie. those author pages in category:Pages using authority control with parameters). Our collection of AC data is now somewhat aged since initial collection and updates and amalgamations have occurred. The Wikidata authority control data is now mature and there are suitable tools available at WD to easily add AC checks as required. I am not seeing any value in having local parameters, it adds complexity, and on some occasions errors or conflicts. The removal is something that has been discussed previously by out-of-enWS operators that they may do, though it hasn't come to fruition.
- As a note there is a tool to check AC data against WD https://tools.wmflabs.org/kasparbot/ac.php for anyone who wishes to delve into error rates, etc. To me the most striking is these 1300+ alerts — billinghurst sDrewth 01:13, 12 September 2016 (UTC)
- Some might be false positives. I checked a couple at random, e.g. Author:Arthur William à Beckett, which should fetch data from WD and it is highlighted as error. Either a mistake in the AC template or in the tool? or me just tired ...
- Maybe a first pass removing just {{Authority control}} will reveal the real differences?
enwikisource Author:Arthur William à Beckett different value on wikidata NLA: 3519 ≠ 35000019- — Mpaa (talk) 22:25, 13 September 2016 (UTC)
- Author:George Miller Beard is another example, {{Authority control}} adds something of its own.— Mpaa (talk) 22:28, 13 September 2016 (UTC)
- My point was meant to be that there are errors, and our having the parameters is pointless as we have no checking mechanisms, whereas at WD they can be readily checked by bots, and can fixed by many. Re GMB his data here was wrong ... (ours) 12430443 vs. 124304434 (WD) which was pretty much my point about just removing them. — billinghurst sDrewth 04:46, 14 September 2016 (UTC)
- Author:George Miller Beard is another example, {{Authority control}} adds something of its own.— Mpaa (talk) 22:28, 13 September 2016 (UTC)
I am proposing that I utilise either User:sDrewthbot or user:Wikisource-bot to remove the parameter detail from those pages. They are simple removals with a simple regular expression match. — billinghurst sDrewth 01:07, 12 September 2016 (UTC)
- Agreed This is one of the reasons why d: exists. —Justin (koavf)❤T☮C☺M☯ 01:11, 12 September 2016 (UTC)
NOTE For those who are author page watchers, if the noise of these bot edits is problematic for you, please make a temporary change to your watchlist preferences to not show bot edits on your watchlist. — billinghurst sDrewth 13:15, 22 September 2016 (UTC)
Repairs (and moves)
Other discussions
Copyright problems which may arise from secondary sources.
Sometimes, the source text of Wikisource is from a secondary source (i.e. a source from other sources)
If the secondary source from which the text in Wikisource is copied infringes the copyright of other sources, and falsely declares the work to be free work, then will we be prosecuted for infringing copyright?
Also, if the copyright status of the source of the secondary source is unclear, while the secondary source declares it to be free work, should we copy it?
Thanks!
Wetitpig0 (talk) 10:44, 12 August 2016 (UTC)
- If there's a work that we want to host, and it is clearly a free work, then we can host it here regardless of where you copy it from, though the usual method of transcluding scans of free books is hugely preferred to copy-pasting from other websites that don't list their sources. If you are unsure of the copyright status, post it at WS:Copyright discussions and the community can evaluate it on a case-by-case basis. —Beleg Tâl (talk) 13:04, 12 August 2016 (UTC)
- i have never seen someone sued under this fact pattern, but i have seen DMCA takedowns of FoP German sculptures, so i would say that is a higher probability. if the secondary source says something, you should be able to make a determination at LOC copyright for orphan works, or translated works. we have outsourced the copyright paranoia to commons. Slowking4 ‽ RAN's revenge 20:33, 13 August 2016 (UTC)
- @Slowking4:, perhaps we should "outsource..." as you suggest, but we haven't done so. I'll leave your characterization aside, because I get what you're saying. If we want to address this issue, we should simply establish a clear policy on what kinds of things we permit under fair use, and what we don't. There is a clear framework for doing so: meta:Licensing_policy_FAQ_draft#Unfree_content_not_under_an_.27exemption_doctrine_policy.27
- As it is, though, we host copyrighted material on English Wikisource, in clear violation of Wikimedia Foundation policy. -Pete (talk) 20:57, 13 August 2016 (UTC)
- The onus is on us to be sure that everything we host at enWS is copyright-free—whether that be because the copyright has expired or because the work was published without copyright. We should not depend on other (non-MediaWiki) sites to have done the work for us. They get it wrong often enough for us to be cautious. @Peteforsyth:, please either point us to the copyrighted material we are hosting or post at WS:COPYVIO so that we can deal with it. Anything that is in clear violation will be removed immediately. If it is unclear we can look at it and discuss. Beeswaxcandle (talk) 00:12, 14 August 2016 (UTC)
- @Beeswaxcandle:, my mistake -- and I regret making a claim that's both inaccurate and provocative. I misremembered the outcome of some books I have transcribed, including one with a few pages like this one: Page:A Basic Guide to Open Educational Resources.pdf/78 I am of the opinion that we should fully host works like this, which are freely licensed on the whole, but which contain a few non-free images (ironically, in this case, to illustrate the difference between free licensing and copyright in an effort to advocate free licensing). But that would require establishing an Exemption Doctrine Policy for English Wikisource, as linked above. -Pete (talk) 00:44, 14 August 2016 (UTC)
- you are changing the subject. the new editor, was struggling with the mein kampf translation copyright, but your case of commons image deletions, proves my point. if you want to make a WS edp, go for it. Slowking4 ‽ RAN's revenge 11:44, 14 August 2016 (UTC)
- Sure. I misunderstood one thing, and misremembered another. I will gladly concede that I have added nothing of value to this particular thread! -Pete (talk) 01:32, 15 August 2016 (UTC)
- oh no, if we get fair use on WS that will be valuable. the risk of suits is so small only a commons admin could calculate it, and the usefulness of images outweighs the downstream reuse restrictions. (and Gutenberg australia has jumped the gun on the english translation of mein kampf, when the translator died in 1946, see you on January 1). Slowking4 ‽ RAN's revenge 02:33, 15 August 2016 (UTC)
- For what it's worth, here's a handy link to my previous suggestion of an EDP: Wikisource:Scriptorium/Archives/2014-05#Dealing_with_non-free_images_in_transcriptions_of_freely_licensed_works -Pete (talk) 02:58, 15 August 2016 (UTC)
- and i still support as much fair use as the community will allow. but i didn’t see much interest. Slowking4 ‽ RAN's revenge 03:02, 18 August 2016 (UTC)
- The translator died in 1946 which is before 1955 (cf. w:Copyright law of Australia), so what's the problem?--Prosfilaes (talk) 07:53, 15 August 2016 (UTC)
- well the translator is Irish and work published in London in 1939, did they reprint it in Australia? maybe we should upload in commons under the 50 rubric and see what happens? Slowking4 ‽ RAN's revenge 02:59, 18 August 2016 (UTC)
- It doesn't matter whether they reprinted it in Australia; Australians are bound by the laws of Australia. The Wikimedia Foundation is bound by the law of the US, and Commons is bound by the additional rules the community created. Gutenberg Australia has every right to upload it to their servers, even when it's not legal for the WMF to host it on theirs.--Prosfilaes (talk) 03:17, 18 August 2016 (UTC)
- i stand corrected about the 50, i’m confused about the not being retroactive. however for the US it is 70 so see you in January. Slowking4 ‽ RAN's revenge 00:09, 19 August 2016 (UTC)
- In the US, it's complicated, but for works published 1923-1978 (copyrighted&renewed or URAA-restored) it's 95 years from publication. So works published in 1939 will be out of copyright in the US in 2035.--Prosfilaes (talk) 20:21, 19 August 2016 (UTC)
- i stand corrected about the 50, i’m confused about the not being retroactive. however for the US it is 70 so see you in January. Slowking4 ‽ RAN's revenge 00:09, 19 August 2016 (UTC)
- if an australian wants to upload a local copy here, what do you say? sorry go to Gutenberg? ready for an EDP yet? Slowking4 ‽ RAN's revenge 22:42, 19 August 2016 (UTC)
- Yes, go host it on an Australian site or Wikilivres. We don't have an option; the WMF is bound by US law. An EDP is irrelevant; at best it could let us host government reports and other PD material that makes use of fair use of still copyrighted material, not straight out copy copyrighted works.--Prosfilaes (talk) 09:30, 20 August 2016 (UTC)
- i would go for a "fair use" of the lesser term, but i take it there is no consensus. derivative first use by governments, does not seem much of a distinction to me. the library of congress has many copyrighted works online. Slowking4 ‽ RAN's revenge 16:07, 20 August 2016 (UTC)
- That's not fair use; that's just illegal. What the LoC can and does do may not have much relation to what we can do. But there are things like NTSB accident reports wherein the copyrighted material used is likely fair use in context.--Prosfilaes (talk) 09:49, 21 August 2016 (UTC)
- no - scholarly use, with a fair use downstream restriction is legal. we stand like the LOC (or internet archive) as a library for scholarly use. your fair use minimization has little basis in law. it is an ideology, apart from the clear law of the 4 factor test. we could very easily put a NC on a work, but we choose not to do so for ideological reasons.
