Latest comment: 13 years ago1 comment1 person in discussion
It is currently 10:40, 12 June 2011 (UTC) , voting closes at 23:59 UTC, so just hours after this post. If you want to vote, please do so. Additionally, there's been an on-going discussion about a recommendation for voting to be extended to give people more time, opinions welcome. --Alecmconroy (talk) 10:40, 12 June 2011 (UTC)
Wikimedia Foundation Request for Comment
Latest comment: 12 years ago2 comments2 people in discussion
You may be aware of the English Wikipedia's blackout to protest the proposed U.S. legislation Stop Online Piracy Act and PROTECT IP Act and the Italian Wikipedia's protest of the proposed Italian legislation DDL intercettazioni. The Wikimedia Foundation wants to know whether the Wikimedia community is willing for it to join an organization called the Internet Defense League, which has the professed aim of coördinating more such protests. Unfortunately, the Foundation representatives only directly notified that part of the community that is on the English Wikipedia. ☺ The RFC, on Meta, is hyperlinked above.
Thanks for informing people about the RfC. Just a quick remark that it is not true that "the Foundation representatives only directly notified that part of the community that is on the English Wikipedia" - this was posted on Wikimedia-l (formerly Foundation-l), quite the usual venue for such issues, and on the "Wikimedia Forum" on Meta. Regards, Tbayer (WMF) (talk) 15:11, 29 June 2012 (UTC)
Help decide about more than $10 million of Wikimedia donations in the coming year
Latest comment: 12 years ago1 comment1 person in discussion
(Apologies if this message isn't in your language. Please consider translating it)
Hi,
As many of you are aware, the Wikimedia Board of Trustees recently initiated important changes in the way that money is being distributed within the Wikimedia movement. As part of this, a new community-led "Funds Dissemination Committee" (FDC) is currently being set up. Already in 2012-13, its recommendations will guide the decisions about the distribution of over 10 million US dollars among the Foundation, chapters and other eligible entities.
Now, seven capable, knowledgeable and trustworthy community members are sought to volunteer on the initial Funds Dissemination Committee. It is expected to take up its work in September. In addition, a community member is sought to be the Ombudsperson for the FDC process. If you are interested in joining the committee, read the call for volunteers. Nominations are planned to close on August 15.
Latest comment: 12 years ago1 comment1 person in discussion
Aubrey from it.WS has started meta:Wikimania 2012 Wikisource roadmap. It is currently consists of the rough notes from the WM Unconference session, other Wikisource presentations from the conference, and random points that came up at dinner; but the idea is to work out the true roadmap for development work. Some of these things were already in development (OAI-PMH generator), some would be a bit over the horizon regardless (anything with Wikidata). I would really encourage everyone to not only look this over, but to ask questions and add your own thoughts. I think just keeping up the conversation between the Wikisources about deveploment will be beneficial itself. But I think we need a roadmap if we are going leverage Wikisource into some the projects external devs are working on. We could get some of our items into Summer of Code next year. I was particularly encouraged to consider this option as an answer to some of our requests. With a roadmap written we should be able to turn some of the gaps into coherent proposals for next year's program. Please share you thoughts at the Meta page.--BirgitteSB00:28, 31 July 2012 (UTC)
Proposals
Remove "Excerpt or Mixture" from the index Level of Progress options
Latest comment: 13 years ago8 comments3 people in discussion
As a very brief background, I initially wanted to add selections to the Level of Progress field; as works that are excerpts are getting marked as done, which has led to some confusion. As an index, they are done, but they are essentially indices that are incomplete. After speaking with Billinghurst some days ago, he changed my view on the matter, and I believe that it does not belong in the group "Level of Progress." However, I think that we need to create a separate field simply for keeping track of what the index is in relation to its original publication. I would also like to propose adding another field to classify works simply as "Complete publication," "Excerpt of publication," and "Mixture of publications" or something along those lines. - Theornamentalist (talk) 23:04, 13 May 2011 (UTC)
I agree that your 'confusion' point may exist but not sure the progress field is the root or cause behind it (have you ever looked at how many works have an excerpt or mixture status? Eleven total).
I'd think the limited choices in the Type field at the top is more of a misleading catalyst than any proofreading progress level. Maybe the volume field should not appear by default unless there are in fact other volumes, parts, sections, years, ongoing series/collections, etc. being provided or listed that do exist, and are pertinent, but unfortunately not included along with the particular scan in question for whatever reasons? This way, in selecting some yet-to-be-defined-new-choice-for-type, it becomes more clear that the Index is just an excerpt or a mixture(?) of some other body of work or works -- independent of its status regarding level of proofreading. George Orwell III (talk) 23:40, 13 May 2011 (UTC)
I've seen those few, not highly used. Regarding the "Type" field, I'd agree. In fact, there are many times where I simply look at the options and think "none of the above;" that probably should be expanded too. As a larger proposal, I think the qualities which we seek yet lack can be fixed by:
I think that this can solve the issues we have; in the short term, I think we can remove #3, and maybe add #2, and discuss how to properly expand #1 to capture the variation of document type correctly. - Theornamentalist (talk) 00:35, 14 May 2011 (UTC)
I would agree that removal of the choice "Excerpt or Mixture" from the Progress list should be done, that said, it is has not seemed largely problematic at this time. That said, there is some peculiarity to the page, so we should hasten slowly.
The Index: pages are something that needs the community's attention and discussion for "where to" from here. The Index: pages host data and ideally metadata that ties our works together in many places, they have the potential to be a data reservoir, and to better interconnect metadata. I suppose I have a preference for a root and branch discussion with the sky as the limit about what are the possibilities in this space. I would like to someone with librarian skills involved for the data that we should be collecting, and how we can best collect and present metadata. I would also like to see a programmer involved in how the data of an edition can be added at Commons, presumably in {{book}} or a successor if that is inadequate, the data collected for the Index: page, and then be available for wherever it could be (dynamically) used around the site. I have no expertise in this space, I just see the possibilities to make it the intersection of a whole set of data. — billinghurstsDrewth00:59, 14 May 2011 (UTC)
Not that I have any expertise in the area either but I've come to clearly understand a thing or two nevertheless in my limited readings to date. Neither the BibTex bibliography system nor the PDF DocInfo metadata standards are being followed to any degree or with much consideration when it comes to the embedded metadata keys normally found in .djvu and/or pdf files aligning to its like-parameter in the Commons template(s) (or approaches?) mentioned just above.
It would be a shame if we don't capitalize on any data that already comes embedded in the various file formats at [Commons] upload and even better if we can further refine info while the file is being hosted on WS due something as silly as parameter naming or syntax. Don't have a course to follow on this and don't have the skills & knowledge to address this either but I thought better to raise the point than let it fall through the cracks in an ignorant silence. George Orwell III (talk) 01:37, 14 May 2011 (UTC)
I am going to try and clear the excerpt/mixture category. I also see the problem that an index listed as "Source file problem" is typically one which is missing pages, or, in essence, and (unintentional) excerpt. Another point of confusion. In loo of the complete overhaul and metadata, I think we can improve some things in the index for now. - Theornamentalist (talk) 14:16, 14 May 2011 (UTC)
After clearing the category, one which was primarily filled with works by one contributor who is somewhat inactive, I deleted the option from the drop down list in the Mediawiki page, as well as its navigation in the {{Index Progress}} template. - Theornamentalist (talk) 17:57, 15 May 2011 (UTC)
Latest comment: 12 years ago37 comments5 people in discussion
The Title and Author fields of a page in the main namespace of Wikisource are currently rendered within an HTML table which only uses CSS classes to distinguish them. Most search engines (e.g. Google) will give no more weight to these than the rest of the text of the work. Consequently a search for author or title does not give good recognition.
I would propose that these fields are rendered using an h1 and/or h2 html tag. The css styling can be adjusted to make the appearance identical to current practice if desired, though I would suggest that they could be slightly more prominent. This would immediately improve the Google rating on all Wikisource articles. Note that Wikipedia currently uses h1 for its titles. Chris55 (talk) 10:19, 28 June 2012 (UTC)
I support any means to enhance search engine ranking and prominence, but the web page titles of our articles are in line with Wikipedia practice (h1). If possible, could you please create an example of how you visualize this? — Ineuw talk15:35, 28 June 2012 (UTC)
Ok, I agree the main header has an h1 header which will in most cases be the same, though I don't know whether that is checked. But most articles in Wikisource have an author which is almost as important as the title. It's crucial that the author field is given a header tag - this is what makes it different to Wikipedia. Whether both the fields generated by the header template should be h2 or just the author field, I'm open. Chris55 (talk) 16:15, 28 June 2012 (UTC)
Looking at different types of article, these two main headers have different content. Sometimes the author is only in the first along with the title, other times the "author" field contains a subsidiary title. In the case of DNB the structure is yet another variant. But in all cases they need a header tag to help search engines spot them. Chris55 (talk) 08:40, 29 June 2012 (UTC)
Don't mean to be argumentative, but I fail to see the point in giving the author the same prominence as the article title when authors have their own pages. I also don't see anything wrong with different header styles as long as they are consistent within the series. After all, each book we work on is different. If you look at the PSM article headers, they are just another variation which work well, providing a versatile set of navigational links suitable for a publication. Also, Google displays all namespaces, regardless of our given prominence. What is of more importance to me, is understanding how searches interpret disambiguation pages. — Ineuw talk18:30, 29 June 2012 (UTC)
Ineuw, I made the point in the section #Reform Month 2012 that if you search for a work using a search engine such as google, you'll find it on archive.org, Google books or Gutenberg (if it's there) but you won't find it on Wikisource. Have you ever been involved in promoting a website? Well, Wikisource fails, unlike Wikipedia, which is always up there on the first page. Now maybe this is of no concern to you and it doesn't reflect the 10M visitors it gets every month but it seems to me that we'll never get a better support community (70 active compared with 24,000 on Wikipedia) unless we make Wikisource a bit more visible.
And the primary reason it fails must be because it doesn't make the author name as well as the title visible to Google, which primarily takes account of headings rather than the main text. Most titles consist of common words which are not themselves notable. The example I picked, pretty randomly, was "Why men fight". Only the last word is even slightly selective in Google, and that not highly. And it's not untypical of the titles in Wikisource. Names are highly selective. I'm not suggesting changing the look of the page just the underlying html. Maybe you are happy that Wikisource is invisible. I'm not. Chris55 (talk) 21:54, 29 June 2012 (UTC)
It depends a little on the author in question. If you search for Lovecraft (our top author) you will often see Wikisource listed on the first page. Anyway, do search engines care about header levels? I was under the impression the interlinks were more important. So Wikipedia, which is virtually made of interlinks and is widely linked across the internet, scores highly while we, much less interlinked and directly competing with older and more established sites like Gutenberg, score less. - AdamBMorgan (talk) 23:14, 29 June 2012 (UTC)
I thought it failed because its only 1 chapter of 8 total, untouched since ~2009 and had no sub-title inclusive redirect until I added one just a few minutes ago. Not a good example, imho, just because its incomplete to begin with and had 3 years to fall to the wayside on Google by hits to sites hosting the complete text. -- George Orwell III (talk) 23:50, 29 June 2012 (UTC)
I would suggest that the case of Lovecraft is exceptional and even then it is only the Author record that appears on p1 of Google. Certainly links to Wikisource are crucial - and there's a chicken and egg situation there. People don't know about Wikisource and so don't put links to it. So one first has to make it rather more visible before that effect will come into play, and the method I suggest will go some way towards this. But all search engines care about header levels, even Google. (see e.g. p20 of this) In response to GO3 I'd say, pose another more typical query. I tried several and had very little success. Chris55 (talk) 09:14, 30 June 2012 (UTC)
All I meant there was that title given is a poor example. I don't disagree that there are many examples that do prove your point but one must also accept that many others can be brought to disprove your hypothesis at the same time. In general, I feel there is little rhyme or reason to resulting search-positioning that can be traced back to anything being done in our current formatting or leveling of "header" information (including the author). -- George Orwell III (talk) 10:35, 30 June 2012 (UTC)
Commenton title/header theory -- Other than being spelled correctly and/or fully, I don't think the title (or the proposed author changes) make any difference to Google's search algorithm. Take Executive Order 13526, redefining the way the government handles classified information, for example. Issued and posted on WhiteHouse.gov December 29, 2009, I had it up here on WS within a day or two and a full 5 days before the first official publication in the Federal Register & the many copies to follow from various organizations, etc. It was the top result on Google if not near the top for at least the year that followed (2010) thanks to various geopolitical events taking place at the same time, making the Order timely & relevant over and over and over again well into 2011, with the latest spike coming as a result of the ongoing WikiLeaks saga. Some ToolServer measurements even had it ranked as high as 3rd most viewed article on WS at the end of 2010 - bouncing along near the top well into 2011.
Search for it today on Google - the Whitehouse.gov site rightfully comes up first being the first to post it, Wikipedia is somehow listed second behind them and for the next thirteen pages or so the Wikisource listing has become nonexistent. At that point, you have to scroll down, click on Google's In order to show you the most relevant results, we have omitted some entries very similar to the 258 already displayed. If you like, you can repeat the search with the omitted results included message and presto - Wikisource is back on page one & at number 2 once again - well before the CIA, Dept. of Defense, the National Archives and Records Administration and every other entity that is remotely concerned with classified information and the way the government handles it, including Wikipedia.
The point I'm trying to illustrate with the above example is that it is my belief the issue at hand lies more with Google and the way they filter "us" rather than anything we are doing (or not doing?) here locally on WS. Title was not the issue in the above, the authorship was never a factor in the above nor was the amount of traffic the work was (and still is) receiving - Filtering is. This ties also into another recent discussion concerning search results and the Author: &/or Portal: name-spaces producing poor/inconsistent results when it came to search engines in my opinion as well. Those name-spaces or prefixes should be automatically discarded under any WikiSource domain when it comes to search results.
Bottom Line; someone who actually gets a paycheck from the Foundation needs to liaison with his or her counterpart at Google to revamp this filtering/name-space problem to automatically better reflect the content being hosted here in their search results. Trying to "bend" one way or the other here on WS in hopes it will accommodate the immovable on-line force that is Google - one who, it seems, isn't really paying us much attention for whatever reason as it is anyway - just doesn't seem like a workable or worthwhile endeavor in this case for me. -- George Orwell III (talk) 01:38, 30 June 2012 (UTC)
I totally agree with GO3's final suggestion. But I would be very surprised if that person doesn't agree with me. No way am I suggesting that this is an instant fix. It's just one no-brain improvement. Clearly a scoop such as that mentioned does a lot more to increase the visibility of WS, but in that case the effect was not sustained as shown by the viewing figures (see right). The challenge is to make the titles on WS as visible as, say, Google Books (with the assumption that Google are prevented from rigging the answer). But that will take a lot more than this one improvement. Chris55 (talk) 09:29, 30 June 2012 (UTC)
You're right, I don't disagree with your premise that there is a problem here one bit. I just don't believe your solution of adding author (or any other) info under additional header tags, be they based in our basic template here locally or generated from the template skin for the main namespace by default, will make any difference to the search results - past observations and previous contributor interactions does not support that. Adam's point on intra- & inter-linking seems to provide better support for the desired improvement in result positions in my view as well.
Plus, past research (albeit sketchy from Alexia) has shown roughly only a third of the users first landing on a WS article originate from [Google] search results. The other two-thirds are evenly split between Wikipedia click-ins and from other Wikisource pages themselves (Tracking WS "traffic" has been pretty bad to date no matter how one tries to spin it; red-headed step-child comes to mind).
I agree something should be done to improve result postioning but I don't believe it is anything "we" here locally can accomplish. At the same time, I do believe we can improve overall visibility by better Wikilinking to relevant works/authors and/or sister domains whenever possible. We don't want to over-annotate works by introducing dozens and dozens of interlinks so the net gain will still be only a slight change in visibility if at all however. The cards seem to stacked against us in this matter. -- George Orwell III (talk) 10:20, 30 June 2012 (UTC)
Your argument that only a third of visitors come from Google could easily be construed against you. Why are most referrals "internal"? I took a few more random titles and one was instructive. "Eight cousins" turned up on p8 of Google, but when I tried "Eight cousins Alcott" I didn't find it in the first 50 pages. Yet the author is there on the page all right and is a complete work unlike the one I started with. I am glad to say that in the course of my random checks I did find some that came up on page 1! Far be it from me to suggest they are really obscure (tho most didn't include an author name;-)
I have other suggestions for improving WS visibility but most of the arguments I've heard against this one seem to be fatalistic - we can't do anything. I can't make this change myself as I don't have access to templates or the experience to do it. But it's a pretty elementary step to acknowledge that many people search for a title with an author and if that actually prevents them finding it on WS then it's not a good thing. Chris55 (talk) 18:11, 30 June 2012 (UTC)
I think you're still mistaken a bit to what is possible here locally. In order for the header template or any of its info fields to become "elevated" in relation to the content that may or not follow, the default skin generated from the servers needs to be modified so that you can still add/edit the header template manually in the textbox in edit mode but becomes First Heading upon save. Right now - no matter what you type in the text box, it will not change the article title one bit (that's why you need to move an article to rename it anytime after its first created). I'd have no problem with "moving" or manipulating the the header template & its info to behave that way via the default skin but the idea that its something 1-2-3 that can be done easily (even if 100% of the community decides it wants to) is simply not the case. -- George Orwell III (talk) 18:52, 30 June 2012 (UTC)
Well I've done a very simple hack to a copy of the header template used at User:Chris55/Sandbox3 which illustrates what I mean. I'm sure the styling is not yet acceptable and I used h3 to avoid the rules that h2 generates, but it suggests that it is possible to get something which Google will work on. I notice that you've made many changes to Template:header so you're not saying that that is not possible and I've never suggested changing the h1 header. I'm a bit bemused why you think it's not possible. Chris55 (talk) 10:02, 1 July 2012 (UTC)
Sorry if I haven't been clear. I didn't mean to say it is impossible to "do" just that it is impractical (look at your sandbox again) to apply across the entire mainspace spectrum and ineffective in achieving the desired results as far as search engine association or results go. Making something a header or positioning those headers one after the other seems after-the-fact to me is all. Its the all info before we get to anything found in the Body tag that needs "improvement" (imho). -- George Orwell III (talk) 11:04, 1 July 2012 (UTC)
Well you're clearly determined not to do this so I'm not sure whether it's worth continuing. I suppose your change to the example was intended to show that the structure of pages would be impacted by default-generated contents boxes. I've just looked up 100 random pages in the main namespace and only 1 page had such a generated list; the structure of Wikisource does not encourage it or depend on it. And I suppose I am not allowed to mention __NOTOC__. Chris55 (talk) 15:46, 1 July 2012 (UTC)
Sorry. I'm conviced there are better options than this one (for now) but I don't speak for everyone in the community either; only myself. I'm OK with going this route if the consesus winds up in your favor. -- George Orwell III (talk) 16:25, 1 July 2012 (UTC)
After some trial and error, I have been able to determine that the following css code will hide the first TOC entry only on mainspace pages:
One additional consideration is that the numbering is not modified, so we would possibly want to also add:
.ns-0 .tocnumber { display: none !important; }
which would remove TOC numbering altogether (in the mainspace).
I believe it should be OK to hide the first two TOC lines on all mainspace pages, because we require {{header}}, which will generate those two headers every time. --EliyakT·C17:15, 1 July 2012 (UTC)
Author pages
I believe I have identified a fix for author pages, at least. Compare the Google search for "Tolstoy" to the search for "author Tolstoy". The reason the second one shows WS as the #3 result while the first search does not have the correct page in the first 100 results would seem to be because author pages have an "Author:" prefix! We can actually change this by using the DISPLAYTITLE magic word as described here and setting $wgRestrictDisplayTitle = false . (then a slight change will need to be made to {{author}} to utilise this feature). This may also help with "<author> <work>" searches, since the author page links to the work pages, and will have a better pagerank for that author's name. I am not sure about that, but there is one way to find out... --EliyakT·C05:39, 1 July 2012 (UTC)
It's my understanding that the webpage address does not change, only the page title displayed on the WS page. I think that the text for a wikilink will be the same as before; i.e. it will not match the displayed page title, which is the same as the <title> text (displayed on the top of web browser windows and as the first line of Google search results). There is no issue with an address not exactly matching a title in terms of SEO. --EliyakT·C08:41, 1 July 2012 (UTC)
I'm a bit skeptical only because it is the real title that matters when it comes to externals such as Google; not the displayed title we "see" here and rely on locally. The fact the displayed title currently mirrors the real title is only by chance & thanks to the universal WG setting you pointed out preventing the full blown changing of it by Users:. I suspect it won't matter whatever it is we force to display here locally as long as the real title still contains the namespace prefix we'd like to see "hidden" for external search result purposes. Again, I believe its the skin that is generated by default via the severs when called that needs modification so external entities such as Google drop Author: and Portal: from their formulas but still understand enough to display them in their displayed results.
Another possible modification we may want to make to the <title> text is to include " - Wikisource, the free library," like WP does. This could have some value in terms of "brand recognition." --EliyakT·C08:41, 1 July 2012 (UTC)
It's there - its just hidden from displaying by CSS or scripting (I forget). Go to any transcluded mainspace work and click on printable view from your side menu. You should still see its counter-part "From WikiSource". Restoring that is a whole other can of worms because elements of dynamic layouts' containers (as well as the simple proofreading status bar table) "load" into the div spans that are normally reserved for banners, site notices, bylines and things similar to your brand tagline in order to get around the lack of a text edit field dedicated div container at the time of early PR development. This has since been rectified so there is no need to intrude up into those blocks & spans anymore but I can't anyone who knows the ins and outs of the extension to modify it. -- George Orwell III (talk) 10:07, 1 July 2012 (UTC)
Google uses the "real" title, i.e. the text in the <title> tag, as the title line in search results. That's what I meant about branding. Also, as far as I can tell, on WP, which uses $wgAllowDisplayTitle (but with $wgRestrictDisplayTitle = true) the <title> text reflects the DISPLAYTITLE text. I have no reason to believe it would not behave the same here, or could not be made to. See http://www.google.com/search?q=ebay for an example. The WP search result uses the modified title (lowercase e). That's exactly what we want here. Also, to clarify, I would like to see " - Wikisource, the free library" in the <title> text, but not displayed on the page itself. --EliyakT·C15:25, 1 July 2012 (UTC)
Hey, you've convinced me its worth trying - all I'm saying now is that the Magic Word solution might not be the Magic Bullet by itself - additional tweaks still might be beneficial (if not required) to get this to work both so we don't have to search using author Tolstoy and still get Author:Tolstoy in the results.
An alternative would be to get Extension:HideNamespace installed for author (and portal?) namespaces. I am not sure what that involves, and if it is harder to implement than the DISPLAYTITLE solution. At any rate, it would avoid the problem of users having the ability to change titles to anything they desire (though I'm not sure we need to worry about abuse from such an experienced user who would know about the magic word!) --EliyakT·C15:52, 1 July 2012 (UTC)
The tagline should be back in play now (some browsers will display it in their banner bar along the top before the browser name). Don't know how long that takes to filter through Google and the like. I hope nothing relied on that field to cleanly pull the page title or similar, but its just as easy to undo if something is now "broken". -- George Orwell III (talk) 16:43, 1 July 2012 (UTC)
... in fact - I can use that same [MediaWiki:Pagetitle|message field] to "hide" the Author: namespace-prefix in the underlying <title> tag without screwing up the URL. I must be overlooking something. It can't be that easy, can it? -- George Orwell III (talk) 17:42, 1 July 2012 (UTC)
Wow, you did it! That last edit to MediaWiki:Pagetitle accomplished exactly what we need! Above discussion is now moot. Based on some random page caches I checked, we should expect to see changes to the Google results in a week or so.--EliyakT·C17:46, 1 July 2012 (UTC)
┌──────────────────────────┘
Well we did it if anything. If you hadn't mentioned reviving the tagline for advert. purposes, I would have never gone poking around with it on my own in the first place.