- i take it you would restore the images here [8] care to finalize an EDP. Slowking4 ‽ RAN's revenge 12:31, 21 August 2016 (UTC)
- What's your source for "scholarly use, with a fair use downstream restriction"? The 4 factor test is pretty clear here; this is a non-transformative use that copies the entire work and replaces the original work in commercial use. We lose pretty solidly on all points. This opinion on a lawsuit versus HathiTrust is quite lengthy, going into details like who had access to the servers and how the backup tapes were encrypted, if all HathiTrust needed to say was "we're a library".--Prosfilaes (talk) 11:40, 22 August 2016 (UTC)
- It doesn't matter whether they reprinted it in Australia; Australians are bound by the laws of Australia. The Wikimedia Foundation is bound by the law of the US, and Commons is bound by the additional rules the community created. Gutenberg Australia has every right to upload it to their servers, even when it's not legal for the WMF to host it on theirs.--Prosfilaes (talk) 03:17, 18 August 2016 (UTC)
- well the translator is Irish and work published in London in 1939, did they reprint it in Australia? maybe we should upload in commons under the 50 rubric and see what happens? Slowking4 ‽ RAN's revenge 02:59, 18 August 2016 (UTC)
- For what it's worth, here's a handy link to my previous suggestion of an EDP: Wikisource:Scriptorium/Archives/2014-05#Dealing_with_non-free_images_in_transcriptions_of_freely_licensed_works -Pete (talk) 02:58, 15 August 2016 (UTC)
- you are changing the subject. the new editor, was struggling with the mein kampf translation copyright, but your case of commons image deletions, proves my point. if you want to make a WS edp, go for it. Slowking4 ‽ RAN's revenge 11:44, 14 August 2016 (UTC)
- @Beeswaxcandle:, my mistake -- and I regret making a claim that's both inaccurate and provocative. I misremembered the outcome of some books I have transcribed, including one with a few pages like this one: Page:A Basic Guide to Open Educational Resources.pdf/78 I am of the opinion that we should fully host works like this, which are freely licensed on the whole, but which contain a few non-free images (ironically, in this case, to illustrate the difference between free licensing and copyright in an effort to advocate free licensing). But that would require establishing an Exemption Doctrine Policy for English Wikisource, as linked above. -Pete (talk) 00:44, 14 August 2016 (UTC)
- when we upload as fair use, that is a NC restricting commercial reuse downstream. we can limit downstream use if we choose. do you really want to side with author’s guild? my impression is Hathi Trust won in the end. w:Authors Guild, Inc. v. HathiTrust the court found their use to be fair use even if full copy and non-transformative. the fact that there is already a PD australia version online, means the commercial harm is small for a book that has an e-book for sale for $.99.[9] btw, there are multiple copies of both translations at internet archive, which have not been taken down. in effect we are only cleaning up the OCR of the copies there. in effect the internet makes a "PD of the lesser term": electronic works anywhere are available everywhere for pennies. the main reason for us to transcribe is to make available for wikipedia zero.Slowking4 ‽ RAN's revenge 23:02, 22 August 2016 (UTC)
- We, as in the volunteers at Wikisource, can not limit downstream use if we choose. Wikimedia does not permit NC restrictions on material without narrowly carved fair use exceptions.
- I linked the opinion in Authors Guild v. HathiTrust; the court found their use to be fair use because it was transformative. The Internet frequently makes electronic copies of works available everywhere before they're officially released; that's not an argument for anything. If you want to clean up the OCR of copies available under Canadian law (life+50), Wikilivres is a perfectly legal option.--Prosfilaes (talk) 17:36, 23 August 2016 (UTC)
- when we upload as fair use, that is a NC restricting commercial reuse downstream. we can limit downstream use if we choose. do you really want to side with author’s guild? my impression is Hathi Trust won in the end. w:Authors Guild, Inc. v. HathiTrust the court found their use to be fair use even if full copy and non-transformative. the fact that there is already a PD australia version online, means the commercial harm is small for a book that has an e-book for sale for $.99.[9] btw, there are multiple copies of both translations at internet archive, which have not been taken down. in effect we are only cleaning up the OCR of the copies there. in effect the internet makes a "PD of the lesser term": electronic works anywhere are available everywhere for pennies. the main reason for us to transcribe is to make available for wikipedia zero.Slowking4 ‽ RAN's revenge 23:02, 22 August 2016 (UTC)
- we volunteers can certainly adopt an EDP that allows fair use and CC-by-NC. i have 30 times your edits here - where are the 29 other people you will recruit, when i decide to take a vacation over at https://transcription.si.edu/ ?? Slowking4 ‽ RAN's revenge 02:14, 27 August 2016 (UTC)
Disambiguation and Wikidata items — a conundrum with no perfect solution
Something that the community may wish to consider.
An item at Wikidata has one link per wiki to an item, and this restriction applies to items that are disambiguation pages. As such when we link a disambiguation page to a Wikidata item, we are having to make a determination whether this will be a main namespace disambig, an author namespace disambig, or another disambig, maybe in Portal: ns.
Example. We have Author:William Hutton and William Hutton both of which are disambiguation pages, and at Wikidata the disambiguation item is d:Q16213077. At the moment we link to the main ns page.
Which of these do we think is the preferred page to link? I prefer that we linked the Author: ns (disambiguation) pages, and main reason is that we are linking people to people (or at least people analogues), whereas the main ns. is a work about a person, rather than the person themself. Plus the main ns page can be a title about a fiction work, and then we have difficulties of separating fact and fiction.
Of course, we could challenge the concept of disambiguation pages in separate namespaces which has some merits, though would also challenge the concepts of namespace separations. Anyway, thoughts would be appreciated. — billinghurst sDrewth 07:10, 18 August 2016 (UTC)
- I'm inclined to think this issue highlights a design flaw on our own part. A disambiguation page should disambiguate all of the relevant meanings of a search term, and a search term should have not more than one disambiguation page. We shouldn't have separate disambiguation pages for works, authors... portals?... etc. Pages like Author:William Hutton shouldn't exist. Disambiguation pages should exist only in the main namespace, and all disambiguation pages in other namespaces should be merged/moved to main. Hesperian 07:49, 18 August 2016 (UTC)
- @Library Guy, @Charles Matthews: worthwhile waving this under your noses as you have experience in the place and people space. — billinghurst sDrewth 10:02, 18 August 2016 (UTC)
- I generally agree with User:Hesperian. Well, qualifying that, I would use a cross-namespace redirect of Author:William Hutton to William Hutton, rather than deleting it. Charles Matthews (talk) 10:13, 18 August 2016 (UTC)
- ... which would require a change of policy as these currently fall into speedy deletion space. That said that we have been leaving such for a period before having them as dated soft redirects. — billinghurst sDrewth 13:34, 18 August 2016 (UTC)
- I agree with User:Hesperian. I would rather not have the cross-namespace redirect, and author pages should correspond to actual authors, or redirects to such. I have thought it useful to have redirects from variations on an author's name to that author's page, but sometimes the name used on a work may be used by more than one of our authors. When the latter is the case, then the redirect should no longer be used, and a direct link from the work to the author page should be used, preserving the name used on the work as a label for the link. Library Guy (talk) 16:22, 18 August 2016 (UTC)
- I generally agree with User:Hesperian. Well, qualifying that, I would use a cross-namespace redirect of Author:William Hutton to William Hutton, rather than deleting it. Charles Matthews (talk) 10:13, 18 August 2016 (UTC)
- I disagree with the above. I think both disambiguation pages are appropriate as they serve different purposes. Different authors are disambiguated in author space, articles about those authors (or encyclopedia articles) with the same/similar titles should be disambiguated is mainspace, so both disambiguation pages (appropriately) should exist as they perform similar yet different ourposes. And as billinghurst originally suggested, a people-to-authorspace redirdct is appropriate.
- Unless there's some nuance to this discussion that I'm missing. --Mukkakukaku (talk) 17:40, 18 August 2016 (UTC)
![]() Comment I am wishing to drive this further, and it would seem that there is some diversity of opinion. We are in a half way place, and it is unsuitable place to be, as it unsustainable for results. So I am asking on how we should be progressing this matter. Would people like to see Help:Disambiguation drafted and argue it out on a talk page? Would users like to see it hammered out here, though maybe with a couple of alternatives put forward? Would users like to see full RFC put together?
Comment I am wishing to drive this further, and it would seem that there is some diversity of opinion. We are in a half way place, and it is unsuitable place to be, as it unsustainable for results. So I am asking on how we should be progressing this matter. Would people like to see Help:Disambiguation drafted and argue it out on a talk page? Would users like to see it hammered out here, though maybe with a couple of alternatives put forward? Would users like to see full RFC put together?
- If a 'position' hasn't yet emerged, then I think all we can do is continue this discussion and hope we get more eyes and input. Once a 'position' has firmed up, then perhaps an explicit proposal in the proposals section above, to be voted on by the community? Hesperian 01:46, 29 August 2016 (UTC)
- It seems awkward to make an initial contribution to a policy discussion via a series of questions; nevertheless: would somebody please be so kind as to lay out (or point to where discussion took place if known):
- what was the reasoning for discouraging cross-name-space redirects in the first place?
- what is the reasoning for en/discouraging certain name spaces as "top level" (i.e. starting points for navigation)? To me Author: or Portal: ought to represent the "index" (I know: true Index: space is really a local working space only and thus of little concern to end-consumers) above main space for locating works within wikisource. (But where does that leave Category: space?)
- Is it possible wikidata use is revealing problems because it is encouraging a wikipedia-appropriate hierarchy which is fundamentally unsuited to wikisource? How are the sister projects addressing these issues (if they are facing them; if not: why not—or has the solution already been thrashed out elsewhere?) AuFCL (talk) 04:14, 29 August 2016 (UTC)
- Re
- Not known to me for the original policy, though I do see that it stops an ugly mess of redirects proliferating. When would you stop adding main ns to author ns? main ns to portal ns? For historic reasoning, you would need to find a really old timer. It may have even been imported from the single multilanguage Wikisource prior to the schism.
- That was a discussion that was had (and lost?) early about the namespaces names. With regard to category vs. "display" or "curated" namespaces like author and portal, it was so we could should show more than a pagetitle, plus where we have subpages of works it truly becomes really ugly at 200 entries per page. IMNSHO for the display namespaces, we should be looking for bot runs from Wikidata to populate things like Wikisource:Authors-A and other like pages. That may even be possible for Author: and Portal: ns pages, however, we will need to get a hell of a lot better at WD additions and editing prior to that proposal coming forward. Noting that portal came a lot later as a functional ns here, for ages it was just a wasteland of nothingness. I know that discussion is in these archives.
- Wikidata has definitely shown the breakages of a WP model on application to the WSes, especially with relation to books <=> editions, and one to one linkages. It also profoundly shows that WP is the archetypal model for everything, which can be seen as bad, though the popularity of WP allows much of what happens to happen.
- Discussion of disambiguation and the approaches of one or multiple namespaces is too big a discussion to append here. One can say that each implementation of WD to the other sister wikis has identified issues with the model, they are just different between the sisters. Commons has particularly significant issues, and their mode of action is to basically ignore WD. <shrug> — billinghurst sDrewth 06:09, 29 August 2016 (UTC)
- Re
- Thanks for attempting to answer. I do not pretend some of these issues aren't close to impossible.
- As a compatibility-sop to the wikipedia model, would moving (to) or creating all disambiguation pages (in) main-space; and relaxing the no-cross-name-space redirect rules to permit redirections from any name-space directly to a disambiguation page get us anywhere useful? AuFCL (talk) 07:03, 29 August 2016 (UTC)
Did any of these get renewed? And if not does archive.org have any scans? ShakespeareFan00 (talk) 19:47, 19 August 2016 (UTC)
- Gilberton Company, seems to be renewed [10] Frawley has 3 renewed [11]. Elliot Publishing Co. will have to look at print copy. Slowking4 ‽ RAN's revenge 02:06, 27 August 2016 (UTC)
Image required for On the Vatican Library of Sixtus IV
Hi. Just checking my previous work as I continue on my wikidata data completion trek. I have a poor scan on an page at Page:On the Vatican Library of Sixtus IV.djvu/59 and I am wondering whether anyone can see an available scan at https://www.google.com/search?tbm=bks&q=Vatican+Library+of+Sixtus or at HathiTrust for that page. Thanks for anyone who looks.
As a note while I have attention, do remember that for proofread or validated texts that you can add that transcription status to the link by clicking on the grey keyhole like image when editing the link and choosing the corresponding status —not proofread/proofread/validated) — it is still manual at this time. <shrug> — billinghurst sDrewth 00:21, 22 August 2016 (UTC)
- Could not find a full-page image online. I put in an ILL request for a scan with my local library; hopefully a copy is available somewhere. It may take some time. Londonjackbooks (talk) 01:02, 22 August 2016 (UTC)
- I have absolutely no idea where they originally found it but I am pretty sure this is a copy of the missing image c/o Project Gutenburg. Technically this came out of another John Willis Clark work: it is "Figure 98." from "The Care of Books" (project 26378.)
{kind=link}
- On further examination it looks like this might be the "rawest" page scan (in colour no less!) AuFCL (talk) 07:14, 22 August 2016 (UTC)
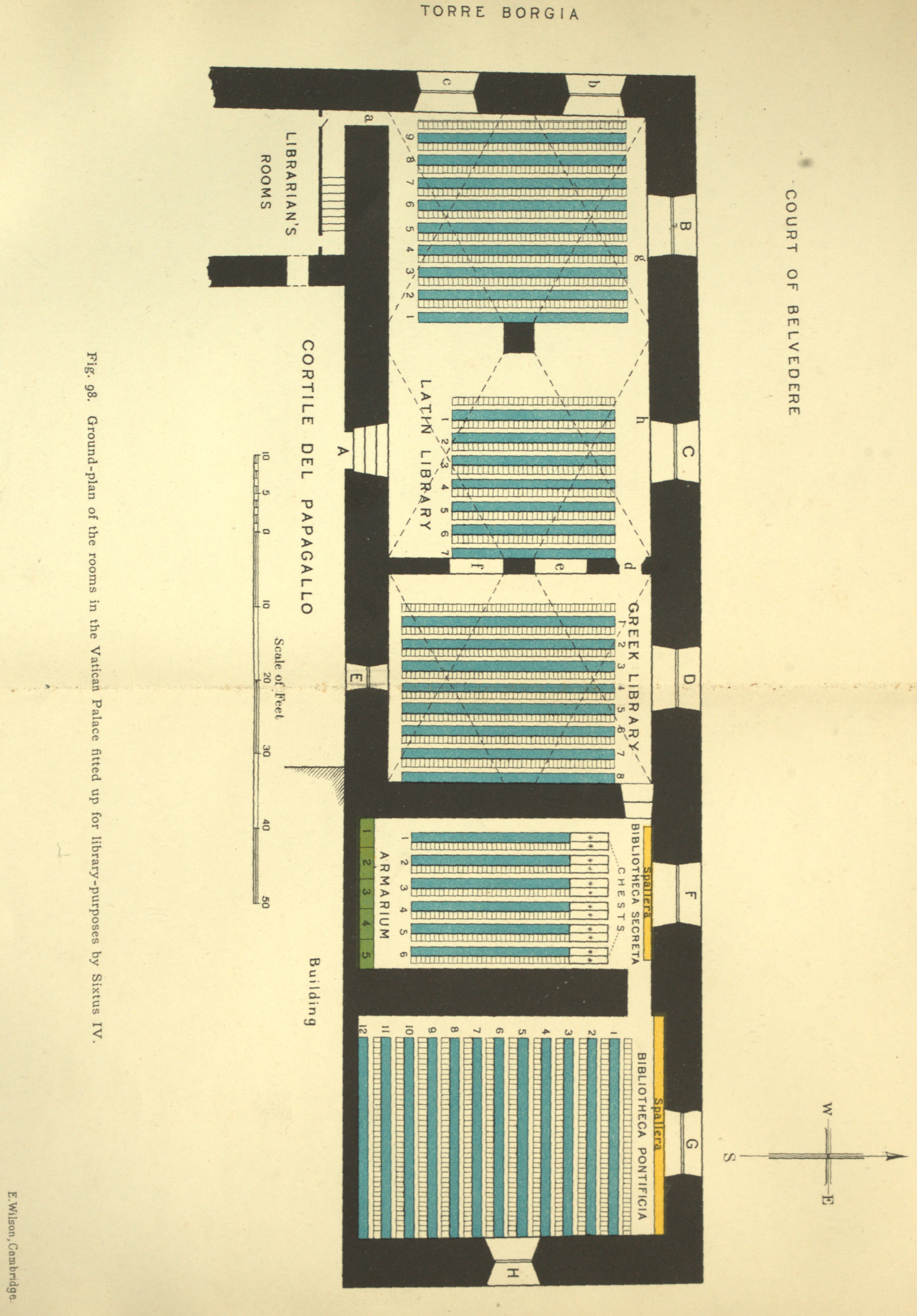{kind=link}
- As an aside there is something screwy revealed by Author:John Willis Clark. According to IA "The Care of Books" was published in 1909 but the title page reads 1901 and the end of the Preface is dated September 23rd, 1901. Manuscript on a dusty shelf a long time?
(Maybe the floor plan of Cortile del Pagagllo is more original there than in "On the Vatican Library of Sixtus IV" after all?)AuFCL (talk) 08:37, 22 August 2016 (UTC)- Thanks for the image links. The "Care of Books" may have just had later editions or republications, with 1909 being the edition scanned. Or equally possible is that IA has made a mistake with their dates. — billinghurst sDrewth 10:26, 22 August 2016 (UTC)
- LOC says 1901 edition also reprinted in 1973 by folcroft [12]. IA metadata use with caution. multiple editions sloshing around. here’s an OCLC master electronic copy link [13] Slowking4 ‽ RAN's revenge 22:33, 22 August 2016 (UTC)
- I never trust IA metadata. I was looking at a volume yesterday for which they had the wrong title, wrong author, wrong date, wrong publisher, etc. The fact had been commented on by a reviewer, but there doesn't seem to be a simple means for correcting errors like we can do here. --EncycloPetey (talk) 20:48, 23 August 2016 (UTC)
- LOC says 1901 edition also reprinted in 1973 by folcroft [12]. IA metadata use with caution. multiple editions sloshing around. here’s an OCLC master electronic copy link [13] Slowking4 ‽ RAN's revenge 22:33, 22 August 2016 (UTC)
- Thanks for the image links. The "Care of Books" may have just had later editions or republications, with 1909 being the edition scanned. Or equally possible is that IA has made a mistake with their dates. — billinghurst sDrewth 10:26, 22 August 2016 (UTC)
- As an aside there is something screwy revealed by Author:John Willis Clark. According to IA "The Care of Books" was published in 1909 but the title page reads 1901 and the end of the Preface is dated September 23rd, 1901. Manuscript on a dusty shelf a long time?