Anyway, I'd like to get Portal: into the same mix without making the statement twice as bloated - I just can't think of an easy way to include more than one parameter (the namespace(s) in this case) that must be matched in order to run the "true" value at the moment (brain-fart). Ideas? -- George Orwell III (talk) 18:08, 1 July 2012 (UTC)
{{#ifeq:{{SUBJECTSPACE}}|Author|{{PAGENAME}} - {{SITENAME}}, the free online library|$1 - {{SITENAME}}, the free online library}}
An update: Google searches show that only author pages edited since the change are being shown as anticipated in the results. Apparently Google is hip to this tactic, and only updates pages where the content, not just the html tags, have changed. One option to counter this would be to make a minor change to {{author}}, which should result in Google seeing all author pages as having changed. I am not sure what an appropriate minor change might be, though. Also, the results positions are climbing, it seems to me. It is the display of the individual result that remains the same. --EliyakT·C17:55, 8 July 2012 (UTC)
support, though this is conditional on better linking to the work of the bot as per the bot policy; I am comfortable with this being a link from the user page to the bot's master page. — billinghurstsDrewth04:44, 2 July 2012 (UTC)
Oppose - I see no reason to grant the flag to another person who hardly contributes to en.WS directly in spite of having a "presence" here over the past few months by cleaning up double redirects (something that was handled just as well if not better by the regulars who do contribute here on an almost daily basis I might add). -- George Orwell III (talk) 07:47, 2 July 2012 (UTC)
Can we make this about the tool, not about the person. There are many global bots, and to this point of time we have not chosen to have them. That we have that approach is okay, however, we should then have some civility when one of these operators appears here to ask. — billinghurstsDrewth02:12, 3 July 2012 (UTC)
I apologize if I have slighted or offended 'A Certain White Cat' (the individual User in excellent standing as far as I'm concerned) in any way, but it is hard to separate the individual from the Bot that is being controlled by that individual and the task in question. I've had enough of the merits rightly or otherwise achieved by any contributing individual, be those merits gained here specifically or at other Wikis overall, automatically transferring into the justification for applying specific bot tasks rather than just the opportunity and the benefit of any doubt to prove him- or her-self to the community that the task being promoted is worthwhile or adds value to en.WS.
Yes, in this case the individual obviously knows what they are doing and has the record to prove it - does that automatically mean the task is justified never mind needed and the flag should be granted? Why have a double-redirect list at all if the consensus is to delegate automated corrections of it to a Bot rather than manual per person reviews? Why hasn't anybody made this list obsolete by adding the deletion function right into the Wikicode at the moments after a double redirect is created then?
No, I don't buy the premise the task warrants a flag - good housekeeping done by the person or persons actually "living" in a house is better than contracting the work out to somebody who doesn't really "live" there... what other conclusion should I be arriving at without an autopatroller secured status since 2006 ~ 2007? Did someone forget to pass autopatroller status along through all the account name changes since then? I can't make heads or tails of what previously requested Bot flag ever got granted and under what account name(s) if ever - can anyone enlighten me on those points in spite of my gruffness and stubbornness over this matter (which I apologize for now in advance)? - George Orwell III (talk) 03:32, 3 July 2012 (UTC)
I can provide you with technical information and logic behind double redirect implementation that I know. I'll assume you know nothing about the matter so as not to leave anything out both for you and anyone else reading. I apologize if I somehow sound preachy as that is not my intention.
A double redirect is the case of a redirect pointing to another redirect. MediaWiki is programmed to follow a redirect once and only once to avoid redirects from reaching infinite loops of redirects if these redirects somehow point to each other. This is a navigational hazard to the reader and web crawlers that index websites as the page content will be shown as a link instead of the content of the redirect destination.
MediaWiki software intentionally does not address double redirects because the code does not check for them immediately. This is because immediate tasks to check are too expensive (computer resource-wise) particularly as wikis grow. After all, vast majority of redirects generated will not lead to double redirects. There are infrequent runs (depending on the size of the wiki) which provide the entries list Special:Doubleredirects. With each cycle old entries are removed. Each cycle only reports a certain number of results (between 1000-5000) and additional entries are pruned.
Entries on Special:Doubleredirects will be marked as fixed (with a strike-through) if they are edited after the timestamp of the past list generation regardless if they are actually fixed or not. They will appear as not fixed in the new cycle if they are not really fixed.
The task of dealing with double redirects is shown here. While a Wikipedia page, it does show what the bot does. It is a simple logic really: tedious and mundane. :) Housekeeping-wise it is similar to manually heating the house by adding firewood versus just pressing a button to activate a machine with pre-set conditions for the same task. You will get the same amount of heat but the machine will not only save your time but also use resources more efficiently.
The idea of deleting redirects as they are generated is a philosophical one not shared by everybody. Redirects were programmed into MediaWiki to allow page moves not to break links to pages (including external links). Keeping redirects under normal circumstances do not harm projects while deleting them has the potential to break local and external links using that wiki as a resource.
Thank you for your insight and explanation of double-redirects. My philosophy however does not mirror your's. You were told we didn't have a double-redirect problem when you applied as 'User:Computer' previously and we still don't have a double-redirect problem that would require or benefit from having Bot runs now either. Sorry, find a more constructive task; my opposition to granting a bot flag remains until then. -- George Orwell III (talk) 15:30, 3 July 2012 (UTC)
While I have been inactive recently, I have been active enough here to have worked on the first featured audio recording transcript (be advised language can make sailors blush). I realize this doesn't mean much as I have a very low edit count and I hate "bragging" about my work, however I think it would be unfair to call me a person whom "hardly contributes". Furthermore I do not see what impact my contributions here would have on my ability to operate this bot. My bot has over 23,920 edits to Spanish Wikipedia even though I never contributed there. Not once was there an issue stemming from the bots edits since the task is a mundane and routine one.
I disagree that humans can handle this task better. If 500 pages redirect to a page and that page is moved you would need to update all of the 500 pages that now redirects to a redirect. This has a potential to flood the RC feed. wiktionary:fr:Spécial:Contributions/タチコマ robot can be seen as an example as this happened there on 7 May. All other days you can observe very few edits.
Also bear in mind the nature of WikiSource entries where each WikiSource content tends to have multiple subpages. A random example: Nicene and Post-Nicene Fathers: Series I. Suppose all of those pages were renamed twice... You would have over 5,000 redirects as that work has over 5,000 sub pages. Of course this particular example is unlikely to be moved but there are works with alternate titles and initially chosen name might not be the popular one. Such renames could happen years apart.
You are arguing the use of a 'weapon' the equivalent of a Tomahawk missile to what amounts to a local knife fight. ...and how many double-redirects do we have as of today? ZeRo. Last cycle? tWo. Its very rare to have more than a dozen or two re-dirs on our lists. If we ever let contributors get stupid enough to make 500 or 5000 double redirects; shame on us - we'll call upon someone like you at that point to clean up our mess.
Plus monitoring the lists manually lets us be proactive and reach out to unfamiliar or new editors who have unknowingly made a dozen or so double re-dirs. In the process we manage to identify possible community pitfalls and/or benefits and educate people at the same time they get a chance to review their technique(s). Sorry, results here are not so bad that it warrants another flag for what amounts, imo, another drive-by editor. Come up with a more meaningful consistent task and I'll gladly reconsider. We are not Wikipedia and I don't give a damn what takes place there (hat tip to Spain on winning nevertheless). -- George Orwell III (talk) 17:35, 2 July 2012 (UTC)
Unsure, leaning towards oppose, this sounds like a solution looking for a problem. Why do we need a bot to for a task that does not seem to be a problem? Jeepday (talk) 22:39, 3 July 2012 (UTC)
Can I try to frame this discussion a bit please? — I would like to see a clear, actionable outcome.
Our bot policy provides for bot authorization in two steps:
Authorization to run the bot. At this step we need to consider what the bot does, whether we want/need that functionality, and the potential for harm.
The granting of a bot flag. A bot flag simply allows us to avoid seeing the bot's edits in recent changes and watchlists; so by granting the bot flag, we affirm that the bot can be trusted, does not need close community scrutiny, and we'd prefer not to see its edits. At this step we need to consider the reliability of the bot, and also the extent to which the bot may flood recent changes with many edits.
My understanding is that this bot has been running here without going through Step 1, yet this request is framed as Step 2. But Step 1 authorization cannot be taken as given, so there are three possible outcomes on the table:
The bot is unauthorised and unwanted, and must stop editing here.
The bot may continue editing, but is not granted a bot flag at this time.
The bot may continue editing, and is granted a bot flag.
Forgive me if not being more specific earlier but I'm operating under the assumption that "Step 1" has been approached more than once already over the years (well, at least as far as the need for double-redirect cleaning goes that is) but done but under account name(s) other than the current one(s), both as the operator applying and as the proposed bot name itself, with apparently no success (again, as far as I can tell).
I am having some difficulty in sorting out the exact time-line and the conclusions reached (if any) given those various name changes, account moves, account redirections, etc... and some weird flaw in the archiving of Scriptorium discussions where months in 2011 (May for example) are also holding discussions backed-up from [April, May of] 2012 (and vise versa?).
I'm also certain I took issue with some bot & the handling of double &/or broken redirects once before this iteration started running for the same reasons, which stopped for whatever reason back then, but I can't verify 100% if that instance was with same individual in question now or with somebody else completely :( -- George Orwell III (talk) 06:52, 4 July 2012 (UTC)
I had taken a 2 year wiki break someitme after 2008 which is when I stopped all activity more or less. To be honest I do not remember all of the issues from back then from three years ago. I remember I was told to run the bot without a bot flag but I could be wrong. I was never told to stop my bot so I presume there was no problem with its operation so far. If the community does not want me to run my bot here, I will comment out the line that makes it edit this wiki. My past experience with redirect.py particularly on fr.wiktionary prompted me to consider seeking bot flag even if bot has few edits on that wiki. Bots edit count depends entirely on on wiki activity (page moves/account renames). Bot does not need a bot flag if it continues its current edit patter since its one or two edits in a blue moon but it could be ~200 edits in one day too depending on on wiki activity as I previously explained. I merely want to help this wiki like others. -- A Certain White Catchi?17:25, 5 July 2012 (UTC)
You are more than welcome to run a bot here if the community first agrees to what particular tasks are to be performed by that bot. After a few trial runs, which you obviously should have little trouble succeeding in, the community will come back and vote to grant the bot flag bit or not.
For example, you were basically told back in 2008 "... the following objection 'I would prefer interwiki linkages to be visible on recentchanges, we dont have major problems with Special:DoubleRedirects (and most of those a best fixed by the person who was working on those pages), and I flat out definitely do not want to see another bot doing commons delinking here'.", and I merely echoed those sentiments now. As far as double-redirects go specifically, we have ZeRo double-redirects this cycle once again.
So in closing, I re-affirm the 2008 objections and kindly wish you stop running the bot until you are approved some other task in order to prove it is worth granting the bot flag for runs here on en.WS. Again, I don't give a damn how sloppy other wikis are and how much your bot has helped them out in the past or why; it's all about en.WS and nothing but en.WS as far as this matter goes in my view. -- George Orwell III (talk) 18:36, 5 July 2012 (UTC)
Some people may think that a bot is "the equivalent of a Tomahawk missile to what amounts to a local knife fight" but it seems to me perfect sense to use one to sort out simple but tedious edits such as double redirects. The fact is that it has been doing some good and no recorded harm. Nobody seems to understand the history so why can't we make a simple decision here and now to give a limited approval that will be reviewed at a defined point in the future. The English Wikisource community is far too small and needs all the help it can get. Chris55 (talk) 21:49, 5 July 2012 (UTC)
That's the point - the tasks being cited here are not in any real jeopardy from week-to-week (or even month-to-month for that matter) and that the degree of help bot automation could provide is questionable given that low amount of turnover. Plus, its not unusual though infrequent to go back over the bot's correction(s) and wind up deleting instead of fixing the first redirect incarnation because it no longer conforms to the current naming convention as it is. -- George Orwell III (talk) 22:13, 5 July 2012 (UTC)
I fail to see the point. There isn't a shortage of bot flags. The automation will work flawlessly eliminating double redirects. If it saves everyone looking at the special page once, that is time saved. Bots edits would not hamper your ability to delete unwanted redirects or any other maintenance tasks. If bot makes as many edits as it was doing in the past year, it would be making very few edits anyways. Bot's contribution would also leave you a log of all recent double redirects it has fixed so finding past cases would be easier too. I cannot see any human out preforming a bot in dealing with double redirects. -- A Certain White Catchi?17:52, 8 July 2012 (UTC)
Help
Other discussions
Exit Survey - why I quit
Latest comment: 13 years ago9 comments8 people in discussion
Two users, billinghurst and Cygnis, have repeatedly told me to stop adding works unless I want to upload DJVUs and proofread thousands of pages - when I pointed out I was copying works over from Project Gutenberg and Archive.org, I get passive-aggressive responses about how I'm doing things wrong. Arabia, Egypt, India: A Narrative of Travel got deleted and moved to my userspace because it didn't have a DJVU file, same with Journal of the Gypsy Lore Society/Volume I, etc Something like Gamana-Gamanam, which I listed as "Published in the Athenaeum" and displays a date of July 15, 1879 gets tagged "no source", when I point out that it has a source...the tag gets aggressively slapped back on and I'm told to give a "SOURCE". I don't even know what they want, it is from the 1879 Athenaeum...similar to Journal of the Gypsy Lore Society/Volume II/An Episode from the Life of Sir Richard Burton, naturally I would assume the source to be "Journal of the Gypsy Lore Society's...Volume II? Which I listed...but I have added 21 books, letters and articles by the same two authors, both of whom died more than a century ago, and have been given nothing but grief for it, and being told to mind my own business and go proofread a DJVU of the Month instead because that would be more "useful" to the project.
As I quoted to Billinghurst when he came on my talk page to tell me that my work is "next to useless", despite the fact Author:Isabel Burton went from having zero works...to many works. But I responded to him, stating "I am not certain why you believe that your way represents "the" way, and my way is an aberration. I assume people come here to read the works of Marx, or Goethe, or Burton. And it is best if they can find those works collected here - even if they are *gasp* with pagenumbers strewn about, missing a semi-colon present in the original or OCRed...I would rather find ten letters written by Darwin to his mistress that are improperly formatted, than none. And the entire point of a Wiki is that, over time, things improve. Let's take a work like A glossary of words used in the neighbourhood of Sheffield; somebody added it five years ago and never quite finished it, but he made an excellent start, and sooner or later somebody will come along and decide it's worth ten minutes to complete the work. But if JeremyA had never started it, nobody would ever finish it - and that work would be one step closer to being lost, and never being readily available. Or we can take Catholic Encyclopedia (1913)/Tepic, it is not "backed up" by a DJVU, so I could passive-aggressively slap a "unknown source" tag on it just like people seem to enjoy slapping a "unknown source" code on something titled "June 1896 letter to the London Times"...the source should be bloody obvious from the title, but they see a chance to nitpick, so they take it. And it's a pity that The Thoughts of the Emperor Marcus Aurelius Antoninus was added in a copy/paste format four years ago, but I notice a few months later somebody added a header to it, and after that, somebody fixed the capitalisation, after that somebody else still added the translator's name, last year somebody even started to clean up the formatting. And thankfully, anybody who searchs "The Thoughts of the Emperor Marcus Aurelius Antoninus" will find a copy of it, hosted here on Wikisource...all because many years ago, we welcomed drive-by copy/pastes as "better than nothing", and over time, they have slowly been improved - and maybe 2011 is the year that work will be split into separate chapters to ease page-loading.".
So here is my exit survey, explaining my reasons for leaving the project. Hopefully you can glean something from it about "biting newbies" and perhaps welcoming people who try to help, and offer six hours a day to proofreading, correcting and adding texts to the site, instead of trying to force them to stop adding works. TheSkullOfRFBurton (talk) 22:42, 2 April 2011 (UTC)
Interesting reflections, obviously their opinion, though I do not agree with the substance of the accusations and do not support that the evidence when looked at in its entirety would lead to that conclusion, well not as the accusations that have been laid at my feet.
From a just now review, there seems to have been discussions at User_talk:Inductiveload about their dislike of the djvu system, which has followed with pasting of text form archive.org scans. This community has looked to NOT be a copy and paste environment and looked to present a balance of quality and quantity. We have a workspace, the Page: namespace, that fulfills the area where work can be undertaken to improve them, as we saw that works that were just pasted pretty much stayed that way and were never validated. If there are problems and solutions, then let us have the discussion, rather than just ignore the problems. —unsigned comment byBillinghurst (talk) 04:30, 3 April 2011.
Thanks for this feedback. Personally, I think Wikisource's primary asset is the ability to link directly to page images. If we don't have that, and are just copying text from elsewhere, why would a reader want to use our site instead of the one where the text came from?
That said, I don't think it is damaging to the project to copy and paste corrected text from gutenberg, etc. Uncorrected OCR text I don't see as particularly helpful. So I hope you'll reconsider and keep adding correct text. Even more, I hope that you'll help us make Wikisource better than other online libraries, by connecting text with pages of a djvu file. —Spangineer(háblame)04:40, 3 April 2011 (UTC)
In answer to your question, they'll come if we develop a reputation for being an online, fully available and editable archive. After all, where else can you find it in such an easy to access format. And a printed book is just a click away! People will start saying "Is it on Wikisource?" "No, I just checked." "Strange...Well, I guess we might as well just forget it then." Of course, we might not want to get too overloaded with stuff like the advertisements of the New York Times and such like. Arlen22 (talk) 02:03, 7 May 2011 (UTC)
A prophecy from 2007:
"[M]ost of my earlier contributions had very poor provenance indeed, but over time I imposed higher standards on myself.... I wince when I see Project Gutenberg copy-paste jobs being posted, but if my experience is anything to go by, accepting works of poor provenance may be a price we have to pay to keep bringing newbs through the door."[1]
I am a similar case; in 2008 I uploaded mostly 19th century English prose and poetry, without as much as a link to PG. Despite this, I did not receive any flack, and checking back to my first work here, another user came in and added source without my knowledge. Just over a year ago, I returned to add another work, and received a nice message regarding source information by Cygnis here; I think it will be tough to tell users to not add work without scans as long as we have a majority of works here without them. I did not see page links for nearly all the works I came across when using this site in the beginning and thought that there was absolutely no problem. That being said; I don't think there is an easy transition other than to keep going the way and the pace at which we're going and not bite anyone. - Theornamentalist03:10, 5 April 2011 (UTC)
As a 2008 arrival too, I would say that most of the development occurred after that. 1) Development of the Page: ns (general improvements, text extraction, display means); 2) file size increases at Commons; 3) Gaining inertia, especially through broadening experience. While I prefer not to see PG texts, they are what they are and I have no squabble with them, they have been proofread twice, they usually have no provenance and they are hard to correct. I do have issues with the slap paste of an IA raw text with their intervening header components, with no further work, and then move onto the slap paste of the next raw text ... If there is the wish to build the bibliography based on raw scanned text then do so at the author namespace linking directly to the works at IA with a suitable describer. If it is solely on quantity of works, then we can all do that, and this place would like a giant boil on the arse of a mouse but it won't matter as Google will save us, cross references won't matter because you can just do a CTRL-F find. To me the quality of the product and its accessibility and navigation are also important, our point of differentiation is we can check the linked scans, we can wikilink, we can research and annotate, we can categorise, etc. I will agree with the general philosophy of don't bite newbies, however, some of these newbies are not newbies at all, and they simply do not like a differing opinion, or an a commentary of how the community here has been handling matters. There has to be an allowance for and acknowledgement of quality control, and people putting works onto the site should neither be surprised nor precious that works will have that process undertaken. That is where the biting should not take place in either direction. Differences of opinion are okay, but dummy spits are not.
Why not just tell everybody the eventual truth? Starting one day to come - all works not tied to a scan will be deleted. Period. We can tip-toe around this never-spoken-in-open-desired-goal all we like with one plauseable rationalization or the other, but this will only become more and more unethical the longer we wait to do so, imho. If that won't get folks to stop adding objectionable works here, I don't know what will. — George Orwell III (talk) 08:30, 5 April 2011 (UTC)
Send folks to DocsPal.com or some similar conversion site. They can play EPUB to HTML to PDF to DJVU and back all they like on those sites so they don't come bitchin' over here. If we're going lock out uploading PDFs as well creating books as PDF (which never made sense to me but that is for another day) someone else has to pick up the slack. — George Orwell III (talk) 18:12, 5 April 2011 (UTC)
I disagree strongly with George Orwell III. What Wikisource includes are some unpublished works before 1923. Also every month Sherurcij used to solicit works for a particular author and the Wikisource community would bring in works from all over the Internet to help fill out that author's œuvres. I don't understand this mania for scans. Users can judge for themselves whether a work is reliable enough for their uses by the broadness of a work's use, who uploaded it, the library resource that provided it, etc. If a contributor here feels the work is important enough to receive a check for accuracy or validation, they are free to do so or mark down the text quality rating if necessary. How we can leap from that to that we need to carry out a prejudicial purge of all works that don't have a graphics file attached (for which there is no guarantee for reliability as seen by the .djvu files presented in the Scriptorium), no matter how reliable the website (like Project Gutenberg) or the user who contributed it (like a trusted Wikisource administrator or volunteer) is beyond my comprehension. ResScholar (talk) 06:22, 28 May 2011 (UTC)
Hey, I'm more aligned with your view than you'd think without the Admin hat on and measured just by own personal preferences in a vacuum, but the general consensus the last I heard was that scanned works are the preferred type of work to be added as Wikisource moves forward. Take that in conjunction with what seems to be hush development and push implementation, primarily surrounding dynamic layouts, and its not hard to see where this is all headed. I can't say that I like it much either -- but that's also just my personal preference and subjective observations at work. I didn't think it was ethical to remain complicitly silent just because it happens to serve the consensus at the moment was all. -- 06:55, 28 May 2011 (UTC)George Orwell III (talk)
What to djvu?
Latest comment: 13 years ago6 comments5 people in discussion
Two questions; one specific one general.
Specific Question I have just discovered (I love $5 a bag book sales) that I own a copy of Robin Hood by w:Henry Gilbert (1868–1937) illustrated by w:Frances Brundage (1854–1937) and published by w:Saalfield Publishing. My copy is undated, and there is no listed copyright, the original Gilbert work was published as "Robin Hood and the Men of the Greenwood" in 1912. I have just completed several hours research to write W:Henry Gilbert and am unable to define the copyright status (particularly of the images, the text is pre-1923) though I believe it is all public domain. So the question is do go through the process of DJVU on this work?
If it was published before 1977 without a copyright notice then it is in the public domain. As far as I am aware, this covers the whole book including the pictures. I'd say scan and upload the book, it looks eligible. - AdamBMorgan (talk) 13:33, 7 May 2011 (UTC)
General Question as highlighted in a recent discussion. The digital world is full of electronic scans in varied condition, copy and paste adding them to WS accomplishes nothing. In today's world scanners are everywhere; is it time to up date WS:WWI to limit to additions to djvu (or like) scans unless there is an original published release in electronic format?