Sometime this week I should be receiving an unfolded electronic scan of fig. 2. It should be a scan from the same version we have hosted here, but we'll see. The ILL request status is "awaiting processing", and I will update as soon as I receive the document and determine the scan quality, etc. Londonjackbooks (talk) 17:57, 18 September 2016 (UTC)
@Billinghurst: I received an unfolded scan from my library (Interlibrary Loan), and have saved the image to Commons (Commons:File:On the Vatican Library of Sixtus IV DJVU pg 59.jpg). The fig. 2 caption differed from what was transcribed in the Page:namespace, so I adjusted it. Only thing missing from the new image is the "TORRE BORGIA" label located to the left on the Gutenberg image. I am not sure if it was cut off during the scanning process or not even present in the text. Feel free to use the new image unless you prefer to keep the Gutenberg image... but is it my understanding that the Gutenberg image is from a completely different text? Londonjackbooks (talk) 19:36, 20 September 2016 (UTC)
{kind=link}
P.S. There is this image at IA from Proceedings of the Cambridge Antiquarian Society, with communications made to the society Vol 10 (1898-1903). Seems the image has been used in multiple texts. Londonjackbooks (talk) 22:53, 20 September 2016 (UTC)
Proofread of the month
I've returned after a few long hiatus and was looking at the proofread of the month to ease back into things and I noticed the project page still lists the project for July. I'm not sure how to update this or what the project is for August. Can anyone help? Thank you :) Marjoleinkl (talk) 11:31, 23 August 2016 (UTC)
- That is because Index:The Fauna of British India, including Ceylon and Burma (Birds Vol 1).djvu, which was selected for July, was unfinished and a new selection was made for August, Index:The Mythology of the Aryan Nations.djvu. For the future, we should be careful (as a site) to not have two works active for POTM again. - Tannertsf (talk) 14:03, 23 August 2016 (UTC)
- Thanks for the update, I’ll see what I can do to help :) Marjoleinkl (talk) 14:06, 23 August 2016 (UTC)
- We were actually quite successful in the first half of the year in knocking out two works per month for POTM. It just happens that The Fauna of British India has more complicated formatting and image issues than we have normally been addressing. BD2412 T 14:28, 23 August 2016 (UTC)
- Thanks for the update, I’ll see what I can do to help :) Marjoleinkl (talk) 14:06, 23 August 2016 (UTC)
- Yeah I guess we were. I hate to see works done super fast though because what if someone wanted to do the book themselves? - Tannertsf (talk) 14:39, 23 August 2016 (UTC)
- The goal of the project is to get works up and running. The only way we can do that, with the volume of works to consider, is to do it as fast as we can. BD2412 T 15:33, 23 August 2016 (UTC)
- Yeah I guess we were. I hate to see works done super fast though because what if someone wanted to do the book themselves? - Tannertsf (talk) 14:39, 23 August 2016 (UTC)
- @Tannertsf: We select a project for the month. When the month ends, we move on to the next month's PotM, even if the previous month's work is incomplete. There have been one or two works that were close enough to completion that we left them in place for a few days, but we don't linger over unfinished works. If we did that, we'd still be working in the Flora of Antarctica from last year. --EncycloPetey (talk) 20:33, 23 August 2016 (UTC)
- Ok, thank you for explaining. - Tannertsf (talk) 20:38, 23 August 2016 (UTC)
- All that said, we really need to get on the ball to progress on the current project. BD2412 T 13:59, 25 August 2016 (UTC)
- I tried having a look at Index:The Fauna of British India, including Ceylon and Burma (Birds Vol 1).djvu but it’s quite a complex work for someone just getting back into things. I’ll have a look at the selection for this month Marjoleinkl (talk) 06:30, 26 August 2016 (UTC)
- All that said, we really need to get on the ball to progress on the current project. BD2412 T 13:59, 25 August 2016 (UTC)
- Ok, thank you for explaining. - Tannertsf (talk) 20:38, 23 August 2016 (UTC)
@Marjoleinkl: welcome back. Do see WT:Proofread of the Month for what is planned for PotM, and please do contribute a point of view for future works. We put forward proposed themes for the months a year ahead, and we take suggestions for each month consistently. We do like fresh faces contributing there as fresh faces brings fresh opinions and participation. PotM is important for us to bring in and bring back casual and occasional users not just those of us 'rusted on'. — billinghurst sDrewth 23:55, 23 August 2016 (UTC)
- for the Index:The Mythology of the Aryan Nations.djvu PotM, is there a consensus to ditch the side footnotes? user:EncycloPetey ? does not seem to add much value to me. Slowking4 ‽ RAN's revenge 14:59, 27 August 2016 (UTC)
Non-free images in otherwise copyright-free material
So there was a brief discussion here about this issue, but it didn't appear to get a concensus: Wikisource:Scriptorium/Archives/2014-05#Dealing with non-free images in transcriptions of freely licensed works.
Effectively I have the following scenario: Australian aviation accident reports are released under the Creative Commons Attribution 3.0 Australia Licence, with the exception that the following are not released under that license: "the Coat of Arms, the ATSB logo, photos and graphics in which a third party has copyright". The copyright statement(s) in full can be found here on the government website.
So, I figure I have the following options:
- Upload the entire PDF as-is to Commons, and...
- add a note in the Commons description which images are not free of copyright
- on the Index talk page add a note about not transcribing the non-free images
- in the text itself putting some sort of placeholder image to indicate a non-free image (so that the reader knows to go look at the original source for the image; important if the text is referencing a photo or something)
- Self-censor the PDF prior to uploading, removing any logos and non-free photos and replacing them with either a placeholder image or blank page as needed.
- ... other option(s)?
It would be nice if we had a concrete policy in place for a situation like this. Or if we had one, if the six pages about copyright that we have could be updated to call it out. --Mukkakukaku (talk) 13:26, 23 August 2016 (UTC)

- Commons is Commons; you really should discuss their policies there. However, they don't have fair use, so you'll most likely have to delete the copyrighted images from the PDF.
- We do have a policy, in that we have no fair-use policy, so by WMF rules, we can't host works that aren't 100% PD. In some cases we may be able to talk about de minimis, but in the general case, the photos from the aviation reports have to be deleted. I've looked at US aviation reports and have been discouraged by the same problem, that many of them would need a number of important maps and photos deleted.
- I will say the Coat of Arms and ATSB logo are likely to pass de minimis for Commons, and aren't that important for reproducing here. Commons actually hosts a copy of the Coat of Arms that will probably do for replacing the CoA on Wikisource.--Prosfilaes (talk) 17:55, 23 August 2016 (UTC)
- OK, I asked at Commons and got a response indicating that Commons can only host it if the non-free images are removed. Does anyone know of any software for modifying PDFs that will allow me to do this? Eg some sort of PDF editing software that allows actual editing and not just wholesale removal of pages? --Mukkakukaku (talk) 21:22, 23 August 2016 (UTC)
- let’s adopt a EDP that allows fair use images here and put a CC-by-NC on them. then upload the work here. see also the work mentioned above Wikisource:Scriptorium/Archives/2014-05#Dealing_with_non-free_images_in_transcriptions_of_freely_licensed_works; see also m:Licensing_policy_FAQ_draft#Unfree_content_not_under_an_.27exemption_doctrine_policy.27 Slowking4 ‽ RAN's revenge 01:46, 27 August 2016 (UTC)
- @Slowking4: Maybe you should consider formalizing these ideas and dropping them up in the Proposals section? Mukkakukaku (talk) 20:54, 27 August 2016 (UTC)
- ok, i have put in a minimal proposal here Wikisource:Scriptorium#Exemption_Doctrine_Policy_.28EDP.29 feel free to rewrite, or object to it. we have an uploader, but will need a fair use license template if approved. Slowking4 ‽ RAN's revenge 02:33, 30 August 2016 (UTC)
Project Scanning books
Hi, I am thinking to make a grant application (either to the WMF or Wikimedia France, or both) to scan books not available online. Until now it is only for books in French. Do you think making a multilingual grant request would be useful? Would you like to have some books scanned? If yes, could you make a list? Feel free to ask other Wikisources. Regards, Yann (talk) 19:09, 23 August 2016 (UTC)
- What I would really like is to have access to a good scanner and training on scanning and creating scan files. I have a computer, and several books that really need to be scanned (and aren't in Hathi or IA). Perhaps a collection of tutorial videos, or local events that teach scanning could be part of the grant application? --EncycloPetey (talk) 20:29, 23 August 2016 (UTC)
- Wikimedia France has a book scanner in Paris. That's one of the possibilities to scan books. Another one would be to ask GLAMs to do it against some money. The French National Library does it for 45 € per book (cost to be confirmed). Regards, Yann (talk) 16:18, 24 August 2016 (UTC)

- you should try the rapid grants to see if they will fund book scanning. m:Grants:Project/Rapid
- typically, the research library should have a book scanner setup. the benefit being that it automatically crops and delivers a pdf to your usb drive to take away. there are do-it-yourself rigs which we had a demo of at wikisource conference. also flatbed scanners with a usb are cheap for images, but they are one page pdf at a time. Slowking4 ‽ RAN's revenge 15:14, 25 August 2016 (UTC)
- Flying to Europe to make scans would be too expensive for me. A flatbed scanner is not an option for the large and fragile old books I am looking to scan. I have tried contacting IA several times, because they are less than 2 hours away on a good traffic day, but they have never responded to my inquiries. --EncycloPetey (talk) 03:39, 28 August 2016 (UTC)
- talk to your friendly neighborhood academic librarian, they may be able to help you - see also - [14], i.e. [15]. Slowking4 ‽ RAN's revenge 02:05, 30 August 2016 (UTC)
- Not an immediate for English Wikisource, but presumably French Wikisource has Dumas and Jules Verne originals? ShakespeareFan00 (talk) 17:02, 25 August 2016 (UTC)
- And something that's a more pressing concern is Volume 8 of a specific edition of the New International Encylopedia to replace/substitute for a volume which appears to be damaged within the Internet Archive's set. Index:The New International Encyclopædia 1st ed. v. 07.djvuand Index:The New International Encyclopædia 1st ed. v. 09.djvu
being the volumes either side of the 'missing' one. :) ShakespeareFan00 (talk) 17:06, 25 August 2016 (UTC)
- Although not books as such, I was going to suggest consideration be given to the scanning of other "text" resources such as (not exhaustive) :
- Instruction manuals. (which can be a single sheet/booklet).
- guide booklets.
- pamphlets. (in looking at some material in a museum the amount of printed ephemra the UK government generated (even prior to 1965 was quite suprising! )
- (old) examination papers. (And the printed answers if they existed.)
- auction catalouges etc...
- small-ads. ( Whilst the layout on Wikisource is not ideal, small ads are a gold mine for social historians.) :)
Scanning printed ephemra may well have to be doene through GLAM though as the most likely source of these are archives and record offices, but these are historical materials often overlooked. ShakespeareFan00 (talk) 17:20, 25 August 2016 (UTC)
- In short , getting a grant for a multi-lingual 'Scanning Fund' would be useful (provided the WMF is prepared to work with other organisations like Internet Archive and GLAM partners.) ShakespeareFan00 (talk) 17:25, 25 August 2016 (UTC)
- On the topic of ephemera: there exists commons:Template:Inscription for transcribing small single-image items with only a small amount of text. I sometimes think it's better to bring things over here to Wikisource anyway (for discoverability, categorisation, and general completeness) but there's certainly a line somewhere between what should be on Wikisource and what left only on Commons. Sam Wilson 23:38, 25 August 2016 (UTC)
- Google Books has scanned the second edition of John Ogilby's translation of The Works of Publius Vergilius Maro, but not his Homer: His Iliads Translated. (Ditto for Homer: His Odysses Translated and The Fables of Æsop Paraphrased in Verse by the same author.) Problem: Homer: His Iliads Translated is a very old and rare book. Maybe you can find it in one or two libraries (University of Toronto, or Rochester) but they might not give you permission (or have the means) to scan it. Anyway, it would certainly be at the top of my wish list. ~ DanielTom (talk) 21:09, 25 August 2016 (UTC)
- There are microfilm and microform copies of Ogilby's Iliad and probably his Odyssey. Those are on the edge of something someone really doesn't want us to copy but can't stop us (at least in the US.) His Æsop was reprinted by the Augustan Reprint Society, and until the mid-1980s, none of their works I saw had copyright notices, so you can probably get a copy of that and reprint the whole thing, modern introduction and all.--Prosfilaes (talk) 21:54, 26 August 2016 (UTC)
FT blurb help
We've got people nominating Featured Texts this year, which is great. However, we still don't have volunteers writing the blurb for the Main page that explains the significance of the work / edition to accompany the FT selection.
We've got four days left in August until The Adventures Of A Revolutionary Soldier will feature, but still no blurb. IF there is someone willing, please suggest some blurb text at WS:FTC#The Adventures Of A Revolutionary Soldier. --EncycloPetey (talk) 03:37, 28 August 2016 (UTC)
- i like the blurb of user:Mukkakukaku. Slowking4 ‽ RAN's revenge 02:03, 30 August 2016 (UTC)
![]() Done Blurb has been edited and loaded into the next month's template. Thanks for the assistance! --EncycloPetey (talk) 02:16, 30 August 2016 (UTC)
Done Blurb has been edited and loaded into the next month's template. Thanks for the assistance! --EncycloPetey (talk) 02:16, 30 August 2016 (UTC)
Clara Bell or Dell?
Who do you think is the translator? See Page:Pierre_and_Jean_-_Clara_Bell_-_1902.djvu/11. Could not find many traces of Clara Dell but a typo in the cover is weird, no? Opinons welcome.— Mpaa (talk) 21:05, 28 August 2016 (UTC)
- Think that it will be w:Clara Bell. I will hazard a guess that the British versions say Bell, and the US versions say <d'oh>Dell</d'oh>. Also if you search for clara bell translator Maupassant you should get enough hits for an evidence base. I would think that if you did a search of "The Times" that you will see its publication advertised. — billinghurst sDrewth 21:16, 28 August 2016 (UTC)
Latest tech news from the Wikimedia technical community. Please tell other users about these changes. Not all changes will affect you. Translations are available.
Recent changes
- Wikimedia mobile sites now don't load images if the user doesn't see them. This is to save mobile data and make the pages load faster. [16]
- When you edit a table with the visual editor, pressing
Tabin the last cell of a row will take you to the first cell in the next row. PressingShiftandTabin the first cell of a row will take you to the last cell in the previous row. [17]
Changes this week
- The name of the "Save page" button will change. The button will say "Publish page" when you create a new page. It will say "Publish changes" when you change an existing page. [18][19]
 The new version of MediaWiki will be on test wikis and MediaWiki.org from 30 August. It will be on non-Wikipedia wikis and some Wikipedias from 31 August. It will be on all wikis from 1 September (calendar).
The new version of MediaWiki will be on test wikis and MediaWiki.org from 30 August. It will be on non-Wikipedia wikis and some Wikipedias from 31 August. It will be on all wikis from 1 September (calendar).
Meetings
- You can join the next meeting with the VisualEditor team. During the meeting, you can tell developers which bugs you think are the most important. The meeting will be on 30 August at 19:00 (UTC). See how to join.
 You can join the next meeting with the Architecture committee. The topic this week is "RfC: image and oldimage tables". The meeting will be on 31 August at 21:00 (UTC). See how to join.
You can join the next meeting with the Architecture committee. The topic this week is "RfC: image and oldimage tables". The meeting will be on 31 August at 21:00 (UTC). See how to join.
Tech news prepared by tech ambassadors and posted by bot • Contribute • Translate • Get help • Give feedback • Subscribe or unsubscribe.
15:59, 29 August 2016 (UTC)
Deprecating the "long s" template
This is an extension of a discussion that came up between myself, DanielTom and Beeswaxcandle. On the work Sir Martyn, there is an excessive use of the long-s and it frankly becomes an outright pain to use. See, for example, the source of page 3, or this diff of a change to add in the long-s on page 12 -- it's really irritating and non-trivial to be putting the {{ls}} template everywhere.
According to the Style Guide, it's preferred to use the long-s to match the source text. Specifically, the style guide says as follows:
- 5. Special characters such as accents and ligatures should be used wherever they appear in the original document, if reasonably easy to accomplish. This can be achieved by using the special character menu shown below the editing form; or typography templates (such as {{long s}} (ſ)), which may help avoid confusion between special and alphabetical characters.
However, Beeswaxcandle pointed out that we've been using it as an "optional" template, where the first significant proofreader on a work decides whether to use them or not, and generally lets people know via the talk page. This policy, or subversion of policy, isn't documented anywhere that I could find. Apparently there's been discussion of this particular template in the past, but the documentation doesn't appear to have been updated to reflect the results of the discussion.
Either way, I'd like to (re-)propose the deprecation of this template on any future works for the following reasons:
- The long-s is a typographical artifact. It has little or no semantic value. We've deprecated {{Ligature Latin ct lowercase}} and family for similar reasons. (Sidenote -- those templates were deprecated years ago, why are they still in use?)
- It's hard to use. As shown by the above example links, it severely clutters the text you're proofreading, and makes it exceedingly difficult to either proofread or validate if there's enough of them.
- It's hard to read. Clearly subjective and supposedly toggleable off by some hidden tool somewhere.
- The usage guidelines aren't entirely clear. The style guide says to use them, but it turns out we're not consistent. The inconsistency pretty much boils down to "use it if you're the first, and you want to."
- Not all browsers, fonts, etc. render the long s. It doesn't render for me on talk pages or scriptorium, for example. This looks like a regular lower-case s to me: s.
Unlike the ct ligature family of templates, the long-s degrades gracefully to a regular s, so it doesn't affect search engine results. This was a key point in the deprecation of the ct ligature template family which does not apply to the long-s. I don't know if it similarly fails gracefully for screen readers, but I would presume it does.
Thoughts? Mukkakukaku (talk) 14:39, 30 August 2016 (UTC)
- Also there's a goofy {{s}} template that's similar to {{long s}}/{{ls}} which I didn't even know existed until I typoed it above. Might as well include that too in the discussion. Mukkakukaku (talk) 14:40, 30 August 2016 (UTC)
- Yeah, I don't see the point of {{s}}, and would support deleting it. —Beleg Tâl (talk) 15:20, 30 August 2016 (UTC)
 Oppose, though only weakly. It's not entirely comparable to {{Ligature Latin ct lowercase}}, which is font-related and not character-related. The template {{ls}} allows to use 's' if desired and 'ſ' if desired and allows the page to be faithfully imitated but the mainspace article to be easily read. Further, it is normal on WS for guidelines to be consistent inside a work but inconsistent between works. The key point in the style guide is "if reasonably easy to accomplish"; if {{ls}} is not reasonably easy for you, skip it, but it's reasonably easy for me, so I use it. —Beleg Tâl (talk) 15:19, 30 August 2016 (UTC)
Oppose, though only weakly. It's not entirely comparable to {{Ligature Latin ct lowercase}}, which is font-related and not character-related. The template {{ls}} allows to use 's' if desired and 'ſ' if desired and allows the page to be faithfully imitated but the mainspace article to be easily read. Further, it is normal on WS for guidelines to be consistent inside a work but inconsistent between works. The key point in the style guide is "if reasonably easy to accomplish"; if {{ls}} is not reasonably easy for you, skip it, but it's reasonably easy for me, so I use it. —Beleg Tâl (talk) 15:19, 30 August 2016 (UTC)
- Oppose While I agree that in the majority of situations, using this template (or long-s) is pointless, there are some works where the long-s ought to be preserved because it wasn't always simply typographical. It ought to be preserved in works like the First Folio of Shakespeare, or the (original) Authorized Version of the Bible. In works such as these, the details carry more significance because of the scrutiny and study value to scholars. But I do agree that we shouldn't encourage the template's use, and should consider replacing it or subst'ing it wherever it occurs. It's primary value lies in text entry and editing, but once it has been put in it should be replaced / subst'ed. --EncycloPetey (talk) 16:03, 30 August 2016 (UTC)
- This is an interesting contra position, thank you for sharing. Can you explain a bit what makes it non-typographical in the cases that you cited -- for example, Shakespeare's First Folio? I'm really not familiar with those works, so I don't really understand where this delineation between typographical-versus-some other meaning lies. Mukkakukaku (talk) 18:38, 30 August 2016 (UTC)
- Long-s is a medial form of the letter "s", and not a typographical variant. Medial forms are forms of a letter that appear in the middles of words, as opposed to a capital (which is limited to the beginning of a word) or a terminal (which is limited to the ending of a word). The long-s is a medial form because its presence is dictated by position in the word, and not by font, manuscript hand, or typography. Medial forms are uncommon in Western languages, but do show up in Greek, Hebrew, and Arabic. --EncycloPetey (talk) 20:41, 30 August 2016 (UTC)
- I'm not sure I agree with your boxing. It is a medial form, a medial form that appears in certain fonts, manuscript hands and forms of typography. It could be done in most cases by automatic smart features in a font (with a ZWNJ to indicate the short s), like is done in Arabic fonts. This is a definition game, of course, and neither of us is objectively right.--Prosfilaes (talk) 21:14, 30 August 2016 (UTC)
- Sometimes an ordinary "s" is used medially when it appears at the end of a word immediately followed by another in a compound. For one example note the spelling "bliſsful" on line 5 of Paradise Lost. This is not so commonly seen in English works, but the same convention is very important in older German orthography, as it makes long compound words easier to parse. Mudbringer (talk) 03:11, 31 August 2016 (UTC)
- That's not a particularly good example, since ss is often written as ſs no matter where it is in the word. Going over to "I may aſſert th' Eternal Providence," it doesn't seem this typesetter used that convention. However, I suspect those typographers that use that rule also avoided ct and other ligatures over such word boundaries.--Prosfilaes (talk) 00:47, 1 September 2016 (UTC)
- It must be fairly common, as there was a ligature for both ſſ and ſſi.--T. Mazzei (talk) 17:51, 2 September 2016 (UTC)
- That's not a particularly good example, since ss is often written as ſs no matter where it is in the word. Going over to "I may aſſert th' Eternal Providence," it doesn't seem this typesetter used that convention. However, I suspect those typographers that use that rule also avoided ct and other ligatures over such word boundaries.--Prosfilaes (talk) 00:47, 1 September 2016 (UTC)
- Sometimes an ordinary "s" is used medially when it appears at the end of a word immediately followed by another in a compound. For one example note the spelling "bliſsful" on line 5 of Paradise Lost. This is not so commonly seen in English works, but the same convention is very important in older German orthography, as it makes long compound words easier to parse. Mudbringer (talk) 03:11, 31 August 2016 (UTC)
- I'm not sure I agree with your boxing. It is a medial form, a medial form that appears in certain fonts, manuscript hands and forms of typography. It could be done in most cases by automatic smart features in a font (with a ZWNJ to indicate the short s), like is done in Arabic fonts. This is a definition game, of course, and neither of us is objectively right.--Prosfilaes (talk) 21:14, 30 August 2016 (UTC)