There are, of course, the famous problems with djvu doing wrong letters and such like, but I think that anything that is complete or has scans to complete it with should be here. eBooks, well, they're in their own little sphere. Arlen22 (talk) 02:08, 7 May 2011 (UTC)
I think WS:WWI should be amended to put the focus on DjVu, although I would personally want some leeway for non-scan-backed works. Scans are important and will eventually become the only material on Wikisource but there is a lot even amongst the stuff I upload or maintain for which I have not yet found scans or scannable material. Allowing for off-line proofreading should be acceptable if not encouraged. (We will probably need an exception for transcriptions too, as they are technically original to Wikisource as written material.) - AdamBMorgan (talk) 13:33, 7 May 2011 (UTC)
Please let's not make it djvu's or nothing. There is still hope for some PDF incorporation here and there as needed and Londonjackbooks has just recently shown .jpg by .jpg Indexes still get the side by side thing done just as well too. George Orwell III (talk) 14:15, 7 May 2011 (UTC)
Transclusion help
Latest comment: 13 years ago31 comments6 people in discussion
Could someone help me by transcluding page 19 of this index file for me?
I did Index:Page 19... let me know if that's not the page you wanted... It helped to reference a Google Books version in "plain text" mode... copy/paste to the Index:Page and then proofread... Makes things easier... Someone else may want to tweak my font size/formatting... Londonjackbooks (talk) 22:15, 26 April 2011 (UTC)
Right... I just found this here on WS already... Thought someone might be trying to merge the two. Either way, enough on my own plate! Thanks for the heads-up, Londonjackbooks (talk) 22:24, 26 April 2011 (UTC)
I know... That was evident when I started proofreading... But it was still much easier to correct the minor differences while proofreading than to type it all out from scratch! :) Londonjackbooks (talk) 02:51, 27 April 2011 (UTC)
:Hmm... only concern about the text vs. pdf versions on that website is that you have to log in to the site to download the pdf... Not so for the text version. Don't know if that matters? Since the pdf version doesn't explicitly state the same public domain rights as the text version...? Londonjackbooks (talk) I'll be quiet now and stop making a mess of things! :) Londonjackbooks (talk) 03:34, 27 April 2011 (UTC)
@Londonjackbooks. Play away, learn some more ropes. Chasing these down is good for all of us, and assists in the sharing of the knowledge. There is currently so much duplication of many bible components, and they are in a pretty bad way with many incomplete. Most have early origins at WS, and now are showing their age, without scans, some are pastes of scans of archive.org texts and are or should be tagged with {{OCR-errors}} and {{numbers}}. They are ugly. I would encourage looking for original source scans, as we see that the copies of copies is propagating errors, or giving works of poor provenance. — billinghurstsDrewth14:29, 27 April 2011 (UTC)
I went ahead and got a "free account" with that website, and it turns out that their PDF version IS copyrighted after all: "Rights: Copyright Christian Classics Ethereal Library Date Created: 2000-07-09" Page 2 of the Commons pdf file (see link above) differs with respect to rights... Might need to delete the info already transcribed to WS? Londonjackbooksshe who will never be an administrator ;)23:22, 27 April 2011 (UTC)
Update: I found two other websites hosting the alleged "Public Domain" PDF versions of this work (the same version in question at Commons):
About Commentary on the Whole Bible Volume I (Genesis to Deuteronomy)
by Matthew Henry
Title: Commentary on the Whole Bible Volume I (Genesis to Deuteronomy) URL: http://www.ccel.org/ccel/henry/mhc1.html
Author(s): Henry, Matthew
Publisher: Grand Rapids, MI: Christian Classics Ethereal Library
Print Basis: 1706-1721
Source: Logos, Inc. Rights: Public domain. May be copied and distributed freely.
Date Created: 2000-07-09
General Comments: Unabridged and carefully proofed.
Contributor(s): Ernie Stefanik (Editor)
CCEL Subjects: All; Bible; Classic
LC Call no: BS490.H4
LC Subjects: The Bible
Works about the Bible
The PDF version at the referenced www.ccel.org website (presumably the official website), http://www.ccel.org/ccel/henry/mhc1.pdf however, lists the following source/rights info.:
About Commentary on the Whole Bible Volume I (Genesis to Deuteronomy)
by Matthew Henry
Title: Commentary on the Whole Bible Volume I (Genesis to Deuteronomy) URL: http://www.ccel.org/ccel/henry/mhc1.html
Author(s): Henry, Matthew
Publisher: Grand Rapids, MI: Christian Classics Ethereal Library Description:Matthew Henry's Commentary on the Whole Bible is well-known and well-loved. His commentary is aimed primarily at explanation and edification, as opposed to textual research. Comprehensive, this commentary provides instruction and encouragement throughout. Each volume of the commentary comes with its own introduction, helpfully situating it for the reader. Although written in an older style, Matthew Henry's Commentary on the Whole Bible is worth studying and is useful for pastors, theologians, and students of the Bible. Tim Perrine CCEL Staff Writer
Print Basis: 1706-1721
Source: Logos, Inc. Rights: Copyright Christian Classics Ethereal Library
Date Created: 2000-07-09
General Comments: Unabridged and carefully proofed.
Contributor(s): Ernie Stefanik (Editor)
CCEL Subjects: All; Bible; Classic; Proofed;
LC Call no: BS490.H4
LC Subjects: The Bible
Works about the Bible
All information is the same EXCEPT for "Rights" and "Description"—which is not present in the "Public domain" versions... Perhaps the listed Staff Writer should be contacted via the website for clarification? I'll give it a shot tomorrow. If it turns out the piece IS copyrighted, how would I notify Commons? On the work's Talk page? Thanks, Londonjackbooks (talk) 03:02, 28 April 2011 (UTC)
But their PDF version (which I had to log in to view) states otherwise... The above source/rights, etc. statement was copied straight from their version. So there would be question in my mind... Londonjackbooks (talk) 03:13, 28 April 2011 (UTC)
The copyright on the text expired in the 18th century. Every new publication will have a copyright on the production on its production qualities, though the text will still remain out of copyright. So CCEL can copyright THAT pdf file; if they have added commentary or their own bits (ie. not stayed true to the original Henry text) they can claim copyright on their bits. My question and challenge is "Why are we taking text from CCEL? Especially why do want that text when we don't know its provenance? If we want to link to it from the author page, then link to it at CCEL. I can see 8 volumes of the work at archive.org → http://www.archive.org/search.php?query=creator%3A%28matthew%20henry%29%20exposition and if it is that valuable, then grab it and work on it. I am not convinced that we want to be, or should be just grabbing texts just because they are there. What becomes our point of difference, what comes of our quality texts. What is the purpose of the collection and collecting? What is our strength, and what are our features and our benefits? I would much prefer quality and relevance, and a point of difference. Being the biggest to me isn't 'it. — billinghurstsDrewth11:56, 28 April 2011 (UTC)
Agreed, and I personally am biased toward using original source texts... If the version at Commons is copyrighted (and I have emailed the CCEL website along with links to "supposed" online public domain versions of their rendering to see if they are legitimate or not), then it can/should be taken off of Commons (and substituted with one of the archive.org version, perhaps)... I'm just trying to establish the legitimacy of the Commons version for starters. It was uploaded by a user last November who contributed to Commons for a mere 4 days and then disappeared. If it is a legitimate PD version, Commons can either decide to keep it or delete it at their discretion, I suppose... And we can either choose to use it or ignore it! Either way, I won't be contributing to it any more myself as I am here for selfish reasons... I just thought I'd help out with a page (although I should have asked some questions first...), and now feel obligated to look after a matter that has my "fingerprints" on it! @Tannertsf:RE:"I doubt its copyrighted.": I just transcribed the following yesterday, and I think it applies here as well:
"It is elementary when the constitutionality of a statute is assailed, if the statute be reasonably susceptible of two interpretations, by one of which it would be unconstitutional and by the other valid, it is our plain duty to adopt that construction which will save the statute from constitutional infirmity. * * * The rule plainly must mean that where a statute is susceptible of two constructions, by one of which grave and doubtful constitutional questions arise and by the other of which such questions are avoided, our duty is to adopt the latter..."
If the copyright status of a work here on WS is questioned, there can be no room for doubt, for it is a matter that would/could compromise the legitimacy/credibility of Wikisource itself... Londonjackbooks (talk) 12:59, 28 April 2011 (UTC)
One work won't compromise this site at all ... especially if it is a book like this that is by an author who, albeit wonderful, died more than 100 years ago. I'm interested in working on this version, NOT on the Archive one ... this has much better clarity. Its also for a class (im the teacher) where my students will log on and do their share of work on this with my account. That is why I uploaded it as a PDF, not a DJVU. They have to, for the assignment, type it onto the page. - Tannertsf (talk) 14:26, 28 April 2011 (UTC)
I'll wait to hear from the CCEL website to see if the versions-in-question are in fact copyrighted or not. It would not have been difficult for someone to "doctor up" the Rights section of the original PDF and change the wording, and create a "new" PDF file, so we should make sure... As it is, the website states on their Copyright page:
"You may use the text version of any public domain book at the CCEL in any way you please, including republishing it. However, the XML and other versions derived from the XML (all non-text versions) are copyrighted. They may be used for non-profit personal, educational, and church purposes involving fewer than 25 copies of a book without further permission. However, you must contact us for permission to republish CCEL works or to use them commercially." (http://www.ccel.org/about/copyright.html)
The PDF of CCEL sounds like it is copyright and should be deleted. Trivial I would agree, however, it neither meets Commons nor Wikisource's requirements of being in the public domain. Principle is principle, independent of the work, and fair use does NOT apply at either of these sites. — billinghurstsDrewth03:02, 29 April 2011 (UTC)
I still have yet to hear back from them, but as soon as I do (or don't!), I'll be sure to update on here... As for myself, I just purchased, via Amazon.com, a "Gale MOML (Making of Modern Law) print edition" of George H. Earle Jr.'s The Liberty to Trade as Buttressed by National Law (1909). It is one of those BiblioLife reproductions of public domain material (authentic reproductions of the original work)... I would love to put that work on here as well since you can't find it online yet (or at least I can't, or haven't yet), but I'm not sure if I can legally scan the images from the book to upload here. I have emailed BiblioLife Network to see if it is allowed... So I await two responses... Londonjackbooks (talk) 03:43, 29 April 2011 (UTC)
One more question: How specific should I be when stating the source? Would "Scan of facsimile page from a public domain work entitled, The Liberty to Trade as Buttresses by National Law (1909) by George H. Earle, Jr." suffice? Or need I also mention the BiblioLife reproduction stage as well? The original source text was originally reproduced by the Harvard Law School Library, where the orig. text was/is housed... The BiblioLife reproduction also contains a typed signed letter from GHEJr to Prof. James Barr Ames of Harvard Law School, dated Jan 22, 1909 (letterhead of The Real Estate Trust Company of Philadelphia, of which Earle was then president)—is that letter "fair game" too? Sorry, turned out to be more than one question! I'm full of them! Londonjackbooks (talk) 03:42, 30 April 2011 (UTC)
Billinghurst, I disagree strongly with your characterization of CCEL. CCEL has been around longer than Wikisource, proofreads its works, and provides a bibliographical source of every work. Any works derived from them should be regarded as at least 75% on the TextQuality scale. Some people are simply not more suspicious of a work simply because it hasn't been cleared through "Wikisource procedures", which an enterprising forger can circumvent anyway (this is what we are worried about, distorted text, isn't it?). People can judge for themselves by looking at the proofread scale together with the source as to whether they want to trust the validity of the work. One can witness the fine job User:Quadell did with the Ante-Nicene Fathers series if they want an example of their skilled work.
Not my intent to make any characterisation of CCEL's proofreading process. They are what they are. My comment was why bring it here when we can link to it directly where it is. What improvement is going to occur to the work here in an imported format? There are works brought here without reference to their provenance, such that they are uncited works, where there is a trust that has to be applied to the work, and when a challenge is made to the text, we have no real ability to correct or respond. Further, as we now have multiple copies of the same works, the issue of provenance is more important to us (year of printing, edition, country of publishing, ...) From my exploration other sites have one copy of a transcribed work, they do not have multiples. So my point became about what is WS's point of difference, nothing about disparaging other sites. — billinghurstsDrewth
And Billinghurst, I don't understand your appeal that we use Internet Archive text instead of CCEL's proofread copies. If someone here wants to go the extra mile to improve a text's accuracy, wouldn't it make more sense to match and split a CCEL text, so we have two text sources rather than two proofreaders working on one text source? That you are concerned about the possibility of text dumps from CCEL etc. suggests to me we should also be concerned about text dumps from Internet Archive as well, the kinds which never get proofread.
Yes, though again we have provenance issues. Read many of Cygnis's issues with the match and split process due to works of the wrong provenance being match, and noting that the match process is not an exact science. And yes, I do have concerns about text dumps straight from IA, and there is plenty of commentary from me about that process. In short, I don't like it when an OCR'd text from a scan is dumped into the main namespace, it has lead to many poor quality texts and no real ability, especially not an easy ability to improve their proofreading credibility. — billinghurstsDrewth13:29, 29 May 2011 (UTC)
I've said it to Cygnis Insignis before, but I'll say it again: I don't think the interest of Wikisource lies in "embalming" particular editions of text, but by hyperlinking texts that would benefit from it using texts validated through reliable means so that interested users can read and discuss them thoroughly, especially those time-proven to help us understand ourselves, our society and the world in which we live. ResScholar (talk) 05:33, 28 May 2011 (UTC)
"...The vast majority of our books are scanned, OCR'd, and installed on our site. The fact that most of our books are in the public domain means that other sites may have used the same books to create their own legitimate copies.
Having said that, our files our copyrighted. The work that goes into OCRing, scanning, proofreading, converting to XML, etc. -- that work is all copyrighted by CCEL. And, unfortunately, we know that other organizations have used these files without permission.
I don't know if this answers your questions or not....
Blessings,
—K"
Well copyright does not apply for hard work, scanning, proofreading, <blah blah> as they are simply effort, not creative processes, and they can claim all they like, they are not supported by legislation. That said, they do own the copyright to a finished product where they have stylistically created a designed product, eg. the typesetting they apply. — billinghurstsDrewth17:06, 30 April 2011 (UTC)
As mentioned (way) above in this section, the work itself (NOT the CCEL PDF version, but an un-Indexed version) has already been started here on WS at Matthew Henry's Commentary on the Whole Bible... Only part of Genesis is complete; same with other Books of the Bible I browsed through... You might be able to do something with that? The main page's discussion pagedoes use the CCEL website as a source, but if one uses the text version (non-copyrighted version) of the commentary from the CCEL site to perform transclusion, it shouldn't be a problem. Londonjackbooks (talk) 02:29, 2 May 2011 (UTC)
The Sanctity of Marriage: Also, These Filthy Lifestyls
Latest comment: 13 years ago8 comments5 people in discussion
So I made discovery of something quite amusing/, in light of the marriage debate in so many countries, that from 1850-1875 it seems there was a huge debate about whether to allow men to marry the sister of their dead wife. There are probably a dozen books or more on the subject, on Archive.org in English alone and I listed them on my userpage (click below!). I wonder if somebody could help me create a new section on Portal:Marriage for these works and upload the books (I have tried and failed every time), then I am happy to proofread, categorise and format the pages. Movedcolor (talk) 21:08, 29 April 2011 (UTC)
The button for OCRbot is gadgetised, and I cannot remember whether it is default ON or default OFF. Oh, and you probably need to stop using the enhanced toolbar. I am trying to get to understand the new toolbar code, though haven't got their yet. — billinghurstsDrewth16:48, 30 April 2011 (UTC)
Latest comment: 13 years ago3 comments2 people in discussion
Would someone help me find a scan of the Geneva Bible anywhere? I'm interested in working on what would be a MASSIVE project, but willing to do it. - Tannertsf (talk) 02:44, 1 May 2011 (UTC)
OH MY! I'd be willing to try it, but it would be very tough to proofread...long s's and very small sidenotes. Might be good though if I have nothing to do. It would definitely need its own wikiproject. - Tannertsf (talk) 01:00, 12 May 2011 (UTC)
Linebreaks and tables (of content)
Latest comment: 13 years ago4 comments3 people in discussion
When proofreading pages, it is common (and quite useful) to preserve the linebreaks from the printed page. This is fine because single linebreaks in wiki text are treated as white space, while double linebreaks separate paragraphs. But this is different in tables. The first linebreak inside a table cell causes a HTML paragraph separator (<p>) to be emitted. So, is there any way that preserving linebreaks can be combined with tables?
I'm talking about pages like this (1) and this (2), where a single table cell contains text that spans multiple lines. In both of these cases, I gave up on the linebreaks and replaced them with whitespace during proofreading. My current Swedish example (3) is a bit more extreme, and I really don't want to give up on the linebreaks. For the time being, I have put an extra linebreak at the beginning of each table cell, causing extra spacing between table rows.
Apparently, keeping the linebreaks inside a link (as in example 1) will tolerate linebreaks inside table code, as does wrapping the linebreaks inside HTML comments (which gets really ugly). Is there a smarter way? --LA2 (talk) 14:39, 3 May 2011 (UTC)
You could achieve it with html comments. <!-- (at the end of the line) and --> (at the beginning of the next). Alternatively you can use traditional table html that doesn't legacy of the wikicode. BUT with all the coding that goes into tables where people are trying to replicate the formatting, it seems that it just adds levels of complexity, and I believe that we should be trying to simplify that aspect of coding, especially with tables. Our more recent use of {{table style}} has, in my opinion, removed some of the formatting eye burden.
To note that linebreaks are not without their issues, considering hyphenation, wikicoding using single quotes, there application in references, not working in wikilinks, etc. — billinghurstsDrewth12:37, 4 May 2011 (UTC)
There is no such page, there is no such directive either way (it is preference). I remove them too for a host of reasons. The line breaks cause problems in other areas, especially with wikicode, links, refs +++. I find it easier to pull them, and I have less issues — billinghurstsDrewth08:42, 11 May 2011 (UTC)
revert help
Latest comment: 13 years ago3 comments2 people in discussion
I can't delete pages from the computer I'm using at the moment and I'm really not sure about the policy or etiquette about it anyway. For politeness' sake, it should probably need the permission of the editors involved. In the mean time, I've made your disclaimer a little more prominent. - AdamBMorgan (talk) 11:36, 10 May 2011 (UTC)
Latest comment: 13 years ago4 comments3 people in discussion
Hey all,
The inclusion policy for Wikisource says that "[a]ny written work ... published (or created but never published) prior to 1923 may be included in Wikisource, so long as it is verifiable". I was just wondering whether this means all pre-1923 newspaper articles are thus eligible for inclusion, or if there are some special criteria for them, as I have PDF scans of some pre-1923 news articles (NYT and other papers) but The New York Times page doesn't list too many items.
Yes, it includes newspapers. Anything published on or before December 31, 1922 is in the public domain. (In some cases, newspapers printed after this date are also in the public domain but you would need to check individual cases.) - AdamBMorgan (talk) 20:47, 14 May 2011 (UTC)
Is there any special procedure for newspaper articles, then? My PDFs don't have the ability to select text, so I'm guessing they're purely images, and I'm not really experienced on creating Wikisource pages. Fetchcomms (talk) 02:50, 15 May 2011 (UTC)
How many pages of newspaper are we talking about, and what is the quality of the scan? Does it already have a text layer? If the scan quality is sufficient and we are talking about a significant number of pages then what we normally do is to upload the pdf to Internet Archive and they have a derivation process that converts it to a djvu, which we then take over to Commons. If it is a few articles, and you are happy to type, then we can take them in any [Commons] allowable image format, and we can work the files at this end to get them into play. — billinghurstsDrewth14:01, 15 May 2011 (UTC)
ePub and other formats
Latest comment: 13 years ago14 comments6 people in discussion
Having just got an ebook reader, I'd like to download some books, but I'd prefer ePub format to PDF as it's more flexible. I'm surprised not to find a choice of output formats for books. Doing a bit of googling I see there is a Wikimedia extension called ePubExport so it can't be a huge job to provide it.
.djvu is the preferred format here. I don't think there are any plans to bring ePub to the site. Not sure what our policies say, but I have a feeling we don't include those files. - Tannertsf (talk) 19:29, 14 May 2011 (UTC)
They are working on adding .epub and .mobi as options in the book tool. It might be a while before it's implemented (although while looking for more information on that I noticed you'd already posted this request on the meta book tool page as well, so you may get more information there). - AdamBMorgan (talk) 20:41, 14 May 2011 (UTC)
I've sent some "e-friends" of mine to http://www.docspal.com for file format conversions. Its fairly limited but some have found combinations that have worked for them. -- 21:43, 14 May 2011 (UTC)
Thanks for those responses. I'm puzzled by the emphasis on djvu as it's primarily a scanned format rather than a character form isn't it? That's even more constrained than postscript for output. Doesn't anyone use ebook readers?
Adam, the reason I posted here was that I didn't get any response on the other discussion pages. But I'm glad to hear there is some progress. Can I contribute? I'm not a Wikimedia expert but I can turn my hands to many things.
To the last contributor: the vital stage is getting a book output in some convertible format. Neither pdf nor djvu meet that need, though actually my Sony reader will "reflow" some PDFs but I doubt the effect is satisfactory. Chris55 (talk) 12:02, 15 May 2011 (UTC)
Chris55. Our preference for djvu files is more related to how we wish to import our text/works/books, in that we have text on a page by page basis, and allow us to extract a text layer, and to proofread against the image. The text layer becomes liberated (extracted) from the scan once we create the page at Wikisource and that allows us transclude and present the text in a number of forms. The developers have yet to give us an epub and others forms to this point (as above) and we look forward to the days that the techno-literate catch up with our needs.
To note that due to the compression of djvu files, we don't recommend them for extracting the images and ideally we would use the jp2 files, or other quality scans. With regard to you contributing … YES YES YES … we will happily nail you to the floor with a nail gun once you have found somewhere comfortable to sit and play. As always, for newbies we recommend Wikisource:Proofread of the Month or one of the projects as a great place to start with support and example around you. What is your poison? — billinghurstsDrewth13:56, 15 May 2011 (UTC)
Well I thought I made it plain at the beginning of this section that I was talking about output not input. So evidently people can't read questions. I can well understand that it's uneconomic to store full page scans as PDFs or even jpgs - tho I've read the Help:DjVu files page and there seem to be more warnings than encouragement. It also seems that people in WikiSource are not thinking at all about how their product will be used. I did go to the Proofread of the Month but gave up after failing to find any guidance - the first page I tried proofing turned out to have been done already. I may go back. Appropriate help has never been a strong point of WikiX. (I know, I should provide it myself - but actually I don't know how to do at the moment!) Chris55 (talk) 15:06, 15 May 2011 (UTC)
Chris55: Most of the volunteers here are involved only in adding and curating the database of content, not in the technical side of things. We welcome suggestions, but we cannot actually effect a technical upgrade without a lot of whining, moaning, wheedling, cajoling and threatening of various Wikimedia developers (who do not hang out locally), and whole ton of waiting. Most extensions are stuck in "review limbo", waiting for a dev to OK them for use on Wikimedia Foundation wikis (including Wikipedia and Wikisource). As a community, we are seriously lacking in output formats, and it is a recognised problem. However, there is nothing most of us can do about except file bugs and annoy devs, which some of us have been doing.
If you would like to help, one thing you can do is research the matter and work out the best way to move forward. There is a lot of things you could find out through the wikimedia-tech mailing lists and IRC channels. You can also work on on-wiki systems for organising and curating a collection of generated files, however that would work. A good way to get to know the WS system (there is a lot to it under the surface, which can make it hard to get going) is to come and say hello in the IRC channel (#wikisource on freenode.net).
Personally, though I do recognise the importance of improving our outputting options to reach a larger audience, I don't have must interest in ebooks, not having an ebook reader, so I am not well acquainted with the current situation. Inductiveload—talk/contribs16:20, 15 May 2011 (UTC)
Hmm, I can understand why the techies don't hang round these parts, but I'm surprised there's no easier way of asking questions. I've looked at the mailing lists archives but they're not even searchable as far as I can see so there's no practical alternative to subscribing and asking questions that have probably been thoroughly explored previously. Techies aren't normally very approachable in such circumstances. But I'll see what I can do. Chris55 (talk) 11:42, 16 May 2011 (UTC)
Mailing lists, IRC, forums and bug trackers are the "traditional" support mechanisms for open software efforts, where the main devs are often working on it part-time or as a hobby. The only major difference with wikis is that we trade the forums (fora?) for a wiki-style page, with the same kind of effect. The reason "techies" can be not very approachable is that they often have their own priorities (this is a hobby for most, remember) and so people can feel sidelined. Short of becoming a dev yourself or providing bounties on features you want, the best you can do is ask nicely and hope a kindly dev has time and care for it.
We do have some semblance of effort towards providing ebook support, and some users (such as Billinghurst) know more about it and actively ask for dev involvement than others (such as myself). I hope we haven't come across as prickly: I'm just trying to address your questions the best I can. This is one of the things many users want, and progress on the technical side has been slow and, for some, I dare say frustrating. This is compounded by the use of a third-party book-generating extension, which doesn't work with our newer toys like the ProofreadPage extension.
If you decide to get involved in WS (and I hope you do, new blood is always great) and especially the technical side, you will see that the system is not geared to fast progression for the smaller wikis (i.e. other than Wikipedia or Commons), or for "esoteric" functionality. We have around 330 active users at the moment, which is about 500 times fewer than en.Wikipedia, so I do understand the development focus on the big boys, from a numbers perspective. Cheers --Inductiveload—talk/contribs00:54, 17 May 2011 (UTC)
┌────────────────┘ I asked the question at the wikitech mailing list, and they pointed to a level of discussion where there has been some consideration (no link provided) to it being included in mw:Extension:Collection. On having a further look at this matter, I do see that someone has written mw:Extension:EPubExport which we may be able to get someone to comment upon from the developers' point of view. — billinghurstsDrewth10:23, 17 May 2011 (UTC)
That's encouraging. If I understand it right, the facility exists in wikimedia to add an "export as ePub" link in the left hand column. So what is needed is to get the wikimedia maintainer for wikisource to add the appropriate mantras to the local settings file. How does one (a) get agreement for that (b) get it done? Chris55 (talk) 11:30, 17 May 2011 (UTC)
Not quite that simple. Just because someone has created an extension for use with the mediawiki application does not mean that the powers that be at Wikimedia will allow the extension onto their servers. They look to make sure that extensions do not have security issues, and that the extensions are not unreasonable on available resources, eg. hogging cycles on servers if numbers of people look to use the tools. Then we have to know that it is functional for our intended use, etc. I have asked the question about how and where to have the extension considered and how to get it tested and it was indicated that to add it to bugzilla was a start, so I have logged it at bugzilla:29023, I have addressed it to one person with influence, and we will need to wait a week or so to see if there is interest. Anyone who has something to contribute in terms of functionality, ideas, or as a "vote" (for what they count) can do so at the link. — billinghurstsDrewth12:00, 17 May 2011 (UTC)
I expected that getting agreement would be the major part of the process. The point that Brian Vibber makes on bugzilla is quite valid: of the two methods of outputting, the book creator method is obviously the more important. But the method needs some adaptation for Wikisource. It seems odd that to download a book with say 14 chapters one needs to go through a construction process with 15 or 16 steps. At the very least every completed book should have an entry under Books/ yet there are currently less than 30 there. But having done that for one example, the system refused to produce a PDF for me saying it was overloaded; entirely justified: the process should be done at most once for every revision of a book. But there seems no provision for caching the output.
So if Wikisource is to be useful, some more thought needs to be put into how completed books are stored for download. I had hoped that it would be in the long run an alternative to Gutenberg or the Internet Book Archive but in its present form it wouldn't work. Chris55 (talk) 15:24, 17 May 2011 (UTC)
Hi folks, if you're looking for a way to easy create ePub files, on it.wikisource we (mainly User:Alex brollo and me) are working on a tool that does it. This tool reads the index of contents that is usually present in a text's main page, builds the entire tree of chapters, gets every page of that text, gets images, styles, and what is needed, and finally packs everything up in an ePub which is also readable off-line. The idea is that you just click a single button in a ns0 page, and you get the epub with the complete text of all chapters, period. It's nearly finished, if you want to take a look, come to our place and we can show you some demos. See you soon! :-) Candalua (talk) 17:52, 22 June 2011 (UTC)
DNB content not showing
Latest comment: 13 years ago1 comment1 person in discussion
I fixed that example [2]. I think when the page was saved it tried to convert the old section tags to the newer one, <section begin=Saravia. Hadrian à/> to ##Saravia. Hadrian à##, but got muddled when the name of the section was the same as the first line of the text. CYGNIS INSIGNIS16:44, 16 May 2011 (UTC)
I don't think it's dead per se, just dormant (or not completely agreed yet). I suspect this is mostly down to a lack of interest in policy approval rather than extreme resistance to the concept (it remains on WS:WWI). I'm still doing it and (getting it wrong) in places and I think others are too. I mostly just add wikilinks myself, and only recently realised that this counts as annotation and needs to be separated from the main copy. I'm not sure that wikilinking should count as annotation but I'm working on a template to account for this. These "added value" items, such as translation (and technically grangerisation may count too), are one of Wikisource's USPs. So, we should have documentation but this is lacking in a lot of other areas too. - AdamBMorgan (talk) 11:49, 17 May 2011 (UTC)
I don't like the idea of wikilinks being considered annotations. In something like Gresham College they add significantly but are effectively invisible. IE. the text isn't changed at all to the reader. 76.117.247.5503:20, 18 May 2011 (UTC)
I like adding wikilinks now and again as well. Where is the best place to read about whether to add such things or not? The ones I want to add are links to the journals and scientists mentioned in 1922 Encyclopædia Britannica/Sound, and also to the author as well. Also, there are references to other EB 1922 articles, and I presume it is OK to link to those, even if they are redlinks and not yet done? Carcharoth (talk) 17:09, 21 May 2011 (UTC)
I was going to link to the Wikipedia articles, but I think (from reading what you pointed me to), that is it better to see if a wikisource page exists first, and to then link to that, or link to a redlink. I will try and do that now. Carcharoth (talk) 18:25, 22 May 2011 (UTC)
History Periodicals
Latest comment: 13 years ago4 comments2 people in discussion
I hit save too soon! The periodical is called "Translations and Reprints from Original Sources of European History" published by "The University of Pennsylvannia". Using those as search terms, there are even more on the archive. Bound editions of volume 1, volume 2, volume 3, volume 4, volume 6 (I'm not sure what happened to volume 5). There's also the somewhat similar "Readings in Modern European History" in volume 1 and volume 2. - AdamBMorgan (talk) 20:20, 18 May 2011 (UTC)
Latest comment: 13 years ago3 comments3 people in discussion
I just merged Portal:Religious texts and Portal:Religion and realised that we have parent portals/classifications on the left-side, so we really need to list child-portals on the right-hand side of the header. So that Portal:Christianity and Portal:Judaism have a place to fight, and then from Portal:Christianity it shows Portal:Anglicanism, &c. Anyone able to add that field to the header? I don't mind going around updating portals - it'll make navigation much nicer. StateOfAvon (talk) 01:18, 18 May 2011 (UTC)
I've been listing child portals in the body so far. Putting a list inside the header will, in some cases, stretch the header badly (possibly filling all or most of the screen). Currently, Christian Denominations, Political Institutions and Public Administration of the United States, General Literature and Botany have the most children but this list is likely to increase over time. We could possibly create something like a Wikipedia infobox to sit outside the portal on the right but this might mess with the formatting of some portals (such as Portal:American Civil War or Portal:Science, the latter of which technically does this anyway). Still, such an infobox could contain the entire hierarchy (parent, children & gradchildren if applicable). - AdamBMorgan (talk) 09:24, 18 May 2011 (UTC)
I would agree that child portals should be listed in the body along with directly-linked texts. In some cases you might want to make the portal links bold to stand out. In some cases I also link directly to one or two of the most significant works from the child portal; for example one might link directly to Bible from Portal:Religion, even though it is also linked from Portal:Christianity. - Htonl (talk) 11:19, 18 May 2011 (UTC)
Slow page loading
Latest comment: 13 years ago11 comments5 people in discussion
Is it just me, or has the whole page loading process slowed down to a crawl? Makes editing very difficult for me. Mattisse (talk) 16:38, 18 May 2011 (UTC)
I also had a lot of speed problems in proofreading. It seems to me that the server handling the .djvu pages has slowed down considerably. Today, it seems a little better.— Ineuw talk08:49, 19 May 2011 (UTC)
It has been terrible for weeks. Large pages in particular either will not save, or they will but you won't know it because the server won't serve you the results. Hesperian04:29, 20 May 2011 (UTC)
Same problem here. This is coming from someone with a limited understanding on web browsers, but here is the gist of my efforts to improve the loading and saving. Even though I use Windows XP SP3 with FF 4.0.1 and a standard high speed 5mb internet connection, this may help others. My above comment in this post (on the 19th) was made after removing all cookies (there were hundreds) and started fresh. This made a dramatic difference, but didn’t mention it because of wanting to see the subsequent days’ results. Now, after two days, again ended up with the same problem, so removed all unknown cookies, and again loading and saving speeded up to normal. I just don’t know how (and why) cookies affect the Wikipedia servers. I hope this helps.— Ineuw talk11:56, 20 May 2011 (UTC)
Guess my idea is not entirely successful. For the past two days the server has slowed down to the point where I just gave up proofreading. Is anyone else with this problem? Is there a known issue with the server(s)?— Ineuw talk01:00, 24 May 2011 (UTC)
I find that an occasionally a page image will stall on loading. I just save the page, and then look to re-edit, and the second time it works okay. — billinghurstsDrewth12:05, 24 May 2011 (UTC)
Thanks for both posts. The virus protection settings were incorrect and now it’s much better. Also, I did occasionally save the page as billinghurst suggested, but refrain from doing it too often. Now, I don’t expect problems.— Ineuw talk15:59, 24 May 2011 (UTC)
Can you email me with details or what the problem is and how to fix it please, because I am still stalling horribly on big pages. Hesperian05:48, 25 May 2011 (UTC)
Is it normal for Category:Easter or Portal:Holidays to link to userpages? Why can I not add public domain works from the Popular Science project, proofread and uploaded properly? I have added thirty works from Popular Science, and now they are just being tagged for speedy deletion and moved to talkpages and for three days I have no answer from the people deleting them even though they keep deleting them...eight more were deleted this morning. I am starting to think that the small number of contributors I see on Recent Changes is not a sign of a strong positive environment, but of an elitist environment that alienates new members and shoves them aside!
This is beyond bad taste - all my hours of work are wasted for no reason, historical works are removed from their prominence and everything, and I promise I am not wasting more on this. StateOfAvon (talk) 18:50, 19 May 2011 (UTC)
I agree that these should be subpages... but I disagree with moving them into userspace just because the volume skeleton doesn't exist yet. They are works and have as much right to reside in the mainspace as any other. Having them under the article title in the interim does no harm to our mission whatsoever; on the contrary, it is a better outcome. Hesperian00:13, 20 May 2011 (UTC)
I am going to revert for now. Discussion can continue here, and if the consensus is to userfy, then fine. But in the meantime, StateOfAvon is offended, and I think s/he has good grounds for that, and I don't want to let things stand as they are. Hesperian00:17, 20 May 2011 (UTC)
Personally, I don't see why they should be userfied. I couldn't see anything "user-ish" about them when I looked. I was only guessing about the structure; it's the only thing I noticed that might be considered a problem. (If so, and if necessary, a quick-and-dirty volume skeleton can be created. With the wiki format anything can be amended and cleaned up later.) - AdamBMorgan (talk) 01:23, 20 May 2011 (UTC)
What is this about me doing what??? I have neither deleted any of the works nor moved them. While patrolling I saw that three or four works were sitting at the root level and I asked Ineuw to move them to their appropriate place, and paid no further attention to the matter. I would agree that user subpages are not the preferred place to move main namespace works. Can I also note that while Ineuw can move pages, he cannot delete them, so if they are being deleted it is another administrator.
For the works themselves, and their location, there is good guidance at Wikisource:WikiProject Popular Science Monthly about how we are looking to develop the work and to display it, and using that guidance would be beneficial, so that we can have some consistency about the work and its presentation, rather than a hotchpotch. There is also the useful template {{PSM link}} that can be used from author pages to get works to their appropriate hierarchical subpages. We always encourage the creation of a redirect from the root level to the articles as appropriate. — billinghurstsDrewth01:25, 20 May 2011 (UTC)
StateOfAvon please don’t blame anyone else but me for moving the paragraphs from the main namespace. I assumed that Wikisource does not permit individual paragraphs extracted from an article and published in the main namespace.
As for your paragraph selections, the complete process of proofreading a complete article creating the PSM main namespace, header etc. manually, is time consuming which I haven’t got, having to deal with numerous unexpected issues with other aspects of the PSM project, like images and uploading. This is in addition to my proofreading and harvesting PSM article titles here for the generation of the main namespace pages, which currently is at Volume 31.
Your earlier proofreading requests, prior to May 12, pointed out unrelated original publication layout issues which do not exist prior to Volume 50 and I am not ready to address them because it requires discussion here.
Some days ago, I posted an extensive reply on your talk page explaining all this. Perhaps this was done in a roundabout way and meaning-wise, we were like two ships passing in the night.
The decision to publish, or not, a partial article in the main namespace is really not up to me, and I acted on my own to save me time. Also, I noticed that you are doing OK, and in due time you’ll get accustomed to the Wikisource environment. Time, or rather the lack of it, is a major issue here, so a reply is not always forthcoming as expected. Please study past work as the model to be followed.
As for the PSM main namespace layout, this was decided upon some 18 months ago after an extensive discussion in the Scriptorium. You are not the first person with a similar issue. — Ineuw talk03:54, 20 May 2011 (UTC)
Actually I didn't realise that these are incomplete articles that StateOfAvon doesn't intend to complete. This fact makes userfying look much more sensible. Hesperian04:27, 20 May 2011 (UTC)
Hesperian it is one of those unclear definitions of incomplete articles, as it is a built components of contributions, so a section could be complete. One day we may consider to add an anchor, and redirect the page name to the newpage#anchor. Or maybe they could be considered standalone due to content and reference.<shrug> Either way I have created Category:PSM maintenance and poked the category on the pages so that they are not lost and can be maintained and reviewed in time. — billinghurstsDrewth04:43, 20 May 2011 (UTC)
I apologise if I was needlessly brusque, but I hope you can understand my frustration at seeing works I create suddenly missing or denigrated. I do not think "The Meaning of Easter Eggs" can reasonably be considered to be "the same article" in Popular Science as "British North Borno", "Philosophy of Capital and Labor", "Pearls in the Red Sea", "Games of the Greek Islanders" and "Preparation for the End of the World", these all seem to be distinct, albeit short, articles on separate phenomena, with separate titles, on separate subjects. And it would be odd to go to Portal:Holidays#Easter and find yourself reading an article on pearls, Marxism or Greece (or more oddly, find yourself reading someone's userpage...) ...those articles have their own portals...to me it seems obvious - others may disagree - but I think we are best to not force others to conform to our personal preferences unless it is clearly disasterous to do otherwise. And I do not think it is disasterous to have me add The Meaning of Easter Eggs, Negroes Who Owned Slaves or The Health of American Girls as their own articles; since Popular Science seems to have originally published them as standalone works. StateOfAvon (talk) 22:42, 20 May 2011 (UTC)
We've all been there.<shrug> With presenting our works we do look to give justice to the overarching works not solely the snippets of content. One of the reasons for this is how these works were referenced contemporary to their publication and then in more modern times. We want to be able to prepare wiki cross-references in other works that point to the future place of the identified work. We have arrived at this point after multiple discussions, and one has to also consider how we disambiguate as that overlaps with this process. So yes we want clarity, and we have personal preferences, however, that should not mean that you can discard some of our learnings, and how we have learnt to do things.
To these smaller text articles that are part of a miscellany type there are other ways to display those rather than as standalone, and that is visible in other articles. We can create an anchor/subpart of the subpage that points to the page#anchor, links from a portal would point to the anchor and we would pipe the content to obscure the page, and the categorisation on the page will cover the broadness of the content. Creating the names at the top level is fine, though such should redirect to the PSM url.— billinghurstsDrewth01:04, 21 May 2011 (UTC)
PSM lists each of them as a separate article in each issue's index, "British North Borno", "Philosophy of Capital and Labor", "Pearls in the Red Sea", "Games of the Greek Islanders" and "Preparation for the End of the World" all have their own entry on the "Index" page...the idea to group them together on Wikisource, when they weren't in the original publication, seems strange. But that does not offend me, it was the deletion and userfying that offended me. Now we are just arguing/debating style - and I recognise that you have a different view than me. StateOfAvon (talk) 01:13, 21 May 2011 (UTC)
I was specifically not referring to complete articles in that text when referring to snippets. I was more referring to the some that I saw like Marriage of the Dead which is a snippet. The big articles are clearly distinct, have authors, get categorisation, listing in portals and author pages. They belong in the works hierarchy, and they get redirects from the top level. There is no argument about those. — billinghurstsDrewth01:38, 21 May 2011 (UTC)
Footnotes and multiple columns and sections
Latest comment: 13 years ago4 comments2 people in discussion
Would it be possible to get some help with 1922 Encyclopædia Britannica/Sound? I created this page recently (please fix things if this was the wrong thing to do) after doing some initial work on this article from the 1922 Encyclopædia Britannica. I used a references template for the footnotes, multicol templates for the columns, and section markers to take only part of the last page (which overlapped with the entry on South Africa). However, when I tried to put the final page together, the footnotes are not appearing. Any idea what is going wrong here? I did manage to get the footnotes to appear briefly, but not in a very satisfactory manner, so possibly there is some conflict between the templates. Carcharoth (talk) 16:56, 21 May 2011 (UTC)
I've fixed the missing footnotes. We need to add a references template to the mainpage when transcluding pages with footnotes. I chose to use {{smallrefs}}, which IIRC is consistent with the rest of the EB. At the same time I've removed the multicol templates. We try to avoid having readers have to scroll up and down to find the next bit of the text they are reading. We are fortunate in that we are not limited to particular sizes of paper and therefore we don't need to use the various printers' tricks for using as little as possible. Beeswaxcandle (talk) 21:16, 21 May 2011 (UTC)
Thanks for sorting that and thanks for removing those multicolumns (I sort of realised they were a bit unnecessary)! A couple more questions if I may. I was considering working on some more articles from that volume of the 1922 EB. (1) At what stage is it acceptable to add the link for the article to the index list for that volume? Only after validation? (2) Should I save the raw djvu text layer as a page on the first edit when creating the page, and only then make corrections to it (as opposed to making minor corrections before saving, as I had been doing)? (3) I used to know how proofreading and validation worked, but have forgotten. Where is the page explaining this? Help:Proofreading and Help:Page Status? Ah, that's what I was looking for. It's all coming back now, and as I never learnt too much in the first place, not much to unlearn, hopefully. Carcharoth (talk) 18:14, 22 May 2011 (UTC)
(1)Once the article has been transcluded to main-space then feel free to add it to the index list. It flags that the article is at least partly deal with - it also makes sure that the article is not an orphan. (2) It's up to you how you best work. Some proofreaders prefer to save the raw OCR from the djvu first, so that they can track their progress. Others prefer to start cleaning up immediately and then either save as not-proofread or even as proofread - depending on the complexity of the page. Remember, also, if you mess up a page, just ask a friendly admin to restore the OCR and you can start again.
I should also point you to WS:EB1911, which is the wikiproject for the 1911 Encyclopædia Britannica. This may give you some helpful hints and ideas on the 1922 supplement. Have fun, Beeswaxcandle (talk) 18:56, 22 May 2011 (UTC)
English texts in alternative alphabets
Latest comment: 13 years ago5 comments4 people in discussion
Hi, what is the official stance on English texts written in alternative alphabets? A quick search has shown that there was a brief discussion about "Androcles and the Lion" in the Shavian alphabet without any result. The reason I ask, in the 19th century and there were several attempts to reform English spelling, both in the US and Great Britain. In some cases this resulted in an extended Latin alphabet, in other cases entirely new alphabets such as Deseret were created. Personally I'm interested in texts printed in the English Phonotypic Alphabet, a precursor to the IPA. There are multiple journals printed in EPA over decades along with several books (eg. [3], [4]). Since the EPA is phonetic in nature, it offers clues to subtle differences in pronunciation 150 years ago, transliterating the text into regular English would mean we lose that information.
By an amazing coincidence, I was in Utah last week and took a photo of some writing on a monument I couldn't make head or tail of. It might be in the Deseret alphabet! Or not. Sorry not to answer your question, but I couldn't resist commenting on this coincidence! Good luck with your project. Carcharoth (talk) 18:19, 22 May 2011 (UTC)
Our criteria is published or historical documents in and of the English language (broadly defined, rather than narrowly defined), of whichever century that it was written or variation of such. Our mission is alphabet independent. If it fits within the criteria at Wikisource:What Wikisource includes that then it fits here. If it is not in English and is in another language and still fits within the criteria of published document or historical document, then it probably would be hosted at oldwikisource: — billinghurstsDrewth02:48, 23 May 2011 (UTC)
Sidenotes overlapping/overwriting ... any css solution?
Latest comment: 13 years ago2 comments2 people in discussion
One of our issues with varying page width and sidenotes, is as we are not limited to a fixed width, is that we can run into issues that sidenotes close together will typographical overlap in the display, eg. Page:Historical Record of the Fifty-Sixth, Or the West Essex Regiment of Foot.djvu/21. Is there a css solution that we can use so that if two sidenotes try to occupy the same place, that the latter sidenotes can vertically displace downwards, rather than overlap/overwrite? — billinghurstsDrewth02:37, 23 May 2011 (UTC)
Until a solution is found, I've been resorting to the following by using breaks and non-breaking spaces (the latter which apparently don't render below using either <pre>or<code><nowiki>):
{{USStatSidenote|L|''Proviso.'' </br>Payments made with knowledge of rate determined. </br>''Post,'' p. 1634.}}
Now depending on the actual text body width rendered in a display, it may throw off the desired corresponding point of insertion, but not by much... Londonjackbooks (talk) 13:52, 24 May 2011 (UTC)
I think that since we are hosting only the portion of the list which is in the public domain (a list which is available on other websites) then there is no issue. Making it a subpage of Children's literature seems to be more properly organized. Regarding keeping this work as its own specific category, I have to object. I think that since there are many lists which could come into en.ws and a work may appear potentially on hundreds of these lists, we may end up with having, well, hundreds or categories per work. Therefore, I think going the route similar to Portal:Disney, in which Peter and Wendy is not under the Category:Disney, would be better functionally for the site. - Theornamentalist (talk) 13:59, 24 May 2011 (UTC)
I did not think we were going to remove The Jungle Book from anything, I assumed we could link the work at multiple levels, and that the move to this Portal under Children's literature was purely organizational for the Portal, not the content. Actually, now that I think of it, I am leaning towards moving this portal as a subpage of Reference works and not Children's literature. - Theornamentalist (talk) 19:03, 24 May 2011 (UTC)
I agree with a move to Reference works; eventually the Reference works portal may have a Literature Reference Works portal under it, and this portal could be a subpage of it. —Spangineer(háblame)19:57, 24 May 2011 (UTC)
Ah, I've just moved it to Bibliography & Library Science before I came here (I searched the LOC index and this entry came up, so I stole the call number). Feel free to move it again if preferred. AdamBMorgan (talk) 20:37, 24 May 2011 (UTC)
I don't have a problem with concept of the portal: "What does Wikisource have from this list of books my child should read?" However, for it to be effective in its use, it will have to mimic to some degree or other the structure of the publication - which is where we would be heading into tricky grounds. It's a shame we can't use a Wikisourcehas template on some of the listing sites and get round it all that way.