- Long-s is a medial form of the letter "s", and not a typographical variant. Medial forms are forms of a letter that appear in the middles of words, as opposed to a capital (which is limited to the beginning of a word) or a terminal (which is limited to the ending of a word). The long-s is a medial form because its presence is dictated by position in the word, and not by font, manuscript hand, or typography. Medial forms are uncommon in Western languages, but do show up in Greek, Hebrew, and Arabic. --EncycloPetey (talk) 20:41, 30 August 2016 (UTC)
- This is an interesting contra position, thank you for sharing. Can you explain a bit what makes it non-typographical in the cases that you cited -- for example, Shakespeare's First Folio? I'm really not familiar with those works, so I don't really understand where this delineation between typographical-versus-some other meaning lies. Mukkakukaku (talk) 18:38, 30 August 2016 (UTC)
 Neutral Were I benevolent dictator of Wikisource, I'd delete it in a heartbeat. Ultimately, however, there seems to be enough people interested in keeping it for certain works that it seems in the spirit of community to keep it for limited cases. I would, however, encourage there to be notes about how it should only be used for very limited instances.--Prosfilaes (talk) 21:17, 30 August 2016 (UTC)
Neutral Were I benevolent dictator of Wikisource, I'd delete it in a heartbeat. Ultimately, however, there seems to be enough people interested in keeping it for certain works that it seems in the spirit of community to keep it for limited cases. I would, however, encourage there to be notes about how it should only be used for very limited instances.--Prosfilaes (talk) 21:17, 30 August 2016 (UTC) Comment We have had a doctrine that the first and significant contributor for a work sets the style (where it is reasonable and practicable for a style to be set within our guidance). I would rarely look to use "long s" template as it is somewhat awkward. That said, if someone wishes to use it, and it falls into the acceptable range and where they are doing the bulk of the transcription (not one page of transcription sets the standard). — billinghurst sDrewth 07:37, 31 August 2016 (UTC)
Comment We have had a doctrine that the first and significant contributor for a work sets the style (where it is reasonable and practicable for a style to be set within our guidance). I would rarely look to use "long s" template as it is somewhat awkward. That said, if someone wishes to use it, and it falls into the acceptable range and where they are doing the bulk of the transcription (not one page of transcription sets the standard). — billinghurst sDrewth 07:37, 31 August 2016 (UTC)- Comment this early manuscript transcription seems to be more a concern over at http://folgerpedia.folger.edu/Early_Modern_Manuscripts_Online_(EMMO) and http://www.nationalarchives.gov.uk/palaeography/where_to_start.htm
- we tend to do more printed reference works with an OCR. yes, defer to contributor style, don’t see a reason to systematize style. Slowking4 ‽ RAN's revenge 15:39, 1 September 2016 (UTC)
- This is not a manuscript issue; the first 324 years, give or take a few, of English printing was done with the long-s. Generally only works printed in the 19th century on will lack the long-s; we used in English longer than we've been without it.--Prosfilaes (talk) 20:14, 1 September 2016 (UTC)
- so imagine what? that early printing was a simulacrum of the manuscripts? i guess if the fine scholars at the national archives have some proofreading notes, then maybe we might want to take a look at them. just before we reinvent the wheel, and edit war among fewer and fewer inmates. but have no fear, if it becomes like wikinews here, we can always turn to the other transcription projects, where there is adult supervision. Slowking4 ‽ RAN's revenge 22:38, 1 September 2016 (UTC)
- This is not a manuscript issue; the first 324 years, give or take a few, of English printing was done with the long-s. Generally only works printed in the 19th century on will lack the long-s; we used in English longer than we've been without it.--Prosfilaes (talk) 20:14, 1 September 2016 (UTC)
- Comment I'd prefer instead of discouraging its use (and by extension things like {{ae}} and {{oe}}), it be allowed to stay, but with each use of these character templates replaced by the corresponding Unicode within the source of the pages through some back-end MediaWiki mechanism. This would also necessitate a bot having to go around and replace each instance of, say, {{f}} with U+0192 in the original source of existing pages. Mahir256 (talk) 03:15, 2 September 2016 (UTC)
- I don't think there is a "by extension" here; the cases are quite different. I believe the fundamental question here is whether we convert {{ls}} to s and stop worrying about the long-s, not how we record the long s.--Prosfilaes (talk) 06:17, 2 September 2016 (UTC)
- The community has already decided that Template:long s is an artefact template, and only displays in the Page: namespace only. It transcludes to being normal ess in main namespace. Those other templates are only helper templates to display those characters that are still existing in modern literature, though are hard to type on a standard keyboard, and prior to the newer toolbar. — billinghurst sDrewth 11:39, 2 September 2016 (UTC)
- I don't think there is a "by extension" here; the cases are quite different. I believe the fundamental question here is whether we convert {{ls}} to s and stop worrying about the long-s, not how we record the long s.--Prosfilaes (talk) 06:17, 2 September 2016 (UTC)
- yeah but, deprecating templates? wow, what next - deprecate Template:Ye or template:sidenote ? maybe we need a filter preventing anyone using a deprecated template ? it is a particularly bitey way to interact with editors. here’s a thought - if people want to transcribe early books with lots of palaeography and custom templates, why don’t we let them? Slowking4 ‽ RAN's revenge 13:47, 2 September 2016 (UTC)
- Because we only have one transcription of each edition of the book. An idiosyncratic transcription that makes it hard to edit can block us from having a usable copy of a work, even if there's enough editors who want it done. A transcription whose output is hard to read can be worse.--Prosfilaes (talk) 18:07, 2 September 2016 (UTC)
- Oppose Normally I do not reproduce long s because it adds more work on my end, does not add any meaning, and it makes documents more difficult for the average user to read. However, I don't see any reason to not allow others the option. I have come across an exception, however. I recently proofread a page dealing with orthography in which display of the long s as well as ligatures are required for the text to have meaning. While long s is encodable, unicode does not encode many ligatures and I am not sure how to ensure that readers will see them. This is also a concern if there were to be automated removal of ligatures or long s's, or automated replacement of them in transclusion to the main namespaces.--T. Mazzei (talk) 17:51, 2 September 2016 (UTC)
- ſ will appear in mainspace; {{ls}} appears as s, which should be an s in mainspace. That page is cutting close to the edge where you might want to use images instead of letters; I'm particularly worried about the Old English showing up right. On the other hand, that's also at the point where images might look a lot worse than text. I don't think there's any perfect win on stuff like that no matter what we do.--Prosfilaes (talk) 18:14, 2 September 2016 (UTC)
- Oppose While I agree it is an absolute pain to include and proofread long s, the general first rule of proofreading is "Don't change what the author wrote!" (Project Gutenberg). This includes typographical standards. So as a rule the primary copy should be true and have long s and that an annotated copy be produced (by bot?) with long s converted to s. There are cases where I have thought I would be willing to proofread but for the long s, but present policy is that the original must be produced first… Can long s be an exception to this policy? — Zoeannl (talk) 05:47, 3 September 2016 (UTC)
- @Zoeannl: There is no (zero) expectation that "long s" should be used on a work. Some users wish to utilise it, and there is scope that the community has within the style guidelines. If you have an old work that you wish to reproduce, and you don't like long s, then don't use it and transcribe it normally. — billinghurst sDrewth 08:26, 4 September 2016 (UTC)
- This has never included typographical standards for Project Gutenberg, who historically normalized to ASCII plain text files. In general typographical standards are the responsibility of the typesetter or printer, not the author.
- In looking at professional work, I can't think of a modern reprint that includes the long-s that's not a photocopy, and even around 1900, when you got copies that used the long-s and weren't photocopies, they were facsimile copies, where the line breaks and every aspect of the original typography was preserved. People who care about the long-s look at photographs of the original work, not transcriptions. In the broader, non-English world, academic reprints will frequently drop the original script; Gothic is transcribed in Latin script, and Phoenician is transcribed in modern Hebrew script.--Prosfilaes (talk) 19:28, 3 September 2016 (UTC)
- all the standard setting is fine, until it turns off the rare book librarians who have set up their own transcription projects. wikisource then becomes a reference garden to support wikimedia only. but we will be able to link to the rare books at wikidata "sum of all books" Slowking4 ‽ RAN's revenge 15:31, 6 September 2016 (UTC)
Wikinews
- @Slowking4: As an aside, what is the problem with n:? —Justin (koavf)❤T☮C☺M☯ 03:06, 2 September 2016 (UTC)
- it is a failed wiki. it is a news site where journalism professors will not edit. m:Wikinews/Worst cases; m:User:Slowking4/the Wikinews scenario see also [20] slide 57. Slowking4 ‽ RAN's revenge 03:20, 2 September 2016 (UTC)
- @Slowking4: As an aside, what is the problem with n:? —Justin (koavf)❤T☮C☺M☯ 03:06, 2 September 2016 (UTC)
- I really think it better if we don't rag on another Wiki here. It hurts our community as a whole if editors who work on Wikinews or whatever project can't come here without feeling attacked.--Prosfilaes (talk) 07:06, 2 September 2016 (UTC)
- Agree, please take those conversations to either wikinews or meta where they are within scope. — billinghurst sDrewth
- oh, this is not "ragging". this is scenario planning. asaf does the ragging. i’m linking to the discussion on meta.[21]; [22] here’s the scope: wikisource like wikinews is a small wiki; we all might learn some lessons from failed small wikis; we might want to do the exact opposite of actions taken there.Slowking4 ‽ RAN's revenge 11:59, 2 September 2016 (UTC)
no red lines when proofing a page
Ever since I updated to the Windows 10 Anniversary update yesterday, the misspelled words and typos are not showing up as underlined by red, and this hampers my proofing majorly. Anyone know of a way to fix this, and/or having this problem too? I am in Microsoft Edge now. - Tannertsf (talk) 14:12, 31 August 2016 (UTC)
- Fixed. - Tannertsf (talk) 14:35, 31 August 2016 (UTC)
New job
Hi all, I just thought I'd say hullo from my new WMF account—I've just started work with the Community Tech team. Very excited to be able to devote full-time to Wikimedia; I'll be keeping proofreading to my own account and after hours though! So far, I'm not 100% sure what I'll be working on, but to start with it looks like it'll be tackling task T142768. —SWilson (WMF) (talk) 04:46, 1 September 2016 (UTC)
- And, just to confirm, my personal account is User:Samwilson. :) —Sam Wilson 04:50, 1 September 2016 (UTC)
- Welcome to a world of pain. May it be (proportionally) minimal.