Comment - I've been runnning with the idea that without the illustrations, layout, critical commentary and summarizations, that simply listing the works of this book that are in the public domain may not infringe on any copyright. This may include removing any trace of the books formattting, maybe by simply listing the work alphabetically (and removing the current reading level style of organization). Can only a list of works, some which are PD and some which are not, be copyrighted? - Theornamentalist (talk) 12:02, 26 May 2011 (UTC)
I've been trying to Google for some information about this but the best resource I've found is Ask Metafilter. (I keep getting bibliographies of copyright rather than the opposite.) Originality, including the selection and arrangement of a limited list, might be a problem. - AdamBMorgan (talk) 12:38, 26 May 2011 (UTC)
Invitation to British Library Editathon Saturday 4th June
Latest comment: 13 years ago4 comments3 people in discussion
Wikimedia UK would like to invite you to an [Editathon at the British Library] in London on Saturday 4th June. The BL is being very helpful in terms of giving us access to both documents and expertise. Personally I would love to see this relationship being of use to Wikisource - do drop me a line if you'd like to explore things further. Regards, The Land (talk) 10:59, 25 May 2011 (UTC)
I think it sounds interesting but I don't own a laptop (and I'm not carrying my desktop computer across London). - AdamBMorgan (talk) 12:23, 25 May 2011 (UTC)
Hmm - it would, of course, be possible to come along and take notes with pencil and paper; though I suspect a laptop is necessary to feel fully involved. I was in a similar position myself until recently, when I invested in one. The Land (talk) 12:43, 25 May 2011 (UTC)
I currently have three laptops and may be amenable to letting people borrow one for the day. Or you could just help someone else. —Tom Morris (talk) 21:32, 25 May 2011 (UTC)
Empty pages
Latest comment: 13 years ago2 comments2 people in discussion
I ran some analyses on a dump of the English Wikisource and found a bunch of pages that have no text in them:
These are mostly file description pages with no description, and what's worse - with no licenses. Where it is possible, they should be moved to Commons and properly licensed and where it isn't possible, they should be deleted. --Amir E. Aharoni (talk) 15:56, 25 May 2011 (UTC)
Latest comment: 13 years ago11 comments4 people in discussion
I tried asking it a couple of times in the Scriptorium, for example here, but couldn't get an answer, so i'm trying again: Is there a way to make one of the layouts (1/2/3) the default for a book?
There is no ready way to do this as far as I know. Copying the same layout settings to all 3 dynamic layout entries currently found in common.js to one's personal monobook.js or vector.js (dependng on which is in use) will accomplish this in spite of the lack of the ability to manually force or disable those "dynamic" settings. -- George Orwell III (talk) 18:06, 25 May 2011 (UTC).
Your perseverance has paid off :) Every time you asked about this I thought about it but didn't get around to doing it. This time I threw my hands up. I wrote a script to replace the layout selection process. With it, the layout can be selected as an argument to the link, as a page default, or as a user default. For a link, click 'Permanent link' and append to the end of the url '&style=' then 0, 1, or 2 for the first, second, or third style, respectively. For a page default, you can add <div id="Layout [1, 2, or 3]"></div> to the end of the page and save (this could be a template but I don't want to mess up the templatespace with what could end up being ephemeral garbage if no one is interested). I also changed the behavior of the user default from its previous per-work if you're on a subpage toggling to sitewide. To use this, go to Special:MyPage/vector.js (if you're using another skin put that name in lowercase instead of vector) and add to the end "importScript('User:Prosody/layoutchoice.js');" then follow the instructions that appear at the top of the page.
I hope I've done this correctly such that it would be easy to incorporate into the defaults if it meets general approval. Prosody (talk) 10:54, 27 May 2011 (UTC)
Excellent! Thank you so much! Can you please make it work for all users and not just for those who put it in their private vector.js? --Amir E. Aharoni (talk) 11:16, 27 May 2011 (UTC)
On a semi-related note, maybe you could enlighten me on why the 'text-wrap' dynamic parameter has no id symbol, locking the left hand margin, currently (for illustrative purposes only) as...
So far as I can tell from the edit history, it appears that ThomasV added the CSS sigils after he wrote the rules, and he may have missed text-wrap because at the time it was on the same line as the 'self.ws_layouts['Layout 2'] = {' bit. Prosody (talk) 11:41, 27 May 2011 (UTC)
I just picked 'Layout 2' for illustrative purposes here - none of the current 3 have it. More importantly, its missing on the Mediawiki layout test-template making all that jazz about colored borders & backgrounds pretty much pointless and unuseful (at least that's the way it was for me). -- George Orwell III (talk) 11:51, 27 May 2011 (UTC)
... And since we're discussing the whole layout thing here: Is it possible to exclude the page header from the layout? Currently it's lumped with div id="text-wrap" and becomes narrow if the main content is narrow. The header should stay wide. --Amir E. Aharoni (talk) 12:15, 27 May 2011 (UTC)
I've mentioned this before too. Need the header to load in the same div(s) as the proofreading progress color-bar does, or where the root-link can be found on a sub-page, for that to happen. I've already tried manipulating the '#headertemplate' dynamic-layout .js parameter to no avail. As long as the header template loads within the container instead of "before" it, it is subject to all sorts of unwanted re-sizing. I agree with Amir - this would make the life-dynamic around here a lot easier. -- George Orwell III (talk) 12:29, 27 May 2011 (UTC)
Latest comment: 13 years ago2 comments2 people in discussion
I’m delighted to announce that the Wikimedia Foundation has engaged Maggie Dennis (User:Moonriddengirl) to serve as our first Community Liaison. The Community Liaison role is envisioned to be a rotating assignment, filled by a new Wikimedian each year, half year or quarter. One of Maggie’s responsibilities is to begin to lay out a process for how this rotating posting would work.
Maggie has been a contributor to the projects since 2007 and is an administrator on the English Wikipedia and an OTRS volunteer. She has over 100,000 edits, including edits to 40 of the language versions of our projects. Her broad experience and knowledge made her a natural fit for this role.
This role is a response to requests from community members who have sometimes felt they didn’t know who to ask about something or weren’t sure the right person to go through to bring up a suggestion or issue. Her initial thrust will be to create systems so that every contributor to the projects has a way to reach the Foundation if they wish and to make sure that the Foundation effectively connects the right resources with people who contact us. If you aren’t sure who to call, Maggie will help you. Obviously, most community members will never need this communications channel - they’re happy editing, doing the things that make the projects great - but we want to make it as easy as possible for people to communicate with the Foundation.
The job of the liaison will have two major parts. First are standard duties that every liaison will perform which may include maintaining a FAQ about what each department does, making sure that inquiries from email or mailing lists are brought to the attention of appropriate staff members, etc. However, we also want liaisons to be free to pursue unique projects suited to their particular skill sets. Maggie will develop such projects in the coming weeks.
Maggie will be on the projects as User:Mdennis (WMF) and can be reached at mdennis (at) wikimedia.org. Her initial appointment runs for six months. I look forward to working with Maggie in this new role!
Great news Philippe, and it was good to be able stir both of you in IRC the other evening (my time). I would suggest that Maggie's first task is to get Pathoschild (talk • contribs) to globally populate at her user/talk pages with some details. — billinghurstsDrewth12:28, 26 May 2011 (UTC)
Include pages (and possibly indexes and authors) in official article count
Latest comment: 13 years ago1 comment1 person in discussion
Hi, I've made a proposal to fix the article count on all Wikisources adding to it some pages which are currently not counted. You can read more about it (and possibly support it) at the general Scriptorium. Thank you, Nemo21:16, 26 May 2011 (UTC)
Nice category intersection gadget at frWS
Latest comment: 13 years ago1 comment1 person in discussion
Phe kindly showed me a new gadget at French Wikisource. It allows you to look for pages in the intersection of categories (for example "18th century authors" and "Playwrights").
Latest comment: 13 years ago3 comments3 people in discussion
Author:Constantine i have put a lot of work on adding works since wikipedia didn't seem to have any letters by constantine the great which is terrible - we should all cooperate to make sure that we fill out his stuff. i have added a bunch this week, anyone else? SonofcalebTalk
It you like, we could make it our Collaboration of the "Week". It quiet now, so it shouldn't be contentious, and I would happily support the decision, if you are willing to accept that you may need to lead from the front. CotW can be pretty slow-moving. You can propose it at Wikisource talk:Collaboration of the Week. Inductiveload—talk/contribs13:33, 27 May 2011 (UTC)
this is way too inactive i have nobody help and only somebody complain about my sources on a letter almost 2000 years old and i moved things to the talk page and the scriptorium and now on the new collaboration page you linked and it has been over a week and not one word so forget it. i added 9 works by Constantine and made links for about 40 of his letters if anybody else ever wants to bother but why bother? —unsigned comment bySonofcaleb (talk) .
In a mid-size community, there are some things that take people's attention, and are of interest. This one doesn't seem to have done so. We have all spoken about works that we think would be of interest to others, and found that it hasn't been the case. Such is life.
With regard to sources, it is important to note the source of the work, so that when someone comes across it and either wants to use it or to validate the work that they can understand the veracity of the work. One shouldn't see it as a criticism for a worked to be sourced, it is akin to citing a work at the wikipedias, and should be accepted as good practice. — billinghurstsDrewth08:20, 5 June 2011 (UTC)
Page breaks in the middle of a paragraph
Latest comment: 13 years ago5 comments2 people in discussion
Page 8 flows seamlessly into page 9, which flows seamlessly into page 10. In the scanned book these pages are broken in the middle of the paragraph, but it's not seen on the formatted page that presents the whole chapter and that is fine.
Page 10, however, doesn't flow seamlessly into page 11 - there's a visible paragraph break between them. I was trying to understand the difference between them and failed.
I've just experimented. At the end of page 10 there was a line-break after the section end tag. When I looked back at page 8 and 9, the line-break wasn't there. So I tried removing it on page 10 and the mid-paragraph page break has gone away. I don't know enough about LST to explain it, but ... Beeswaxcandle (talk) 08:33, 28 May 2011 (UTC)
Thank you. I see your change and it makes perfect sense, but when i try to edit the page myself i don't see "<section end=par2 />" at all and instead of "<section begin=par2 />" i see "## par2 ##". How can i get back to seeing what the page really says when i edit? --Amir E. Aharoni (talk) 08:39, 28 May 2011 (UTC)
That's the "new" section syntax. I've turned it off for me as I prefer the "old" syntax. You can set it back in Gadgets. In the second section there's an option for using the "old" syntax. Cheers, Beeswaxcandle (talk) 08:58, 28 May 2011 (UTC)
Yes and no. The original is certainly {{PD-old}} (the Guangxu Emperor died in 1908, more than 100 years ago), but the translation is recently done, so it is still in copyright. Since it is done by you, you can release the copyright it under an appropriate license such as {{CC-BY-SA}} or {{PD-self}}. We use the following to denote a translation with different licenses for the original and translation (change as appropriate):
Generally for a translation that is being translated locally, and not from a published source, we would use | translator = Wikisource and a more generic licence than PD-self. The reason being that as we replicate a published text, though with translations solely done here from a foreign language text, others can and are encouraged to edit as required. Generally we would be asking for CC-BY-SA. — billinghurstsDrewth08:04, 5 June 2011 (UTC)
Erik N. Kjellesvig-Waering
Latest comment: 13 years ago3 comments2 people in discussion
I'm new in US copyright law (german is much easier), so I have a little question about the works of Erik Norman Kjellesvig-Waering:
Eurypterids of the Devonian Holland Quarry shale of Ohio. Fieldiana, Geology, Vol. 14, No. 5 (1961) [5]
Pennsylvanian invertebrates of the Mazon Creek area, Illinois : Eurypterida. Fieldiana, Geology, Vol. 12, No. 6 (1963) [6]
A revision of the families and genera of the Stylonuracea (Eurypterida). Fieldiana, Geology, Vol. 14, No. 9 (1966) [7]
Scorpionida : the holotype of Mazonia woodiana Meek and Worthen, 1868. Fieldiana, Geology, Vol. 12, No. 11 (1969) [8]
I guess the first two are PD-US-no-renewal, because I can't find any record for the Fieldiana, Geology here (or any other Fieldiana). For the second two I can't find any (c) in the document, so they are PD-US-no-notice? --enomil (talk) 22:02, 30 May 2011 (UTC)
I am presuming that the journal is an American publication, and the works are first published in the US, if yes, then that is how I see the circumstances of their copyright status from the evidence produced. — billinghurstsDrewth12:50, 31 May 2011 (UTC)
The Fieldiana is the publication series of the Field Museum and the works are first published in it. I have also checked for entries of Kjellesvig-Waering here and here (if he had rewened for his own): no matches. So, they are okay for Commons and en.ws? --enomil (talk) 13:05, 31 May 2011 (UTC)
Article title disambiguation
Latest comment: 13 years ago4 comments2 people in discussion
Through an article title error, I just learned about the Mainspace disambiguation pages. The PSM project alone has 161 multi part articles so far, and if I am assuming correctly, they should also be part of this category. However, this is a manually maintained list and thus it will never be up to date. Would it not be better to just add the category to the page, as manually maintained lists can never be up to date?— Ineuw talk22:32, 30 May 2011 (UTC)
Also note that the whole point of Science and Religion is to aid the reader who types in "Science and Religion" to find the particular work they are looking for. In this case we have three such works, two of which are PSM articles. Dropping PSM maintenance pages into Category:Mainspace disambiguation pages will not aid the reader in any way. Hesperian00:06, 31 May 2011 (UTC)
The text of Josephus' works that we already have is the Whiston translation, so I don't think a new version alongside of what we've got is required. The Antiquities of the Jews is a PG work and Against Apion is a CCEL work. So both of these have a low priority for replacement. There is no source given for The War of the Jews, but it was added at the same time as Against Apion by the same contributor, so I guess that its source is CCEL also. CCEL and PG works are proofread and validated in their systems, therefore I see no point in proofreading this djvu version unless there are major differences. Beeswaxcandle (talk) 07:55, 1 June 2011 (UTC)
Replace image with TeX?
Latest comment: 13 years ago6 comments5 people in discussion
Hello, I am mostly active on Commons. I tagged this File with "Use TeX". The procedure is as follows: Someone proposes TeX code to display the formula. The use of the image is then replaced by the TeX code. When the file is unused it is deleted, hence media that can be displayed as "Text" is out of scope. My questions:
Is it appreciated to replace the image used on this page as well, or should it show the original scan? (Maybe Wikisource has other rules as Wikipedia.)
Can this file be deleted in case it is no longer used? It has "historic value". This could be considered by using this category. The file would (most likely) not be deleted then.
I've replaced the image where it is used on the page with TeX code. As far as I am concerned, where it is possible to replace formula images with TeX, it should always be done. About deleting the image, I don't know what the policy is at Commons. - Htonl (talk) 21:03, 31 May 2011 (UTC)
Please don’t delete any of the images from the PSM galleries on the Commons even if they are not used. They serve as .djvu place markers as can be seen from their file name. The unfortunate fact is that Appleton’s Publishing reprinted more than one edition of the PSM volumes, and often the two editions of the same volume are NOT the same! Images in one may not appear in the other and vice versa. This helps me locate the better edition on Internet Archive where they scanned and posted more than one edition. Also, IA - when time and their resources permit - corrects their works and rescan books. Unfortunately they don’t remove the poor scans.
Regarding formulas - as far as I know, on Wikisource, one can either use the image, or TeX, as no one advised me otherwise, and in my opinion each has it’s advantages & disadvantages. With TeX, it’s the knowledge of TeX and the larger print size, with images it’s clarity of the reproduction. — Ineuw talk22:52, 4 June 2011 (UTC)
If we have formulas in images over at Commons, then we should be labelling them with {{Use TeX}} there. Here we should encourage their conversion and one would think that they could easily be classified as problematic and either use the language marker template [[Template:Language characters](?), or create an alternative.
To push the process for dealing with TeX images at Commons, I have nominated it for deletion, so that the discussion can occur and have a resolution or an approach decided either way. — billinghurstsDrewth07:44, 5 June 2011 (UTC)
Spelling
Latest comment: 13 years ago2 comments2 people in discussion
When you create a new Index page, the following text appears:
You are viewing an inexistent page
It would be better if the word "inexistent" were changed to "non-existent" or better yet the whole sentence changed to "You are viewing a page which does not exist". —Tom Morris (talk) 14:02, 5 June 2011 (UTC)
I've changed it to simply "This page does not exist yet" (from the message's talk page, it's a bit of a contradiction to view a page that doesn't exist. -Steve Sanbeg (talk) 20:31, 5 June 2011 (UTC)
US National Archives and Wikisource
Latest comment: 13 years ago16 comments6 people in discussion
Undiscovered gems...
...or significant
historical works.
Hi all. This summer, I am serving as the Wikipedian in Residence at the United States National Archives (see Signpost, see announcement). As part of this project, and despite the title, the National Archives is very interested in working with Wikisource in crowdsourcing human-checked transcriptions of documents. Moreover, it is interested in increasing the quality and quantity of pagescans available on Wikisource from the National Archives, which I am sure you will appreciate. :-) This is an incredible opportunity to work with one of the major institutions in our field with immense holdings. While I am a fan and a follower of Wikisource, I would love to enlist the help of some of you regular editors to help make this happen. I can spend all day adding pagescans of historical documents to Commons, but without a community effort they will simply languish untrancribed and unused. Basically, I would like to help you Wikisourcerors do what you already want to do. Perhaps we might want to create a project page along the lines of WS:PSM; I have made WP:NARA on Wikipedia for a similar purpose (please check it out and get involved if you are also Wikipedia-inclined).
To get the ball rolling, I thought the "100 Milestone Documents" would be an excellent place to start. These are documents from the National Archives' holdings that have been determined to be some of the most significant documents in American history (and most have international import). Yet, I see that most of them are missing or poorly represented on Wikisource, perhaps lacking images altogether and with text simply lifted from another source, and often with no indication of which actual version is being described. The Monroe Doctrine has some of these issues, for example. I would like to challenge the Wikisource community to complete these documents (and any others among the multitude available from the National Archives).
Most of the National Archives' digitized documents are provided on the web through their catalog in scaled-down versions that do not represent text well. If you are working on one of these documents I can get a high-quality scan, including the original TIFF, like I did with this document: File:Memorial of the Cherokees.tif (and with the Ansel Adams donation). Moreover, the National Archives would really like to form a collaboration, and will highlight and encourage this kind of activity in any way it can. New Wikisource work will be showcased on their sites, like [9] and [10] (see "Read more" section) and could likely be linked to from an "Online resources" field in the document's catalog record.
So, what I am really looking for is some help from you guys to (1) create some kind of local project infrastructure with a requests page and anything else that will help you identify and collaborate on texts, and, especially (2) help from everyone to publicize this effort and bring in all the volunteers that might be interested (surely not everyone watches the Scriptorium closely, for example!). I will be your conduit to the National Archives. ;-) Dominic (talk) 17:49, 6 June 2011 (UTC)
I'm on board (and its about &*#$&@! time!). While your suggustion of 100 Milestone Documents might seem a reasonable place to start, I'd think you'd might do better by recruiting some of the regular WS help first by addressing the missing works in the already existing U.S. projects floating around. Please take a look at ...
United States Statutes at Large (the missing volumes in transcription projects table)
To be clear, I am hoping to spend my days aiding a real community effort around this, rather than doing a lot of transcribing or validating myself. So, it sounds like a requests page my be useful. In order to make them most efficient, it would really help if you could search http://arcweb.archives.gov/ and find a catalog record for the documents you'd like (i.e., an ARC Identifier number) and include it with any requests. At this point, the easiest material to get is the stuff that already has a scaled-down web version (look for the "digital media" icon in search results). Making those available just involves tracking down the drive where the files are stored and uploading them. Newly digitizing documents takes a lot of time and effort, so you might be waiting a while for any other material, though I can inquire. Dominic (talk) 20:11, 6 June 2011 (UTC)
If we could easily ascertian the ARC Identifier/MLR Numbers we would have done all that already. Nobody expects anybody to doing anything one way or the other around here but if you have access then it only makes sense for you just to do the leg work and locate the missing stuff. In light of having little progress on obtaining those works elsewhere for free, if you could just bump up the list of "things to digitize" over there, then that's helping Wikisource out too.
If we wanted 100 Bestest Documents we'd go to OurDocuments.gov and skip WikiSource altogether. There are enough copies of that kind of stuff floating around on the internet to insure they will still be around long after Washington D.C. falls into the sea. What we need are the archives held hostage by the boobs at GoogleBooks (who wouldn't know Public Domain if it pee'd on its leg) or the profiteers at LEXIS/NEXIS (who for a small fee of a kidney or two will let you access what should be in the Public Domain for free as well). If you can't at least put those wheels in motion then you might as well focus on advertising this project on Wikipedia to recruit people to host/transcribe the available works eventually on WikiSource. There just isn't enough independent dedicated user traffic currently on Wikisource to meet what I think you were hoping to do. What dedicated users that do lurk about on Wikisource are fairly tied down to their own existing topics and projects (though everybody is open to pitiching in whenever they can - your mileage may vary and to be clear - I don't speak for everyone on Wikisource either). -- George Orwell III (talk) 21:09, 6 June 2011 (UTC)
I am very realistic about what Wikisource can accomplish; I just want to make sure it's able to utilize the National Archives' offer of assistance to the fullest. You might have missed my point slightly. I am asking for the ARC Identifier because that's how I would look them up to get the scans, since they aren't always currently public. From the looks of it, I don't think Wikisource editors have been especially careful about including those citation numbers in the past, probably because it didn't seem very important. A "100 Milestone Documents" project was just a suggestion, and you're free not to not like it. And, realistically, while I will ask about as-of-yet-undigitized documents (please make a list of priorities!) there is probably not a high chance we will get them in the near-term unless there are any locals who want to come in to an actual National Archives and volunteer to scan. I will be reaching out to local amateur scanning groups, though, so that list of Wikisource priorities might interest them, too. Dominic (talk) 14:39, 7 June 2011 (UTC)
I would be glad to help out however I can, I know the project would love to have access to great scans. but we don't have a huge volunteer base to proofread as much as you can scan in during the summer. Our community project Wikisource:Proofread of the Month usually get through a single book a month. Perhaps involving Wikipedia groups that have an interest in the available works, that can be stored on Wikisource to support their projects on Wikipedia? JeepdaySock (talk) 10:53, 7 June 2011 (UTC)
I think this is a wonderful idea, and I'd love to help in whatever way I can (and how much my schedule this summer will allow). I'd pitch in to help with creating the infrastructure for the local project and the transcription. My question, Dominic, is how to navigate the OurDocuments.gov website. I can easily find the "100 Milestone Documents" and the "People's Vote" documents. But I can't find anything else that is a source text (and I'm sure they have a lot more), so I wouldn't even know what to put on the WikiProject page. In this regard, a website like Library of Congress is more appealing since it's much easier to find texts.