- In other words: may you most strenuously strive not to stuff up. (Not that I am hoping you to fall short.) AuFCL (talk) 04:57, 1 September 2016 (UTC)
- Thanks. Well, I'll do my best! Let me know if I'm going awry. SWilson (WMF) (talk) 05:37, 1 September 2016 (UTC)
- hope you toasted your new digs at the SF wikisalon last night - i hear they have refreshments. Slowking4 ‽ RAN's revenge 15:32, 1 September 2016 (UTC)
- @Slowking4: Would've loved to have gone, but it's sadly a bit of a long way from Western Australia! :-) Maybe next month. Sam Wilson 00:50, 4 September 2016 (UTC)
Unofficial Wikimedia Discord server
There is now an unofficial server for Wikimedians/Wikisource contributors on Discord. This new chat server provides a useful means of communication to discuss issues and to communicate with other editors more conveniently.
Reguyla (talk) 14:04, 5 September 2016 (UTC)
- Interesting idea. Not sure I quite see the point though. For anyone who's wondering, it seems like Discord is some sort of group voice-communication system. Proprietary and closed-source. Not quite sure how it beats Skype or Google Hangouts, let alone the open-source Mumble. Anyone have experience with it? I'm happy to be convinced. Sam Wilson 06:06, 6 September 2016 (UTC)
Latest tech news from the Wikimedia technical community. Please tell other users about these changes. Not all changes will affect you. Translations are available.
Recent changes
- Word-level diffs now work in longer paragraphs. [23]
- Interactive maps now have a frame by default. This is to make them look like other multimedia objects. This affects all Wikivoyages, the Catalan, Hebrew, Macedonian Wikipedias and Meta. [24]
- When you preview the MediaWiki:Captcha-ip-whitelist page it will show a validation output of the listed IP addresses instead of the list of addresses only. This can help you to identify if your whitelist rules will work or not. [25]
Changes this week
- You will be able to use
<maplink>on all Wikipedias. It creates a link to a full screen map. [26][27] - Sometimes when you mention another user they don't get a notification. You will be able to get a notification when you successfully send out a mention to someone or be told if they did not get a notification. This will be opt-in. [28][29]
- The new version of MediaWiki will be on test wikis and MediaWiki.org from 6 September. It will be on non-Wikipedia wikis and some Wikipedias from 7 September. It will be on all wikis from 8 September (calendar).
Meetings
- You can join the next meeting with the VisualEditor team. During the meeting, you can tell developers which bugs you think are the most important. The meeting will be on 6 September at 19:00 (UTC). See how to join.
Future changes
- The CheckUser extension could work differently in the future. There is a Request for Comments to figure out how. [30]
Tech news prepared by tech ambassadors and posted by bot • Contribute • Translate • Get help • Give feedback • Subscribe or unsubscribe.
17:12, 5 September 2016 (UTC)
RevisionSlider
Birgit Müller (WMDE) 14:56, 12 September 2016 (UTC)
Latest tech news from the Wikimedia technical community. Please tell other users about these changes. Not all changes will affect you. Translations are available.
Recent changes
- The Wikimedia Commons app for Android can now show nearby places that need photos. [31]
<maplink>and<mapframe>can now use geodata from Open Street Map if Open Street Map has defined a region and given it an ID in Wikidata. You can use this to draw on the map and add information. [32][33]
Changes this week
- The RevisionSlider will be available as a beta feature on all wikis from 13 September. This will make it easier to navigate between diffs in the page history. [34]
- A new user right will allow most users to change the content model of pages. [35][36]
- The new version of MediaWiki will be on test wikis and MediaWiki.org from 13 September. It will be on non-Wikipedia wikis and some Wikipedias from 14 September. It will be on all wikis from 15 September (calendar).
Meetings
- You can join the next meeting with the VisualEditor team. During the meeting, you can tell developers which bugs you think are the most important. The meeting will be on 13 September at 19:00 (UTC). See how to join.
Future changes
- When you search on the Wikimedia wikis in the future you could see results from sister projects in your language. You can read more and discuss how this could work.
Tech news prepared by tech ambassadors and posted by bot • Contribute • Translate • Get help • Give feedback • Subscribe or unsubscribe.
18:04, 12 September 2016 (UTC)
Missing customized editing toolbar
Have any changes been made recently? I have not used my customized toolbar for a time, and it is missing in Page and Main namespaces. Also, zoom buttons are present, but do not make changes when clicked. @Ineuw, @Beeswaxcandle:? Thanks, Londonjackbooks (talk) 21:48, 12 September 2016 (UTC)
They seem to be back as of now. Zooming works too. Londonjackbooks (talk) 01:18, 13 September 2016 (UTC)
Gone again, back again. Unstable. Londonjackbooks (talk) 01:21, 13 September 2016 (UTC)
- @Londonjackbooks: I am looking at your common.js toolbar setup and it was programmed by GOIII over a year ago, and the same setup did not work for me anymore for awhile.
- The important settings for you to check are and post here as follows:
- In Preferences \ Gadgets \ Interface, this first option must be selected.
- Site: General utilities needed by the templates and portals of this wiki project.
- In Preferences there are two toolbar related options. Which ones are selected?
- Show edit toolbar or Enable enhanced editing toolbar — Ineuw talk 03:30, 13 September 2016 (UTC)
- Thanks for helping... I have Enable enhanced editing toolbar checked of the two. Londonjackbooks (talk) 03:44, 13 September 2016 (UTC)
- @Londonjackbooks: What about the Preferences \ Gadgets \ Interface, this first option must be selected.
- Site: General utilities needed by the templates and portals of this wiki project. please make sure it is also selected.
- Also, I copied your setup into mine so I see what you "should" see. Please look at this uploaded screen shot File:Ljb setup.jpg is this what you seeing - or not? I took this picture from your earlier work of today. Please open this page in edit mode and compare it to the image and let me know the difference. — Ineuw talk 03:58, 13 September 2016 (UTC)
- Please ignore that the layout is over / under and I can switch that to side by side if that is your layout. I am only interested in the toolbar options and the character insert bar position. — Ineuw talk 04:02, 13 September 2016 (UTC)
- @Londonjackbooks: Perhaps this image is closer what you (should) have? File:Ljb setup 2.jpg. — Ineuw talk
{kind=link}
{kind=link}
- @Ineuw: Sorry, yes... "General utilities & etc." is also selected. Your screenshot (#2) is what I should be seeing, and once in a blue moon it appears; but more often than not (as currently), I am getting the default(?) toolbar. Londonjackbooks (talk) 04:08, 13 September 2016 (UTC)
- Log out of your browser (Chrome?) and all Wikisource related browser cookies should be deleted. They hold user info. I believe you are using Chrome. If you need help with Chrome just post here. You need to log in with newly typed and selected info. — Ineuw talk 04:14, 13 September 2016 (UTC)
- @Ineuw: Deleted history, cookies, etc. (Chrome), logged out, logged back in again, signed back into WS, and things have not changed in edit mode. Hoping I didn't err in following instructions. Just to add, if it is late where you are, we can resume this at a later time... perhaps moving this to my Talk page if it gets too lengthy here... Londonjackbooks (talk) 04:26, 13 September 2016 (UTC)
- @Londonjackbooks: Don't worry, my evening just began. :-) I will continue this on your page now. — Ineuw talk 04:30, 13 September 2016 (UTC)
- @Ineuw: Deleted history, cookies, etc. (Chrome), logged out, logged back in again, signed back into WS, and things have not changed in edit mode. Hoping I didn't err in following instructions. Just to add, if it is late where you are, we can resume this at a later time... perhaps moving this to my Talk page if it gets too lengthy here... Londonjackbooks (talk) 04:26, 13 September 2016 (UTC)
- Log out of your browser (Chrome?) and all Wikisource related browser cookies should be deleted. They hold user info. I believe you are using Chrome. If you need help with Chrome just post here. You need to log in with newly typed and selected info. — Ineuw talk 04:14, 13 September 2016 (UTC)
- @Ineuw: Sorry, yes... "General utilities & etc." is also selected. Your screenshot (#2) is what I should be seeing, and once in a blue moon it appears; but more often than not (as currently), I am getting the default(?) toolbar. Londonjackbooks (talk) 04:08, 13 September 2016 (UTC)
Open call for Project Grants

Greetings! The Project Grants program is accepting proposals from September 12 to October 11 to fund new tools, research, offline outreach (including editathon series, workshops, etc), online organizing (including contests), and other experiments that enhance the work of Wikimedia volunteers. Project Grants can support you and your team’s project development time in addition to project expenses such as materials, travel, and rental space.
- Submit a grant request or draft your proposal in IdeaLab
- Get help with your proposal in an upcoming Hangout session
- Learn from examples of completed Individual Engagement Grants or Project and Event Grants
Also accepting candidates to join the Project Grants Committee through October 1.
With thanks, I JethroBT (WMF) (talk) 14:50, 13 September 2016 (UTC)
Copyright question with due diligence but still unsure
Would this be in the public domain?
Conqueror of the Seas
Author: Stefan Zweig (1881-1942) 74 years
Published 1922 in German in Austria
Translated to English 1938
by Cedar Paul (-1972) 44 years
Recent publication date 2007-03-15
ISBN-10: 1406760064 ISBN-13: 9781406760064
But don't know the publisher. I have an .epub version. The web is full of advertisements but no one has it in stock except Amazon.com selling/advertising the 1938 translation.
—unsigned comment by Ineuw (talk) .
- Original Austrian version would be in public domain. The translation's status cannot be assessed on the presented evidence. Where was it first published? Did it have the requisite components for copyright? If it was published in US was its copyright renewed? etc. — billinghurst sDrewth 23:58, 14 September 2016 (UTC)
- That says
- Authorship on Application: Samuel Howard Sloan, 1944- ; Domicile: United States; Citizenship: United States. Authorship: text in Foreword and on the back cover.
- Pre-existing Material: photographs, artwork, original text by Stefan Zweig and translation by Eden & Cedar Paul.
- Basis of Claim: text in Foreword and on the back cover.
- i.e. this new edition of the book has new stuff that has a new as of 2010 copyright. The original would have had to be renewed 28 years after publication, or around 1966, for a valid renewal. For renewals prior to 1977, you need to check something like http://www.gutenberg.org/ebooks/11800 or http://collections.stanford.edu/copyrightrenewals/bin/page?forward=home . Unfortunately, according to those, it was renewed in 1966, R376873.--Prosfilaes (talk) 02:11, 15 September 2016 (UTC)
- @Prosfilaes: Like minds research alike. :-) In the 1966 list it was renewed by Viking Press. In essence we checked the same lists. Between 1994 and 2010, it was in the public domain. I am pursuing this issue to expand my knowledge about copyrights and perhaps challenge the 2010 renewal. There is a question of the legality of renewal due to the book's 1994 end of copyright protection, and the renewal date. — Ineuw talk 20:52, 15 September 2016 (UTC)
- Works published between 1923 and 1977 that were properly copyrighted and renewed have 95 years of copyright from initial publication. Only the initial copyright lasted 28 years; the renewal lasts 67. A 1938 work with a proper renewal will leave copyright at the end of 2033.--Prosfilaes (talk) 02:48, 19 September 2016 (UTC)
- @Prosfilaes: Please re-read the details at the beginning of the post. I don't question you knowledge of the law, but in this particular case the math is wrong.
- First of all the book was published in Austria in 1922 in German. So, the copyright has lapsed according to Austrian law (Author's death + 70 years)
- The English translation was copyrighted in 1938.
- Viking Press renewed the copyright 28 years later in 1966, which according to you would return it to the public domain in 2033, but, the book was issued a renewal in 2010.
- This means that the book had to be in the public domain for some strange reason.
- It was also published by a (phantom) publisher in 2007 and interestingly the book had an ISBN number. I saw the book offered on the web by a number of booksellers listing this 2007 version for sale, but when I tried to order, it was nowhere available. Several places advertised a secondhand copy of the original 1938 publication, but when I tried to order that, again it was not available.
- If your 67 year renewal is correct than the copyright still belongs to Viking Press until 2003. But, I believe that it was in the public domain. Based on this, I asked a copyright lawyer and was told that it's very rare for a public domain book to get renewed copyright protection, so I plan to write to the US Copyright Office. I also noticed that there may be a crucial error in the 2010 copyright. What do I have to loose but time? :-) — Ineuw talk 06:06, 19 September 2016 (UTC)
- Ineuw, you need to separate the copyright of the original German version which has expired, and the 1938 translation which has not expired, and as Prosfilaes indicated it has 95 years copyright. So anyone can now freely re-translate the German version, but they cannot utilise the published translation. — billinghurst sDrewth 08:12, 19 September 2016 (UTC)
- Billinghurst, I am not considering the German original as having anything to do with the US copyright. I just laid out the chronology of the known events that passed. The fact that someone else copyrighted it while the copyright was supposedly owned by Viking Press made me wonder. Finally, I am less interested in the outcome, and more interested in the process. I already have a copy of the book. — Ineuw talk 09:25, 19 September 2016 (UTC)
- Please re-read the details I posted at the start of this post. Namely that the registration says: "Pre-existing Material: photographs, artwork, original text by Stefan Zweig and translation by Eden & Cedar Paul. Basis of Claim: text in Foreword and on the back cover." The work was not issued a renewal in 2010; "text in Foreword and on the back cover" was issued a new copyright in 2010, which can always be done when there's a new forward and cover added to an old text. It's possible he got a license to print a limited edition, and it's possible he thought the work was PD. That's neither here nor there; all that says is that we can't copy the foreword or back cover of the new edition, but the body text probably has the same copyright rules as the original.--Prosfilaes (talk) 20:04, 19 September 2016 (UTC)
- yes - "the book was issued a renewal in 2010." + "This means that the book had to be in the public domain for some strange reason." -- beware. publishers may do strange things like blanket renew copyright, or even make false claims. this seems clearly renewed to me, and there are plenty of other orphans in the sea. Slowking4 ‽ RAN's revenge 12:26, 28 September 2016 (UTC)
┌─────────────────────────────────┘
Thanks for the input. I already wrote to the US Copyright office. I will post their response. — Ineuw talk 01:45, 29 September 2016 (UTC)
Two page format issues
1. The word "WIKISOURCE" in the logo at the top left of this site seems to have had the bottoms of all the letter shaved somewhat. (checked in safari & firefox). Is that just me, or do we like it this way?
2. In my (empty) watchlist, the "Sister Projects" heading and the list of sister projects are in a large font ... again, just me or some issue? --Tagishsimon (talk) 13:29, 16 September 2016 (UTC)
- I don't see anything amiss about either the logo or the sister projects on the watchlist, in Firefox 48. Does the issue remain if you log out? —Beleg Tâl (talk) 13:40, 16 September 2016 (UTC)
- I don't see anything wrong with the logo logged out with Chrome (vector). I do see an issue with vector and watchlists (FFx), the fonts are big. — billinghurst sDrewth 15:26, 16 September 2016 (UTC)
Petscan and subpages
Following a request to Magnus, will be adding the capability to Petscan: to work with subpages — on the "other sources" tab — ruling them in or out for queries. This works well where we want to differentiate between root level and subpages. This will help when we need to work with needing to plug entries into biographical works into Wikidata. @Jura1: to this update. The change is viewable at https://petscan-dev.wmflabs.org — billinghurst sDrewth 15:41, 16 September 2016 (UTC)
Do we have HathiTrust access?
Do we have users who have full HathiTrust access? There's some works I've found on HathiTrust that I'd like to get pulled, but I'd rather not have to download them a page at a time.
(Also, is the appropriate place to ask for someone to pull stuff from HathiTrust on the WS:Requested texts page?)
Thanks, Mukkakukaku (talk) 19:38, 19 September 2016 (UTC)
- Some here have HT access. The other option is that WMF has organised library access to people to certain firewall services, so it may be that if there are things that you are specifically after that it may be possible to coordinate. We could go over there an ask. — billinghurst sDrewth 00:29, 20 September 2016 (UTC)
Latest tech news from the Wikimedia technical community. Please tell other users about these changes. Not all changes will affect you. Translations are available.
Problems
- Last week's MediaWiki update was rolled back because of bugs. Creating new accounts did not work between 15 September 19:10 UTC and 16 September 12:50 UTC. [37][38]
Changes this week
- The new version of MediaWiki will hopefully be on test wikis and MediaWiki.org from 20 September. It will be on non-Wikipedia wikis and some Wikipedias from 21 September. It will be on all wikis from 22 September (calendar). This is the version that was meant to go out last week.
Meetings
- You can join the next meeting with the VisualEditor team. During the meeting, you can tell developers which bugs you think are the most important. The meeting will be on 20 September at 19:00 (UTC). See how to join.
- You can join the next meeting with the Architecture committee. The topic this week is multi-content revisions. The meeting will be on 21 September at 21:00 (UTC). See how to join.
Future changes
- Wikidata will start working on adding support for Wiktionary. The Wikidata development team is now taking one last look at the development plan. [39]
Tech news prepared by tech ambassadors and posted by bot • Contribute • Translate • Get help • Give feedback • Subscribe or unsubscribe.
22:08, 19 September 2016 (UTC)
Latest tech news from the Wikimedia technical community. Please tell other users about these changes. Not all changes will affect you. Translations are available.
Recent changes
- If your wiki wants numerical sorting in categories you can request it after a community decision. See how to request it. [40]
- When you edit text and mention a new username they are notified if you add your signature. Before this only happened under certain conditions. [41]
- Users are notified if they are mentioned in a section where you add your own signature even if you edit more than one section. Before, users were not notified if you edited more than one section in one edit. [42]
Problems
- The MediaWiki version that was supposed to come to the wikis two weeks ago was put on hold again because of new problems. The MediaWiki version after it is now on all wikis. [43][44]
Changes this week
- There will be no new MediaWiki version this week. [45]
Meetings
- You can join the next office hour with the Wikidata team. The meeting will be on September 27 at 16:00 (UTC). See how to join.
Future changes
- Abandoned tools on Tool Labs could be taken over by other developers. There is a new discussion on Meta about this. It will be discussed until 12 October and then voted on. [46]
Tech news prepared by tech ambassadors and posted by bot • Contribute • Translate • Get help • Give feedback • Subscribe or unsubscribe.
18:07, 26 September 2016 (UTC)
Grants to improve your project
Greetings! The Project Grants program is currently accepting proposals for funding. There is just over a week left to submit before the October 11 deadline. If you have ideas for software, offline outreach, research, online community organizing, or other projects that enhance the work of Wikimedia volunteers, start your proposal today! Please encourage others who have great ideas to apply as well. Support is available if you want help turning your idea into a grant request.
- Submit a grant request
- Get help: In IdeaLab or an upcoming Hangout session
- Learn from examples of completed Individual Engagement Grants or Project and Event Grants