Of course, there is much value the National Archives which we could and should tap, and I'd love to help out. I think we just need a sense of what the National Archives has scanned and what's not listed on their website to help out more. And it would be nice to advertise on WP or COM, since we are pretty small and don't have the manpower for the sheer influx of documents that the National Archives could give.—Zhaladshar(Talk)12:50, 7 June 2011 (UTC)
The National Archives and Records Administration (NARA) is the official record keeper of Federal Government and little else. The Library of Congress is more akin to a "real" library in the sense that it holds much more than just important or historical Federal documents. Its gone well beyond its primary function over the decades (a research arm for Congress) as well. Neither is particularly friendly to the Google enabled so good luck finding actual scans rather than reams and reams of microfilm - I hope you do better than I do.
Basically, there are only two ways to search NARA for possibly interesting WS-hostable stuff...
The ARC & MLR numbers drive everything so I'd make sure to get those on anything one may find online because names or titles really don't help in locating the hard copies to scan or that have been scanned. -- George Orwell III (talk) 13:22, 7 June 2011 (UTC)
Zhaladshar, this is good information. I didn't mean to imply that OurDocuments.gov was anything like a catalog; it's just a side project of theirs. And yes, even that site only has limited images, which was kind of my point. Most documents are on the web in incomplete and poor versions, even though they have been scanned at some point. Right now, the easiest thing to do is to search for items which already have digital copies online. These will typically be scaled-down or incomplete, and often unusable, but I have access to the original high-resolution TIFFs. Dominic (talk) 14:39, 7 June 2011 (UTC)
Right. Sites like OurDocuments.gov at one time use to (and probably still) do stupid things like provide only the first and last pages of a seven-page document. The missing 5 pages (along with the other 2) would usually turn up somewhere in the NARA site(s) if you knew where to look long enough. I gather the point being made now is in those instances where we know a scan exists (have a 1st and last page somewhere online) and there is no current way to ascertain where those missing 5 pages are on NARA (if at all), we can request the entire archive be (re)released/(re)listed so that we can upload and transcribe a complete work -- or something along those lines. -- George Orwell III (talk) 15:42, 7 June 2011 (UTC)
I think a good think to do would be to set up WS:NARA, and have people willing to at least prepare index pages for the files you rescue, and link them to the appropriate portals and author pages with {{small scan link}}. That will give us a base to work on in future, and it is easy for people to jump in a do a page here and there. If they had to fetch a file, set up an index page and link all by themselves, you won't get the casual editors involved, or those with little WS experience. If people are going to come from WP, let's make it easy for them!
I have set up Wikisource:WikiProject NARA to co-ordinate the retrieval and preparation of works coming from NARA. Any users interested are encouraged to add their names and a brief statement of skills they would like to lend to the project. Hopefully we will attract some outsiders with this project, so it would be nice for them to get to know the team. Inductiveload—talk/contribs03:56, 8 June 2011 (UTC)
I think where Wikisource can really help you is with the set-up and support of these projects. We have learned the tricks of the trade and common pitfalls and can help you and your proofreaders beat the learning curve. What documents you want to focus on should be predicated by where you are getting the proofreaders interested. Whether they can be gathered from ranks of Wikipedians or through the connections of the NAR, what you can find that interests them would be the best guide for content. But you are putting the cart before the horse at this point. First you need to find the volunteer proofreaders, then with their help select content, then let us know what you will be focusing on and where the files are and we will bust out the structure so that your proofreaders don't notice there being a high bar to jumping into the project. We don't really get the traffic to supply you with proofreaders directly. I don't suggest you use a "Build it and they will come" approach--BirgitteSB00:52, 8 June 2011 (UTC)
Accessibility for the colour blind?
Latest comment: 13 years ago4 comments3 people in discussion
Based on a recent discussion on the Australian Wikimedia list, and some recent experience that I've had on nl.wikisource, I got to wondering just how accessible the proofreading process is for those with vision problems, especially colourblindness. If you go to a page in the page namespace over there (like this), where the required CSS is not active, it all looks like a bit of a mystery unless you actually know what's going on. Now, put yourself in the shoes of someone who can't simply fix the problem by having a stylesheet installed.
While the proofreading extension is fantastic, I think that the extensive use of colourcoding may make proofreading harder than it needs to be for the ~4% of the population who do suffer from some form of colourblindness. MichelleG (talk) 12:04, 11 June 2011 (UTC).
Looking at those, I notice they don't even have appear-on-hover tooltips to explain the meaning of those colours. I think we should at least have that. - Htonl (talk) 13:45, 11 June 2011 (UTC)
Sorry Billinghurst for not making it clear, yes, that's what I'm referring to (as well as the colour coding on Index: pages). MichelleG (talk) 06:20, 12 June 2011 (UTC).
Confirming a duplication, and probably a cleanup required
Latest comment: 13 years ago1 comment1 person in discussion
I think that I am seeing some duplication of a work however, due to the size of the dupe and cleanup that is required, I am wanting others opinion.
Re:ResidentScholar: I apologize for the edits you found unnecessary; regarding what has been added back: I find including the original scan of the Newspaper article redundant and sort of working against the objective of transclusion, in that transcluding is supposed to exclude the original artifact. Of the girls original letter, that to me can be included as it has some quality which may not be easily captured by transclusion with the girls handwriting and such. I don't mind either there, but overall feel that the Sun clip is unnecessary. Won't personally remove it though again as its no big deal. Same with the inclusion of the note; I know it's a notes field, but was only personal preference to remove it. Finally, the {{similar}} link above the header, I feel should be in the notes field, and not above the header. Oh, and can someone validate it when they get a chance? - Theornamentalist (talk) 21:24, 12 June 2011 (UTC)
What if I were to tell you I found the edits producing the transclusion unnecessary? Wouldn't that render the apology you made for your edits insulting, by asking (after indicating it being an arbitrary item of your concern) someone to reconfirm acts for which you just apologized, and especially after embracing in your so-called apology for your edits, among other nullifications, the statement that you simply removed what you "overall feel...is unnecessary"?
And that just addresses your tone. The substance of your defense for denuding an article (calling it "moderniz[ing]"), in one edit, of its accretions that had been gathering since prior to the origination of English Wikisource, is that it happened in installments.
You just didn't consider the notes field first, where it says the editorial is "an indelible part of Christmas lore" (and probably ties for first as having the most memorable line from an American editorial with "Go west, young man!") so you didn't realize the document itself had historical significance that would interest Wikisource's readers (Actually you didn't say you didn't realize it; you said it didn't appeal to your "personal preference"—again, slighting historical significance by calling it an arbritrary item of your concern, instead of it being what is essential).
No you just happened to consider the newspaper itself first so you said "Gee, I'll transclude it—don't need the original here!" then "don't need the original of the original—modernizing away!" then the notes section, "Just describes what I removed! Why bother to read it?"
Wow, I don't understand where you found any tone; I went over each point that seemed to be of conflict with what you reverted so you could understand why I edited the way I did. As for the notes field, something like what is present in the notes field I personally find to be more appropriate for Wikipedia, which we have a link for in the sister sites area. As for each "page," we typically have one item per page, and since the clip had both, that seemed the way to go. I see no reason for transcluding to do any harm to your page, but I guess I should be more careful in the future. As I said before "its no big deal," its a wiki, people make edits on "completed" pages all the time, that's the purpose of a wiki, the fact that you took such offense to it I find peculiar, but again, no big deal. Won't touch the page again. - Theornamentalist (talk) 15:28, 14 June 2011 (UTC)
The issue about {{similar}} is that some of our header styles made it impossible to embed similar properly, and due to the early days of how things were implemented it was looking butt ugly. As is discussed at Template talk:header it would be good to see all that matter merged in a neat way into {{plain sister}} though it becomes an issue of size and display. — billinghurstsDrewth09:08, 15 June 2011 (UTC)
Latest comment: 13 years ago4 comments3 people in discussion
A "duh" question from me: If Mainspace pages (which make up a whole text) are linked to (subpages of) a Mainspace Title, we don't need to place a tag on every page do we?—just on the Mainspace "title page"? Just checking! Londonjackbooks (talk) 15:35, 13 June 2011 (UTC)
When I asked this long ago, I was told that we assume that a license tag on a page is assumed by default to apply to its subpages, unless the subpage has its own tag. (So, yes, we don't need to tag every subpage.) - Htonl (talk) 15:39, 13 June 2011 (UTC)
An example of this can be where there is a modern foreword/commentary/preface/... etc. to an old text, alternatively where an old work is inserted into a more modern work, though generally we don't overly concern. Other examples are periodicals where the overarching work will have one licence, eg. {{PD-1923}} and the other parts can be licenced more accurately if desired. — billinghurstsDrewth09:14, 15 June 2011 (UTC)
Question about proposed policy page procedure
Latest comment: 13 years ago4 comments2 people in discussion
How do I resolve a dispute regarding the proposed policy Wikisource:Annotations. It's not a content dispute per se, rather the user (Cygnis insignis) is using strike-outs and unsigned opinions as part of the proposed policy, directly in the policies themselves. His opinions are fine, lets discuss them on the talk page, but not directly in the proposed policy page! That's what the discussion page is for. In 8 years of Wikipedia I've never seen anyone do this. I've tried multiple compromises, but the user is adamant about using strike outs and unsigned opinions as part of the proposed policy itself. So I need help with conflict resolution on this, as we are at the point of simply reverting one another and I don't want to be in a revert war. What should do? (I'm not that familiar with Wikisource). Thanks. Green Cardamom (talk) 15:46, 13 June 2011 (UTC)
It is looking butt ugly and confusing as a document. One would think if a respectful position could not be achieved on how to progress then we would look to utilise recommended processes from other wiki spaces, eg. Wikipedia:BOLD, revert, discuss cycle . Generally we would keep our bold to sentence case as we try not to do the yelling here. ;-) I suspect that we need to pare it back to an agreed position, even if that is a long way back, and then progress from there through discussion, ideally on the talk page. — billinghurstsDrewth10:15, 15 June 2011 (UTC)
Part of the problem is the proposed "policy" page is not a policy at all, but an argument for why annotations should exist at Wikisource. It shouldn't do that, that's a separate discussion. As a proposed policy, it should provide rules and guidelines, under the assumption that Annotations are allowed. So maybe the thing to do is remove the rationales and leave a core set of rules/guidelines. Then the debate over the existence of Annotations can proceed in a more appropriate forum elsewhere. Green Cardamom (talk) 23:11, 15 June 2011 (UTC)
User talk:page created on it.wikisource
Latest comment: 13 years ago12 comments6 people in discussion
I received an email showing that a user account (talk page) was created for Londonjackbooks (apparently by Xavier121; a quick scan of his contributions show a couple other familiar names from here that he created pages for as well) "over" at the Italian WS. I have not made any contributions to it; is it just that the WS sites are "connected"? can I expect similar user page creations from other WS sites? Just wondering... Londonjackbooks (talk) 12:23, 15 June 2011 (UTC)
Did you visit it.ws at all? Some wikis which have programmes for welcoming new users seem to detect you as a new user even if you visit without editing. I presume that Xavier121 is involved in such a welcome programme. - Htonl (talk) 13:16, 15 June 2011 (UTC)
Ah, my only guess is that when I was looking around for Aquinas' "On Kingship" (De Regimini Principum) a while back, I think I remember getting a link to the it.ws site during that time... So, if I was logged in to WM at the time I was merely browsing, I can then be detected somehow? Londonjackbooks (talk) 13:32, 15 June 2011 (UTC)
Yes, it seems that if you are logged in (with unified login) and you visit a wiki for the first time, your account is automatically created on that wiki; and user account creations are logged - here, for example, is the en.ws user creation log. - Htonl (talk) 14:14, 15 June 2011 (UTC)
Ok. That makes sense. I shouldn't be so naïve anyway as to think that browsing of any sort can go "undetected"... Always curious as to the "how" of it all anyway, so thanks! Londonjackbooks (talk) 15:02, 15 June 2011 (UTC)
Well, you can take comfort in the fact that no-one knows which pages you browsed - except, I suppose, the admins with access to the server logs. :) Actually, I wonder if they even keep logs of page views; it'd need a huge amount of storage. - Htonl (talk) 17:56, 15 June 2011 (UTC)
But it would be worth having privacy advocates request that WMF come up with a definitive policy on destroying those records since it's nobody's business if I read sappy love poetry into the morning hours. StateOfAvon (talk) 19:02, 20 June 2011 (UTC)
While Wikimedia probably can get visitor records, like any other website, it doesn't necessarily have to be linking that with a user name. The site software needs to detect you as a user in order to display the right links in the top left (userpage, talk, watchlist etc) as well as check for "you have messages" pop up messages. That is probably what it.ws is using as a basis for automatic messages. The page view records may well be a completely different system (although they quite possibly capture your IP number). - AdamBMorgan (talk) 21:56, 20 June 2011 (UTC)
For some clarity, there is no person who can identify which page any person has visited; what has triggered on the noted occasion is that a logged-in user has visited a new wiki and their account has been created on that wiki. The information is available to anyone in the local log file, and it is no different than looking at Special:RecentChanges where new accounts are noted as well as page edits, moves, etc. There is the logging of edits in the page history. @StateOfAvon: WMF is ultracautious about all aspects privacy and their logs, and I would think that they cull their log files regularly and I doubt that they associated page visits to an account name. — billinghurstsDrewth10:31, 21 June 2011 (UTC)
I guess it's similar to personal websites: some of which [poor grammar here, I think] you can view IP addresses of visitors to your site, as well as how many page visits they make, but not the exact page(s) each unique visitor has visited... No worries... Thanks all for the input, Londonjackbooks (talk) 11:27, 21 June 2011 (UTC)
┌────────────────┘ Hi! I'm OrbiliusMagister, bureaucrat at it.source. Let me explain something and ask for an "external" opinion about this topic:
On it.source no bots welcome users. RC show only self-registered users on their firs login, but we like the idea of welcoming also automatically created users, as they appear through special log pages. I always thought that a sing of wikilove, even if unsolicited, lets such users understand that they are both noticed and welcome. There's no particular purpose nor any kind of menace, but recently a user deleted his/her user talk in disappointment because he didn't want to be noticed... is it such a scary experience? Should we ignore automatically created accounts? I know that there is a different perception of privacy in different places, but what's the concern in welcoming anyone passing thorugh it.source? I'd like to read some more information about this topic. - εΔω 13:18, 23 June 2011 (UTC)
Gday OrbiliusMagister. I too used to welcome all new users (from the local creation log) so that they could have some information about what we were about. Another admin did have an opinion that we should not be welcoming all people, and while I did not fully agree with their position, I listened to that and generally now only welcome those who edit. We should welcome people and my two basic premises are 1) newbies often are looking for somewhere to ask a newbie question, and the welcome script gives them basic info and a contact name; 2) some like being welcomed, and we like for them to join the conversations, and a welcome is the best and most efficient means. There will always be some who want to fly under the radar, and that should be okay, and if they blank a generic message (welcome) <shrug> so be it; if it was a specific message, eg. a "please don't", then probably not okay. (personal opinion only) — billinghurstsDrewth00:04, 24 June 2011 (UTC)
Request for a hold-off
Latest comment: 13 years ago4 comments3 people in discussion
I would like to request a hold-off on editing for Roman History (and all remaining 8 volumes) because of this fact. I am a teacher, and have inherited a class that works on typing in/proofreading works. Outlines of European History Part 1 was suspended for the class, but now that I see Dio's work on here, I want them to work on it. I promise this would be a completed task, and will be worked on every day. - Tannertsf (talk) 17:18, 15 June 2011 (UTC)
Yes and no. Yes. because until Roman History is done, they aren't working on it. No, because they will be back to it later. - Tannertsf (talk) 23:35, 15 June 2011 (UTC)
Create a page for Cherbuliez and change Valbert to a redirect to that page. Put a note on the Cherbuliez page that he wrote using a nom-de-plume.
Roman orthography of Cyrillic family names is a mess with multiple published spellings for the same name (e.g. Tolstoy vs Tolstoi or Czar/Csar/Tzar/Tsar). In the end we have to pick one and make the others redirects. It is also important to include the patronymic when dealing with Cyrillic names. With the enWS preference for Author names being the full name, I would go for Mikhail Ivanovitch and choose one of the spellings of the family name based on frequency of use in the source texts. Beeswaxcandle (talk) 09:42, 16 June 2011 (UTC)
Essentially, I always make a page for the actual name, and any other spelling variations or pen name become redirects with a note on the author page. Thanks. — Ineuw talk10:12, 16 June 2011 (UTC)
Hi. Sorry for being slow to see the revival, as I only now understood the connection to that section. Also, just saw Billinghurst’s name alignment of Author:M. Vénukoff. Thanks to you both.— Ineuw talk21:17, 17 June 2011 (UTC)
Rendering of formulas
Latest comment: 13 years ago3 comments2 people in discussion
They look fine for me, just the same as wikilivres. If you have a zoom function in your browser, that can create blurriness in images if not set to 100%. Inductiveload—talk/contribs13:46, 18 June 2011 (UTC)
British Library to release 250,000 out-of-copyright works
Latest comment: 13 years ago2 comments2 people in discussion
Checkout the news in this BBC article. About time too! I can't imagine what the benefit the British Library would have got if it had held on to 18th Century texts which would have simply been left to rot or fade away in their archive. They should have started a programme of releasing electronic versions of out-of-copyright works into the public domain years ago, and so should every other libary that holds out-of-copyright works. Better still, why not let allow readers themselves to scan and release the works into the public domain, and cut out the middleman (Google in this case): now that would truly be "giving access to anyone, anywhere and at any time".----Gavin Collins (talk|contribs)16:10, 20 June 2011 (UTC)
Great news. One can understand the reticence of BL with regard to the protection of the physical books, and even for the inconvenience of a process that involves scanning ¼M books when trying to do one's job, but reticence shouldn't be stubbornness. Let us hope for an improved scanning process from Google … no missing pages, no fingers or thumbs, better quality grey scale, and colour images to be in colour (perish the thought). — billinghurstsDrewth22:09, 20 June 2011 (UTC)
Publisher/publication name space
Latest comment: 13 years ago9 comments5 people in discussion
I've seen nearly an equal amount of publisher pages in Portal, Author, and Mainspace. Do we have an official way, or is this a grey area? - Theornamentalist (talk) 11:14, 21 June 2011 (UTC)
Authors should be just people and mainspace should be just works. I moved all the publishers I could find out of authorspace into portalspace after previous discussions here. The only grey area of which I am aware is Author:Stratemeyer Syndicate, which is not technically one person but fits authorspace better than any other namespace. There are quite a lot of redirects from authorspace to portalspace (so that they can be used as authors in the header); these should all be tracked by Category:Non-author author pages. - AdamBMorgan (talk) 13:08, 21 June 2011 (UTC)
So, should something like The New York Times really be a portal, with each subsequent publication (ie, instead of :NYT/DATE, should it be :NYT DATE) as its own mainspace entry? This is opposed to the current subpage system. - Theornamentalist (talk) 14:17, 21 June 2011 (UTC)
I see the tangent in that discussion touting de.wikipedia's solution to an imaginary problem, not a consensus. Perhaps that acronym indicates where that happened, I'm having trouble correctly recalling what it means ... is it "In Internet Relay Chat"? And speaking of acronyms, why was this necessary. CYGNIS INSIGNIS17:03, 21 June 2011 (UTC)
Newspapers are a stranger beast. They are a publication in their own right (hence a work in main namespace), yet they could also be a portal, and that is often to how you are going to display the text. As we have articles, and it is less than likely that we are going to get full publications there was an attempt to add some naming structure, so the root pages have (sort of) evolved. — billinghurstsDrewth14:32, 21 June 2011 (UTC)
Hmm, I think organizationally in this case, it might be best to have each day as a publication reflected in the mainspace, or, not a subpage. Does our "works" counter count subpages? I kind of feel like it shouldn't, and that it is more conservative (and not bloated; 206,000? c'mon) because from my understanding of how libraries count works, it is by publication, ie, a physical copy being 1, and not based on how we arbitraily separate works. And with the Times being subpages, if counted this way, it will exclude anything as a subpage, so I believe that each belongs in the mainspace. But back to the first point: so all publishers go in Portal space? Maybe we can make that evident when someone is creating an author page for prevention. While I'm not crazy about using portals, and feel publishers deserve "Publisher:", it's no big deal, and I will fix the ones I've created under author: in the past. - Theornamentalist (talk) 16:21, 21 June 2011 (UTC)
Latest comment: 13 years ago3 comments2 people in discussion
Hi everybody. I wrote a new tool for easy comparison of two versions of the same text, for example comparing the original text with its translation in another language, or comparing between two different translations but in the same language. You can see an example on it:Le odi di Orazio/Libro primo/XI: try clicking on one of the double arrows (⇔) on the left: the linked text is loaded in a column on the right, and the shortest of the two columns can be dragged up and down for easy line-by-line comparison.
This is somewhat similar to (and inspired by) the DoubleWiki extension, but tries to overcome some of its limitations, like the impossibility of linking to a page on the same wiki.
I've added it to the shared scripts, so that every subdomain can use it if they want. What do you think of it? Do you like it?
OMG, I love your text size modifier! I was working on something like that a while ago, but to no avail. If the community approves, could you import that? That would be exceptionally useful to include for children works among other things. - Theornamentalist (talk) 21:08, 22 June 2011 (UTC)
I did it some time ago, precisely because a user complained about lack of "children-friendly" text size. The script is here: you'll need to modify your Header template, to have a <div class="textBody"> sourround the text you want to enlarge/reduce. The icons are placed just below the header, in some cases they appear over the text, because you use full-width visualization; so you will maybe want to move them somewhere else. By the way, the topic of this discussion was a bit different! :-) Candalua (talk) 09:42, 23 June 2011 (UTC)
Coder question
Latest comment: 13 years ago3 comments2 people in discussion
Is there anyway to add the functionality produced by
One would think so, and can I suggest that maybe m:Tech would be a reasonable place to ask the question. They are more css/js/mediawiki and more time responsive, especially when patted in the right way. — billinghurstsDrewth13:16, 28 June 2011 (UTC)
Latest comment: 13 years ago4 comments3 people in discussion
We are going on testing (both into it.source and vec.source) a very simple syntax to inject well-formed Dublin core metadata into html of our ns0 pages. The trick is, to add inside our versions of header templates something like this:
<span class="metadata"><dc:title>{{{Titolo|}}}</dc:title></span>
<span class="metadata"><dc:creator opt:role="aut">{{{{{#ifeq:{{lc:{{{Progetto|}}}}}|diritto|Organismo emittente|Nome e cognome dell'autore}}|Anonimo}}}</dc:creator></span>
As you guess, data are managed in different ways and formats from header templates of vec.source and it.source, but they produce an identical Dublin Core code.
Obviously there's a span.metadata {display:none} directive into both Common.css files, so that such data are completely hidden; nevertheless they can be easily found and used parsing the html of the page by a js script or a bot script. This means, that good, well-formatted Dublin core metadata can be added into any ns0 wikisource page of any language, without any user work, without any extension, with a extremely low server load (almost nothing!), producing a shared, identical set of metadata from any wikisource project perfectly machine-usable; i.e. what's needed as a basic step to build good epub version of source works, but many other applications can be thought. --Alex brollo (talk) 06:25, 28 June 2011 (UTC)
Personally with regard to metadata I am more interested in just the solution, and not the journey, the theory, just to have it happen, have a standard that I can apply without too much thinking. Previously I have seen Jayvdb talk about w:COinS metadata, and it would be great if we had the destination. — billinghurstsDrewth13:14, 28 June 2011 (UTC)
This is the resulting html into the page (I only added some break line:
<p style="display: none;">
<span class="metadata"><dc:title><a href="/wiki/The_Modern_Art_of_Taming_Wild_Horses" title="The Modern Art of Taming Wild Horses">The Modern Art of Taming Wild Horses</a></dc:title></span>
<span class="metadata"><dc:creator opt:role="aut">John Solomon Rarey</dc:creator></span>
<span class="metadata"><dc:contributor oct:role="trl"></dc:contributor></span>
<span class="metadata"><dc:date></dc:date></span>
<span class="metadata"><dc:rights><a href="<a href="http://creativecommons.org/licenses/by-sa/3.0" class="external free" rel="nofollow">http://creativecommons.org/licenses/by-sa/3.0</a>">CC BY-SA 3.0</a></dc:rights></span>
<span class="metadata"><dc:identifier><a href="http://en.wikisource.org/w/index.php?title=The_Modern_Art_of_Taming_Wild_Horses/Chapter_11&oldid=3027334" class="external free" rel="nofollow">http://en.wikisource.org/w/index.php?title=The_Modern_Art_of_Taming_Wild_Horses/Chapter_11&oldid=3027334</a></dc:identifier></span>
<span class="metadata"><dc:revisiondatestamp>20110628134816</dc:revisiondatestamp></span></p>
I feel this is an interesting result. Consider that it is completely "transparent" for user and that metadata are potentially standardized among different source projects. The Dublin Core xml format could be very interesting when exporting texts. --Alex brollo (talk) 14:23, 28 June 2011 (UTC)
I do like this. If it goes ahead, should the header be updated to include parameters for all of the Dublin Core elements (even if they aren't necessarily displayed)? Would that be unnecessary work? - AdamBMorgan (talk) 22:11, 30 June 2011 (UTC)
Works at root level vs replicating part of a website? Are we a web library or a web archive? Is there a difference?
Latest comment: 13 years ago11 comments4 people in discussion
A user has brought over a subsection of a website that relates to an incident in history, in which they are the author is the investigator. The links have all been made relative to subsection (promoted to the root level). Our current thinking about layout and design has been to put all works at the top level as individual works, alternatively we have chapters/subparts where they have been subsidiary to the physical publication. A webpage is a different beast and needs our consideration, even to the point of how much of us is library, and other how much of us is archive? and how much is that different? — billinghurstsDrewth22:08, 28 June 2011 (UTC)
Fwiw... without a pointer or two to the work(s) in question and/or the generating website, it is sort of hard to conceptualize what it is you're looking to root out here exactly. -- George Orwell III (talk) 22:39, 28 June 2011 (UTC)
Portal:Korean Air Flight 801 investigation I hadn't wanted to concentrate on the specific example, as that can lead to judgment on the work, and had wanted to general view. That said, examples do help. In part it comes to our general discussion of what constitutes subpages, which is something that many have a (somewhat) common view, though we don't externalise but by example. — billinghurstsDrewth01:43, 29 June 2011 (UTC)
Well I don't see how any of it belongs in main namespace - the archived web pages are more navigation aids than actual "works" no? Most seem to link to dozens and dozens of actual PDFs that make up the accident report (a few of which have a version or two being updated).
If the notion is to recreate the web-site mearly to link a bunch of external archived-in-time-PDFs, peppered with HTML as needed to mirror the site as it once existed, I don't think I like en.WS being utilized "half-way" like that. If all those PDFs are to be converted, uploaded to commons, proofread and transcluded, then I can see the Web-pages as subpages to the Portal: allowing navigation of the mainspace, transcluded works.-- George Orwell III (talk) 07:31, 29 June 2011 (UTC)
Some of the archived pages are navigational aids, and some of them are actual works (transcripts, witness lists and schedules, biographies of investigators, documents about investigative procedures, etc) - Those actual works already were in HTML.
For the ones in PDF, at a later point we could convert those into MediaWiki code and make them actual pages.
So the webpages which were merely navigational aids could become subpages of the portal, and webpages which contain substantial information (public hearing transcripts, biographies of investigators, pages about investigative procedures and hearing procedures) would be considered "documents"
I would also like to make an author page for the NTSB - I would need to put an author page for the agency in the English, Korean, Spanish, and French Wikisources (NTSB docs are in those four) WhisperToMe (talk) 06:16, 29 June 2011 (UTC)
Non-author author pages are actually portals, which already exists: Portal:National Transportation Safety Board. At most the author page would be a redirect to this portal. Interwiki links between portals here and authors on other Wikisources should be OK, if that's the route you intend to take (you should be able to interwiki a redirect too but it would be a roundabout way of doing it). - AdamBMorgan (talk) 11:28, 29 June 2011 (UTC)
I redirected Author:National Transportation Safety Board to the portal page, and I made portal pages on the Spanish, French, and Korean Wikipedias. On the Spanish and French ones I catgeorized the NTSB as an "author"
Latest comment: 13 years ago9 comments5 people in discussion
No big deal, but after looking at a subpage of a subpage of a long-titled work, I wondered if we need to display it so prominently at the top of each page. I mean, the title and subsection are within the header and are linked back to their parent page underneath the top. Most of the time, especially in the case of disambiguation, the title in the mainspace is more reflective of our way of setting up the site, or lack of precision or inability to name something that doesn't have a published title. Anyway, I don't think it should be removed as it is necessary for navigation, but I think that it can be made much smaller, maybe even place it off to the right or something, or not. And then, in place of the newly gained area, increase the font size of the title within the header, or not.
As long as the largest displayed text isn't something like "Title of a book with a really long name: additional subtitle/Subsection A with some more detail/Preface" or "The book (Author, 1896)". These are real titles. - Theornamentalist (talk) 01:50, 30 June 2011 (UTC)
I agree. Don't know if it can be done, but I'd love to see us give less prominence to the page title, and more prominence to the title of the work or section that the page is displaying. Hesperian02:34, 30 June 2011 (UTC)
I expect it will be in [MediaWiki:Common.css] somewhere but I wouldn't recommend editing that unnecessarily. On a specific page basis you can use magic words: {{DISPLAYTITLE:<span style="font-size:50%">{{FULLPAGENAME}}</span>}}. You can even use that to shrink the basename but keep the subpagename large, make parts italic and other stuff if you wanted. Wikipedia uses it to make film titles and species names appear in italics. - AdamBMorgan (talk) 11:45, 30 June 2011 (UTC)
I tested out sort of removing it from view by making the extension smaller and the font white, although there is likely a much neater way of doing it. Compare:
I know we should have something there for navigation, but I really like how it looks without anything on top. Will settle for something else though if its cool; Adam, how come we shouldn't mess with it? - Theornamentalist (talk) 16:51, 30 June 2011 (UTC)
It's not that we should never mess with Common.css, just that it should be rarely and carefully done. Making a mistake on that page effects the entire project and risks causing a lot of damage (fixable damage but damage nonetheless). Regarding the title:-
Technical: {{DISPLAYTITLE:<span style="display:none">{{FULLPAGENAME}}</span>}} will just turn off the title entirely; the method I mentioned to just shrink the basepage name is: {{#ifeq:{{NAMESPACE}}||{{DISPLAYTITLE:<span style="font-size:50%">{{BASEPAGENAME}}/</span>{{SUBPAGENAME}}}}|{{DISPLAYTITLE:<span style="font-size:50%">{{NAMESPACE}}:{{BASEPAGENAME}}/</span>{{SUBPAGENAME}}}}}} (ifeq to deal with both mainspace and, for example, userspace).
Principle: I don't think it's appropriate for the other namespaces, but it might work for the main namespace (although I neither vote in favour nor against this proposal). If so, and if there is agreement, it could be easily implemented by adding the desired code to {{header}}. Some reasons why not might be that the title is a standard feature, not just on Wikisource, or even on the Wikisources in general, but throughout all Wikimedia projects; playing with that may confuse, disorientate or merely irritate both casual and experienced users. (For example, I can make may around other languages' projects thanks to this standardisation; I assume the opposite would be true of non-English speaking users trying to navigate en.ws.) With this is mind, I think it should at least remain visible and easily readable. If the header title is made larger, it will still be the most prominent text at the top of the page, leaving the automatic title for navigation and conformity. - AdamBMorgan (talk) 22:04, 30 June 2011 (UTC)
I understand, definitely not something to just do without discussion. I think that shrinking it might be a simple and safe way to go. A simple argument for this is not only aesthetics, but that we have unusually long mainspace extensions in comparison with other wikimedia sites. - Theornamentalist (talk) 22:36, 1 July 2011 (UTC)
You may want to take a look on some alternatives used on Wikibooks projects:
Not a scripting expert here by any measure but those seem to alter the parameters of the same firstHeading and/or ContentSub .CSS class or id settings in question on the fly rather than making the changes to the Common files themselves as mentioned in passing somewhere above. Seems like overkill when it only seems to bother a handful of users as far as I can tell. Why not just make this a user enabled option via a Gadget or something if its all that annoying for some folks? -- George Orwell III (talk) 01:54, 2 July 2011 (UTC)
Indeed, on Portuguese wikibooks the feature was added to a gadget (after this discussion) because it may not be wanted by everybody. You can see an example of what it changes on this image. If I understood correctly the code on es.wb, the users can define the variable "g_setuptitle" to avoid the execution of function setupTitle() (although it was not designed for that, but instead to avoid problems with b:fr:MediaWiki:Gadget-TitreDeluxe.js). Helder 11:50, 2 July 2011 (UTC)
PS: some related links to discussions on Wikibooks projects:
After some thought, I have reduced my preference to one, though I will try to offer arguments against it.
Reducing the overall size to roughly 40%; just smaller than the font found in our header. This will give dominance to the actual title of the work, the section, and no other navigational or disambiguation related mainspace extensions. It still gives the editor the ability to locate the page for proper linking and such, but is more suited for the appearance to the reader of the work. However, as said earlier, this may cause confusion and is an unfamiliar look in the wiki-media sites. It is not as extreme as removing, but is enough to help fix our growing subvolume, subpage, subsection problem, of X/X/X/X. Not a problem? I know, its not end of the world, but it looks awful in my opinion when the extenstion wraps in even MY browser, and all the parentheses and dates and whatever just look silly. So overall, I say reduce the full extension to a size smaller than the header text. - Theornamentalist (talk) 16:06, 5 July 2011 (UTC)
40% is way way too small in my opinion — well for me on my displays — so I have set up a series of pages 90% - 50% (and note that these are extreme title pagename lengths). 90% → 80% → 70% → 60% → 50% — billinghurstsDrewth09:55, 14 July 2011 (UTC)
How to reference annotations at end of book
Latest comment: 13 years ago2 comments2 people in discussion
Is there any good way to handle references to annotations at the end of a book (as opposed to footnotes on the same page)? For a few works, I have created a template specific for that work. For an example, see {{Tkom}} which handles references to notes and chapters within The Kinematics of Machinery. But that was a few years ago. Has any better way been invented? It's awkward to design a new template for each work. It should be as easy as the <ref> tag. --LA2 (talk) 03:35, 30 June 2011 (UTC)
Geeze - I get the notion this new access to NARA files is "too good to pass up" but there are limits to utilizing their High Quality images in every single instance possible. 18 megs for what amounts to 1 indexed page of nothing but plain text is a bit ridiculous anyway you slice it (imho). -- George Orwell III (talk) 22:59, 1 July 2011 (UTC)
Yeah, I would hate to see Dominic lose steam due to low levels of participation. Not that it's going bad, but it could always be better :) It is definitely cool that we have direct and exclusive access to these documents. - Theornamentalist (talk) 23:18, 1 July 2011 (UTC)
To be fair, it may be due to the complexity of Wikisource. I still have no idea where to point people to learn how to use all the templates and conventions on Wikisource. It was never going to be simple, but it doesn't have to be this complicated. —Tom Morris (talk) 09:12, 2 July 2011 (UTC)
Help:Templates needs some love. If you see a way to improve the help pages once you work something out, it would be great if you can pass the knowledge on. Also, template documentation can often be improved greatly. Inductiveload—talk/contribs04:52, 3 July 2011 (UTC)
I didn't notice that myself at first; it's a shame we can't use the .tif files in Pagespace although I imagine it would take forever to load, just an extra step I wish I could step over :) - Theornamentalist (talk) 04:39, 2 July 2011 (UTC)
Currently the TIFF files are essentially archive formats, not suitable for most uses, due to size and lack of rendering in the pagespace. However, WS does have a TIFF handler installed (the "PagedTiffHandler" extension). The pagespace can handle PDF files through the "PDF Handler" extension, so maybe it can be extended to use TIFFs as well. The whole TIFF doesn't have to be downloaded, you only get a (large) thumbnail, the size of which is set on the index pages. If we could use TIFFs directly, it would be nice. However, it's probably just as useful to do the JPG/DJVU conversion and then people have a more usable file available (generally 1-3MB instead of 30!). Having multipage TIFF support is no great help when a 4-page file exceeds the Commons file limit. Inductiveload—talk/contribs04:52, 3 July 2011 (UTC)
Call for image filter referendum
The Wikimedia Foundation, at the direction of the Board of Trustees, will be holding a vote to determine whether members of the community support the creation and usage of an opt-in personal image filter, which would allow readers to voluntarily screen particular types of images strictly for their own account.
Further details and educational materials will be available shortly. The referendum is scheduled for 12-27 August, 2011, and will be conducted on servers hosted by a neutral third party. Referendum details, officials, voting requirements, and supporting materials will be posted at m:Image filter referendum shortly.
Latest comment: 13 years ago3 comments3 people in discussion
I have always been a strong supporter of DjVu files over copy and paste. It bring more editors and allows everyone to work together, plus it sorts out source and licensing issues, plus any typo errors and images. If a (public domain) DjVu book is available for a text that has been copied and pasted on Wikisource, should the DjVu version replace the copied and pasted version, or should it just be proofread and left alone? This would make the copy-and-pasted version the main version. --Angelprincess72 (talk) 19:03, 10 July 2011 (UTC)
It's my understanding that, as a general principle, works without DjVu should be replaced by works backed by DjVu where possible. If there is substantial difference between the versions then both should be kept, of course. - Htonl (talk) 19:13, 10 July 2011 (UTC)
"Project Gutenberg Etexts are usually created from multiple editions, all of which are in the Public Domain in the United States, unless a copyright notice is included. Therefore, we usually do NOT keep any of these books in compliance with any particular paper edition."
This disclaimer doesn't help Users here much, or the end user. It is not possible to provide a full citation or know whether something can be accurately cited. The differences between their text and any published edition is significant, perhaps 5-20 per line, and whether these editorial differences are from later publications or the work or typos of a transcriber is very difficult to verify. Having a PG text, or another second-hand transcript, may be better than nothing, but preserving a duplication of those texts as {{versions}} is unhelpful. CYGNIS INSIGNIS17:28, 12 July 2011 (UTC)
Not proofread/proofread status
Latest comment: 13 years ago8 comments7 people in discussion
I realise this is something I should already know but can someone clarify what counts as "Not proofread" (red) and what counts as "Proofread" (yellow). I've always taken my first attempt at a page as red. However, I've noticed some people jumping straight to yellow, which would imply that red means the unmodified OCR text. Which one is correct? - AdamBMorgan (talk) 09:34, 11 July 2011 (UTC)
I did the same thing to, for a month or so, but you can mark proofread as the initial reader. I use not proofread for text I am working on, and occasionally OCR. - Theornamentalist (talk) 10:17, 11 July 2011 (UTC)
I'd say that if you've just skimmed the OCR text to look for glaring errors, then mark it as "not proofread"; if you've actually read and compared it carefully, then mark it as "proofread". - Htonl (talk) 12:27, 11 July 2011 (UTC)
Funny, I've been wondering the same thing myself the last couple days... Price Fixing is still mostly red, although I typed it all "from scratch" and had listed it as a complete "New text" on the Main Page... Now I have the "permission" I need to quickly go through and turn those red boxes to yellow without having a conflicted conscience about doing so! :) Londonjackbooks (talk) 04:30, 13 July 2011 (UTC)
Help:Page Status and that clearly defines Proofread and Validated, so Not Proofread is anything prior to Proofread, ie. text added, not checked; or maybe not completely checked; or not confidently checked. Examples that I can think of are bot applied layer; page loaded and too hard; biographical work where one biography undertaken, but not whole page; or just text loaded for a myriad of reasons. — billinghurstsDrewth10:14, 14 July 2011 (UTC)
What I like to count as Non Proofread is text that may just have been OCR extracted but not been completely proofread, so there may be typos, punctuation errors and misplacement of header. Another thing I like to count as Non Proofread is you are halfway through proofreading, but want to save the changes and finish off the page later. Proofread is where the text has been fully compared to the scanned page, and there are no differences. --Angelprincess72 (talk) 18:45, 14 July 2011 (UTC)
For me, "Proofread is where the text has been fully compared to the scanned page, and there are no differenes... that I'm aware of." - Theornamentalist (talk) 18:56, 14 July 2011 (UTC)
Latest comment: 13 years ago5 comments3 people in discussion
If you proofread an old journal that contains book reviews, it could be nice to indicate which book is being reviewed, e.g. by an LCCN (Library of Congress Call Number) or OCLC Worldcat identifier, so that library catalogs can make back links to these reviews. Do you know if this has been tried anywhere, in Wikisource or in other digitization projects?
For example, the page The American Journal of Sociology/Volume 1/Number 2/Reviews (from 1895) contains a review of The Evolution of Modern Capitalism by John A. Hobson. This book is 80158138 in Worldcat, and I can manually "add a review" there, but instead we could tag our page with {{review|oclc=80158138}} and hopefully make OCLC harvest those tags automatically. Or if OCLC won't do that, maybe we can work with OpenLibrary.org instead. (This particular book is currently not found in OpenLibrary, but that could change with time.)
Another issue is, if you would tag that review and OCLC or OpenLibrary would harvest the tag, how would they translate the page name "The American Journal of Sociology/Volume 1/Number 2/Reviews" into a pretty reference without the slashes? --LA2 (talk) 21:22, 12 July 2011 (UTC)
Comment above amended at 22:01 and 22:04, 12 July 2011
What links here provides a list of all references to a work, eg The Evolution of Modern CapitalismSpecial:Whatlinkshere I presume the ability to add a review is for one 'added by anyone', rather than the contemporary published reviews, but all the incoming links would be a useful resource for composing such a thing. This is one of many emergent properties of local links in this library, they are potentially very powerful, though the value of this can be diluted where the reference is not made by a proper publication (as with this example). CYGNIS INSIGNIS21:54, 12 July 2011 (UTC)
The subpages for each journal is usually organised in a predictable way, and resemble the conventions applied to other works, so making the reference 'pretty' would be very easy. CYGNIS INSIGNIS22:33, 12 July 2011 (UTC)
There are similar reviews in Popular Science Monthly and on the few occasions that I have proofread those pages, I have wikilinked the works (to redlinks). I am not against a template that provides something akin to meta data, though would not think that linking to a work in the Worldcat is a priority. Do you see that there would be a possibility for error in such linking to WorldCat, wrong edition, wrong title, etc. If we were going to be doing that sort of linking, wouldn't we also be wanting to add similar metadata to the existing works either in a scheme as discussed above, or via the talk page of each work? — billinghurstsDrewth13:57, 14 July 2011 (UTC)
Maybe this idea raises more questions than we had before. It could be nice to explore it within a limited subject matter, such as (reviews of) books about Greenland. But you always run into the issue of what is a work (the same work, or two different ones). Is a review of a translation also a review of the original work? Is a review of the first edition also valid for the second edition? etc. Doesn't the library association have a "summer of cataloging", similar to Google's summer of code? --LA2 (talk) 23:14, 14 July 2011 (UTC)
Can't touch this...
Latest comment: 13 years ago14 comments7 people in discussion
Looks like you neglected to move the djvu file associated with the index. Since it's on commons, you have to tag it and wait for someone with file move permissions to move it for you. Last time I had to do that there was I think a two day backlog. Prosody (talk) 06:04, 13 July 2011 (UTC)
Can it not just be reverted or moved back (here on WS) without having to go through Commons (yet?) since my flawed move was only done here? Londonjackbooks (talk) 06:09, 13 July 2011 (UTC)
I'm afraid to touch anything more... Kathleen tried to do a rollback, but said it "didn't work." I have just asked Spangineer for help, as he has helped me with Commons moves before, but I don't know if he's around... Londonjackbooks (talk) 06:26, 13 July 2011 (UTC)
I have moved the source file on Commons. Regulars here who are also Commons admins include myself, Billinghurst, EVula, Jusjih, Spangineer and Yann. Hesperian06:29, 13 July 2011 (UTC)
I've just moved the Page namespace pages that had been proofread. I've run into this problem in the past also. Moving an Index doesn't take the Pages with it. (Maybe that's something we could ask for in a future software update.) Beeswaxcandle (talk) 07:21, 13 July 2011 (UTC)
A while back someone proposed that index pages reside at the page namespace root page; i.e. we have all these pages like Page:Diary of ten years.djvu/338 but did it ever occur to you that the root page, Page:Diary of ten years.djvu, is a redlink and therefore available? If the index page resided there, and subpaging was turned on, and it were possible to move more than 100 subpages at a time, then you could move the index page with the "Move subpages" box checked, and all the pages would go with it. There is a certain elegance to this, but also some significant issues. There was opposition to it, and ThomasV, who maintains the ProofreadPage extension, declined to implement it. Hesperian01:27, 14 July 2011 (UTC)
Phew, Thanks! When I saw all the pages were blank(ed) after the Commons move, I worried that my initial move may have ended up removing someone else's hard work... Sorry, all... Londonjackbooks (talk) 13:27, 13 July 2011 (UTC)
Thanks all for relocating this. Who knew a simple typo would cause so much trouble. Can I use the excuse of Adult Onset Dislexia?--T. Mazzei (talk) 22:56, 13 July 2011 (UTC)
While we're at it, a recently added .djvu has an extra space at the end we can do without. Can somebody with access over on Commons take care of it as well?
Latest comment: 13 years ago2 comments2 people in discussion
Hi,
Is it possible to save Wikisource books on my hard drive and read them offline? If so, what format would they be in? How do I do it?
Thanks.
—unsigned comment by99.249.87.80 (talk) .
There's a section in the side bar called "print/export". If you expand this, you can save a page as a PDF with the "Download as PDF" link. If you want more than one page, you can use the book tool by clicking the "Create a book" link (also in PDF). Note that neither will work with proofread books (those that use Index and Page namespaces). This is a known bug as has been reported. Apart from PDF, you could save the page as HTML with your browser or copy and paste the contents of a page into a text editor and save in your prefered format. Those options give greater control but they aren't as useful. There is discussion elsewhere on this page about enabling downloads in ePub format but this is not possible at the moment. - AdamBMorgan (talk) 16:20, 13 July 2011 (UTC)
Latest comment: 12 years ago30 comments5 people in discussion
Recently I ran a script that turned up many cross-namespace redirects. It was my intent to speedily delete them all, in accordance with our deletion policy. But upon analysing the list, I have found a great many cross-namespace redirects that are prima facie sensible.
Contrast this with the situation with E. E. Cummings:
If you type "E. E." into the search box you get offered nothing by search completion.
If you type "E. E. Cummings" into the search box you will be get back nothing but main namespace works by or about him. In order to find the author page at Author:Edward Estlin Cummings you have to tick the "Author" namespace and search again.
For me Author:Edward Estlin Cummings does not appear in the first twenty pages of Google results for a search on "E. E. Cummings"! I gave up searching at that point.
Frankly, the "no cross-namespace redirects" rule is starting to look rather absurd. It actively prevents our readers from finding what they are looking for.
I propose that we permit, nay, encourage, cross-namespace redirects from main namespace to the author and portal namespaces only. All other cross-namespace redirects will continue to be deletable on sight.
I always thought the primary focus of WS was to host qualified works & everything else found here beside those works are secondary at best to that primary goal. So if you're coming here to look up an author because you forgot the title - it makes sense that you'd need to jump through additional hoops to reach that title in that roundabout way wouldn't it? -- George Orwell III (talk) 04:34, 14 June 2012 (UTC)
Is the ability to easily find the author page I want really incompatible with the primary focus of this site being works? If so then I don't agree that works should be the primary focus — at least not in the manner that you envisage. Hesperian05:52, 14 June 2012 (UTC)
<shrug> makes no difference to me personally... but I don't see how elevating what amounts original research at this stage in our evolution to be, in effect, on par with mainspace works already lacking in the supporting scan area does anyone much good when all is said and done here. Besides, seems like we need to "fix" the way the two namespaces are being indexed (for search engine purposes) and not so much the long-standing practice itself. -- George Orwell III (talk) 06:25, 14 June 2012 (UTC)
I logged out, and did the search, I get the results that Hesperian does. When logged in I get the results billinghurst does. Seems to me making things easier to find is good. JeepdaySock (talk) 15:23, 14 June 2012 (UTC)
I tick the Author namespace and I get author names as I type in the search box. I un-tick it; the author namespace is no longer available on the fly in the search field. Same as always (or at least since I've been here). So is this a [default] search option in user preferences issue or still a need for cross-namespace redirects issue? -- George Orwell III (talk) 16:53, 14 June 2012 (UTC)
I logged out using a different computer then earlier, and still don't get the search in author name space. Do we have the ability to set the default to include author name space (new user and IP)? I don't know what happens when your logged in with a virgin account, but on IP it is not included. Jeepday (talk) 23:52, 14 June 2012 (UTC)
I'm sure it is possible to set a universal default (IP) preference but who or how escapes me at the moment. I'm sure somebody will be along with the answer. For virgin & logged in accounts, the Author namespace was a default search option last time I checked - maybe Portal should be one too? -- George Orwell III (talk) 00:08, 15 June 2012 (UTC)
Defaults for search are set in InitialiseSettings and are modified via bugzilla.
listing of namespace aliases and it shows that the default are main, author and index. This would equate with my non-logged in search
Author:Edward Estlin Cummings (redirect Author:E.e. cummings)
jpg | wikipedia E. E. Cummings | wikiquote E. E. Cummings | commons E. E. Cummings | commonscat Works : The New Art , 1915 in the Harvard ...
3 KB (317 words) - 11:13, 25 August 2011
Index:Seven Poems, E. E. Cummings, 1920.djvu
Type book | Title Seven Poems | Volume | Author Edward Estlin Cummings | Translator | Editor | School | Publisher The Dial | Address | ...
578 B (64 words) - 13:19, 3 August 2011
Index:Five Poems, E. E. Cummings, 1920.djvu
Type book | Title Five Poems | Volume | Author Edward Estlin Cummings | Translator | Editor | School | Publisher The Dial | Address | Year ...
424 B (41 words) - 11:31, 26 July 2011
Vision
Vision , poem by E. E. Cummings Howells, William Dean (1895), "Vision " in Stops of Various Quills . Vision , poem by John Masefield ...
417 B (38 words) - 13:38, 8 May 2012
Mist
Mist , a poem by E. E. Cummings The Mist , a poem by John Cowper Powys.
251 B (22 words) - 09:22, 10 January 2010
AH HA, I needed to take one more step. When logged in and you enter "e.e." auto complete shows you "Author:E.e. cummings" in the search window, when you are an IP, auto complete does not include author name space, (and there I stopped and made an ASSuM(E)ption. When you enter "e.e." as an IP and actually hit search, the first result is Author:Edward Estlin Cummings. So while not completely intuitive, the function is there. JeepdaySock (talk) 15:24, 15 June 2012 (UTC)
Now for portals, Portal:Centers for Medicare and Medicaid Services this is an existing portal. When as an IP I search for "CMS" or "Centers for Medicare and Medicaid Services" I don't find the portal in the results. Which matches billinghurst explanation. So maybe we should pursue adding portal? Given that we are being stricter about name space usage adding portal to default search might be a good choice. JeepdaySock (talk) 15:24, 15 June 2012 (UTC)
Comfortable with the addition of Portal, and there may be some thought to File:. What is weird is the discrepancies that I am seeing between searches, and I am not sure whether it is related to the skin, or related to the login. Examples
Ajax search, firefox, logged in, monobook modified options
Ajax search, chrome, not logged-in vector, default options
I get the same exact lists using the same crappy old IE6 browser when not-logged-in versus when logged-in - vector being the default skin in both cases - here. The obvious question is what do you get while logged-in under a vector skin default? -- George Orwell III (talk) 05:31, 16 June 2012 (UTC)
I found the issue, and it is soooooo brilliant. In preferences | search, if you have Enable enhanced search suggestions (Vector skin only) turned on, then it filters out the other namespaces, and just gives main ns. What a shame that monobook is so backward (not!) — billinghurstsDrewth07:35, 16 June 2012 (UTC)
Too funny! Still, it does go back my earlier point - the mainspace is the Main Space. Everything else is secondary to that space. So are we sure that option is disabled by default for both not-logged-in and logged-in new users for the sake of Hesp's point on "usefulness'? -- George Orwell III (talk) 07:57, 16 June 2012 (UTC)
Maybe someone could start an new account to check the setting? I nominate billinghurst, as the one who figured out the preferences setting impact would be be best to investigate and report on new account settings. Jeepday (talk) 12:06, 16 June 2012 (UTC)
Firstly, I have found that the text there is controlled in MediaWiki:Vector-simplesearch-preference, and note the phrase simple search which to me is significantly different from enhanced, so we may think about a change of wording there. — billinghurstsDrewth
Agreed. Something like Limit enhanced search suggestions to only the main article space (Vector skin only) would be my initial suggestion. Anything that correctly describes the functionality at work while still holding on to the distinction that there is a "normal" search feature and an "enhanced" search feature (depending on account creation, logging-in & user settings... [or not]) would be just as acceptable here. -- George Orwell III (talk) 21:39, 16 June 2012 (UTC)
"The mainspace is the main space" reads as a truism, but it is no more so than "a starfish is a star fish". "Mainspace" is merely the name we give to a namespace that is distinguished by the fact that its names are not qualified by a namespace name: a property that makes it an extremely convenient entry point. We're under no obligation to reserve the "mainspace" for content that we regard as "main", and the presence of content in the "mainspace" does not make it more "main" than content in any other namespace. It would be perfectly coherent, indeed elegant, for us to move all our works into a "Works:" namespace, and reserve the mainspace for redirects and disambiguation pages; i.e. navigational pages that map search terms onto our content.
All the other namespaces don't have source content - they have supplemental content or facilitate the presentation of content at best. You are saying, basically, the supplemental content is just as important or of the same regard as the works themselves. I say we host works first and foremost, if it has supplemental content; that's great, if not - oh well, I didn't expect Wikiliography @ Wikisource anyway. The same does not hold true in reverse, making it the default condition or the main objective (imho). -- George Orwell III (talk) 13:25, 16 June 2012 (UTC)
Of course not. The problem arises when anything and/or anybody winds up wanting a mainspace presence, be it redirect or otherwise, & what would be the parameters for inclusion or exclusion if that was the case.
The listings found on a mainspace disambig page point to works of a similar title also in the same main namespace so no problem here even though the page in question is supplemental in nature compared to real source works. -- George Orwell III (talk) 14:21, 16 June 2012 (UTC)
With regard to redirect or not to redirect, part of the matter includes the discussion about disambiguation; at Hesperian's encouragement we had stopped putting in disambiguation pages for authors and instead relying on the ==Works about== sections for such a listing. What are we going to do if we have a work called "E. E. Whatever" which takes precedence? The work or the redirect? If it applies for authors, does it apply to portals? Does it also apply from one other namespace to another? Would we still have a redirect? I am not yet sold that we want to create redirects for all authors in the main ns that point to author ns, compared with just making it damned easy for them to get the right search result. I see crinkles to which I don't have resolutions. — billinghurstsDrewth15:35, 16 June 2012 (UTC)
Additionally for consistency if we start making redirects from main space we will need to do it all the time, which would include searching for those authors/portals without redirects and adding them. That would be a body of work to keep updated, because a solution that only works part of the time is not a solution. Jeepday (talk) 20:52, 16 June 2012 (UTC)
That's not something I'd want to standardize into a policy and I don't think it would benefit the bulk of those new titles being added either. If a particularly relevant or popular Portal: or Author: wasn't lucky enough to have a cross-name-space hard-redirect created & then forgotten about years ago, then the only way that I can possibly see while moving forward to rectify such "injustices" today would be to create a new class of soft-redirects that sufficiently addresses the new concerns being raised here while remaining true to the premise of [cross] name-space integrity at the same time.
Call this new main-space place-holder banner an "enhanced redirect" or "featured redirect", have it explain the rationale behind having such an extra click-stop in a short blurb or two and design it to have its own maintenance and tracking independent of normal main-space works. A disambig page functions pretty much the same way already (though I loathe the impression disambigs give with its re-use of the basic main-space header personally) but the new class of soft-redirect shouldn't have anything linked to it internally from WS (preserves the practice of piped in-line wikilinking of author names, etc.). Goggle {hopefully) will not see any difference between a main-space title containing a hard-redirect or this new soft-redirect approach. We would in effect still be canceling out the pseudo-namespace prefixes without falsely furthering a main-space title across other name-spaces all at the same time. A case by case basis for selective application is also better justified, imo, this way opposed to adding & maintaining a hard-direct for every Portal: & Author we have. -- George Orwell III (talk) 23:07, 16 June 2012 (UTC)
Some excellent points have been made. Also some points that I could take issue with. But I think it is clear by now where consensus lies, and to argue the point beyond that risks a loss of congeniality for no gain. So I'll stand down on the redirects side of things. Thanks guys for your time and insights. I'm glad to see the progress on the search side. Hesperian00:46, 17 June 2012 (UTC)
Please see the Author pages discussion in Proposals section far above. It seems that the same desired search engine results might be possible without the need for using cross-namespace redirects to get around the Author: namespace prefix issue. -- George Orwell III (talk) 18:27, 1 July 2012 (UTC)
Reform Month 2012
Latest comment: 12 years ago11 comments7 people in discussion
Many of Wikisource's most visible pages—including the main page, policies, help pages, and template documentation—are inaccurate or misleading, sometimes woefully so, because they haven't been actively maintained. We're all busy doing the actual work of the project, but I think that the state of project pages is sometimes so confusing or unhelpful that it provides an unwelcoming experience for newbies (and oldbies who need guidance when trying something new).
The section just above this one is a good example of the type of improvement I would like to see us focus on in a new Wikisource:Reform month, which I tentatively put down for July. Some of those examples I quickly threw together aren't the best, but, mainly, I would like to have us, as a project, look over all the core policies and help pages for outdated, unclear, or missing information and rewriting/expanding would be the main task. Does this sound like a good idea? Maybe we could push back the proofread of the month in favor of Reform Month, promote it in the watchlist notice, and so on, to try to make it a real community effort? Dominic (talk) 17:40, 19 June 2012 (UTC)
I do think we're seriously failing in selling our wares and a lot of it is down to some basic problems.
The product is not visible on Google. I did a random test just now by Googling for "Bertrand Russell Why men fight", a title in Wikisource since 2008. I found the author page for Russell on page 7 of Google but didn't find the main page in the first 50 pages (I then gave up). Why should this be? Well an obvious reason is that the html title of the page "Why men fight - Wikisource" does not include the author's name, nor does it appear in any html header. That's a basic setup error.
The title above includes only the first chapter of a book with 8 chapters. Yet it is not marked as incomplete and it's very unlikely that any manual scan of WS would realise that and therefore that any action would ever be taken. It doesn't have any page scans, but I've come across many that do which are also not tagged. It also has no category information, except a copyright tag.
I agree totally with Dominic about the help files in particular and have started work in the last week on improving it. I've so far revamped the front page and 3 of the basic files and AdamBMorgan has contributed an excellent (though incomplete) set of beginner's files. But I'm a newbie here (WS has only become useful to me since the arrival of the EPUB download) and I'm learning how to handle the upload process before doing any more and making too many mistakes.
Whether the Reform Month idea is any good, I don't know. I haven't been around long enough. Certainly there does seem to be need for a few more bots checking basics. Chris55 (talk) 18:44, 19 June 2012 (UTC)
I'm not sure if it should displace POTM but it's not a bad idea to do something; it can be a real problem. I started the Beginner's Guide almost a year ago, and I'm still not close to finished, because there seemed to be a stage missing in the help files (it almost jumps straight to the intermediate level without a lot for novices). Lots of non-work pages get ignored: I think the Wikisource:Community portal is a little out of date; even Featured Texts (a main page element) doesn't get a lot of attention, which is why we are repeating the 2010 June FT at the moment; I've just updated Help:Adding texts because the method it described (straight copy-and-paste) was not the one that is currently preferred; and so forth. To add to the suggestions, I've had a vague plan to write a bunch of essays for the Wikisource namespace to cover suggestions and assorted practices, but I've haven't done much yet. Lots of stuff comes up in Scriptorium but isn't repeated anywhere formal (and Wikisource is a fairly policy-light project). I thought essays were the best solution and keeping them in the Wikisource namespace encourages other people to update them when needed. - AdamBMorgan (talk) 23:06, 19 June 2012 (UTC)
Dom has a fair point, and I say this as someone who still feels a newb here despite 80K edits. I see WS as a Cinderella (not that I would ever call Commons "ugly", at least within earshot of a Commoner). Basically WP, Commons and WS should work closely together, and I have called attention to WS as "Reference Commons" in a lecture (WMUK AGM 2010). The answers to low Google rank would be several, but starting as a mirror site into which much text was copied implies a penalty in that quarter.
No fairy godmother in sight. But WS could do stuff for its self-esteem, as proposed. It could legitimately do more to add keywords for search engines. E.g. the DNB pages use name inversion, and the "little sister" template for WP links hides the name of the WP article. Fine as a piece of chaste design: perhaps rather than question that, we should be using the notes field systematically. (People searching for "John Smith" as exact phrase will not necessarily find the three dozen DNB Smith, John pages that way.) More hypertext work here, within our "light annotation" convention, should proceed. And (third theme) there could be better documentation of e.g. templates. I have done template stuff that has been reverted by others, and I assume AGF all round: but better communications on that would be an example of making the inner workings of the site more transparent. Charles Matthews (talk) 05:28, 20 June 2012 (UTC)
All above look like fair assessments and good points. The tasks are not easy, I doubt that everything on Wikisource:Reform month could be done in a month. Maybe make it monthly event next to WS:PotM and pick a different area each month. Some areas may need to be brought through more then once. JeepdaySock (talk) 15:13, 20 June 2012 (UTC)
Obviously the "Reform Month 2012" thing is a bit of a gimmick, and I'm not overly attached to it as a model. I'm game for any suggestion, like yours, which aims to bring more attention to these areas. Dominic (talk) 19:11, 21 June 2012 (UTC)
I like the idea of a montly event for improving documentation like PoTD (although I wouldn't want to advertise it on the main page). If we go that direction, it would make the most sense to assign assesment as the task for July. It would be most effective to approach this systematicaly. Rate importance and quality 1-5, which would give a worthiness of attention percentage. Improving marketing is another story. Not that I disagree with any of the above suggestions, but I don't think it would very useful to combine the two issues into one initiative.BirgitteSB02:33, 22 June 2012 (UTC)
If this is to be an ongoing project, should it be co-ordinated at another page, such as Wikisource:Reform of the Month or Wikisource:Maintenance of the Month? Having a definite point of reference can help decide what tasks need to be done and when to do them. If we assess tasks, I would add an estimate of how large the tasks may be (how long they will take), to judge whether a month is too long or too short a time. Some of them could then be grouped or split up as appropriate.
In the mean time, I've tried to improve a few things on the existing list. Help:Adding texts now refers to proofreading rather than copy-and-paste works and I've added the essay Wikisource:DjVu vs. PDF to try to explain a few things about the formats. The latter, especially, could probably be improved by someone who knows more about the subject but I think it's a good enough start. - AdamBMorgan (talk) 22:33, 24 June 2012 (UTC)
I like Wikisource:Maintenance of the Month, There are two main challenges, without the first occurring there is little chance the second will.
Somebody has to take the lead, and operate the project. Keeping it up to date, and suggesting or deciding what the next project will be.
The project has capture the interest of the volunteers to actually work on improving the selected item.
I've been waiting for someone else to volunteer. If no one else does soon, I can kick it off at least. I think it's a good idea, something that would be useful and generally something good to have. However, human resources is not my forté; I'm probably not the best for this. There is a risk that the page gets started and nothing happens. - AdamBMorgan (talk) 23:28, 29 June 2012 (UTC)
Adam I think you will be a great person to get this started. Worst that can happen is nothing, anything else can only be an improvement. Hopefully as things get rolling, some of our newer members will begin taking a more active roll in the project. Jeepday (talk) 12:53, 4 July 2012 (UTC)
Special:Upload
Latest comment: 12 years ago14 comments5 people in discussion
I notice from Wikisource:Image guidelines that it is policy to upload all files to Commons not Wikisource: "Images should be uploaded to the Wikimedia Commons (see the Commons upload page)". I'm therefore surprised that. afaics, the Special:Upload does not either encourage or enable people to do this. Should there not at the very least be a statement and link right at the top? Looking back at the archived discussions I can't see any discussion of this since 2006 and that was inconclusive. Not doubt oldies have their links set up but newbies are left floundering. Chris55 (talk) 13:13, 22 June 2012 (UTC)
Well, there is a MediaWiki:Uploadtext (big stop sign) at the top. :-) But it's a good point regardless, since it hasn't seemed to have actually stopped uploads. And we don't seem to be very good at actively monitoring the image space. Commons has both the structure for policing copyright as well as the array of licensing tags that we don't. A quick check of recent uploads shows some egregious examples of copyright problems (e.g. File:672.jpg and File:A view from afar off ebook.pdf) and many images missing any copyright or source information at all; these would have been flagged immediately on Commons. There are some legitimate uses of local upload though, see Template:Do not move to Commons. Other projects have taken steps to enforce upload policies through the software, by either completely turning off uploads or restricting them admins or a new uploader usergroup (see Commons:Turning off local uploads). I would favor that solution. Dominic (talk) 16:22, 22 June 2012 (UTC)
Well there might be a stop sign on your screen, but there isn't on mine! There's absolutely no sign. Maybe that's why it's all happening. Neither do I get one if I try to upload an image when editing a file. I don't know how things appear to different classes of users but there's a problem somewhere. Chris55 (talk) 19:56, 22 June 2012 (UTC)
Because we have only one copyright restriction — public domain in the US — rather than a double restriction — public domain in the US and home country — we therefore are required to have upload available. Unusual that you cannot see the messagebox, if you view the "big stop sign" page above do you see it? Because after that it is a transclusion and if you cannot see that, I wonder what else you cannot see. In recent times, we have not been having much uploaded, though I will admit that I have done less in general patrolling in the past while. — billinghurstsDrewth22:39, 22 June 2012 (UTC)
I too have a note or two in my inbox recently about "... something has changed - images inconsistent....". Turns out they were "mobile" now (a letter "m" in the WS url) and it seems images don't always act like they do online from a desktop. Could that be Chris55's situation? -- George Orwell III (talk) 01:01, 23 June 2012 (UTC)
Are you saying that you are being presented with the mobile presentation (mobile url) when not in a mobile facility. Sounds like a bugzilla is required! Mu understanding of mobile is that it is without images, however, I am not all around it. A good place to look and to ask is via m:Mobile_Projects — billinghurstsDrewth
No I am saying only idiots who don't bother to scroll wayyyy down to the bottom and tick 'Images' back on have my email address. They expected the same behavior for both worlds when off [I believe] is the the default for mobile. -- 06:26, 23 June 2012 (UTC)
Supplementary squared: I have added [MediaWiki:Editnotice-6] which appears in all edit pages in File: namespace, requesting that th {{information}} text be completed. I would welcome review and improvements
wikisource upload screen as seen by chris55 at 23/6/12
Billinghurst, I see the stop sign when I click on [MediaWiki:Uploadtext] but it certainly isn't transcluded into Special:Upload and that link is on almost every page I visit on WS. Chris55 (talk) 08:24, 23 June 2012 (UTC)
In answer to George Orwell III, I'm not using the mobile version. I am using the Vector skin but that doesn't seem to make any difference. Nor can I see any other preferences that might affect it. Chris55 (talk) 11:29, 23 June 2012 (UTC)
FINALLY, with Eliyahu's help, I've figured out what was wrong. It all came down to selecting EN-GB British English as my default language in Preferences! When I select EN - English, everything's fine. I'll leave him to fix it. And I'm ok with that. I can understand American;-) Chris55 (talk) 09:03, 5 July 2012 (UTC)
I have solved this specific issue by creating [MediaWiki:Uploadtext/en-gb] and having it transclude [MediaWiki:Uploadtext]. I suppose this is something we need to be aware of, though it would of course be difficult to maintain all needed messages for all languages. I think we need to create a template for use in the MediaWiki namespace which identifies certain languages and says, "If you make an important change to this page, please try to ensure that these other language versions are also updated accordingly." --EliyakT·C16:15, 5 July 2012 (UTC)
Yes, because your other fix (to the Author: presentation) doesn't show up with en-gb set. (And how many other subtle differences?) Chris55 (talk) 11:25, 6 July 2012 (UTC)
Tag filters
Latest comment: 12 years ago5 comments3 people in discussion
If a user can request a Tag filter to be added to the Special:Tags collection, then I request a filter be created for proofread pages but not validated.— Ineuw talk14:27, 27 June 2012 (UTC)
Not exactly. I am looking for a 'tag filter' that anyone can use in the User contributions page. For example: By specifying the user name, the namespace, and a 'tag filter' to display pages that have been proofread, but NOT validated. Is this possible to be added to the Special:Tags collection for anyone to use? — Ineuw talk02:05, 29 June 2012 (UTC)
In some respects it's kicking the can down the road, but there's a field in the Index where you can input desired scan resolution in edit mode. I've populated it with the working value you provided and it now works for me. Prosody (talk) 18:07, 28 June 2012 (UTC)
FWIW, I found a page on the MediaWiki docs referencing the error message. It's a problem of one of the programs in the conversion/thumbnailing chain using too much memory, and as such there aren't really any good solutions (I guess we could convince the WM devs to up the limit beyond any conceivable need, but, uh...). Identifying and fixing works with this problem with the per-work fix above seems like the best we can do. Prosody (talk) 18:27, 28 June 2012 (UTC)
The project (A Dictionary of the Sunda language) is now completely proofread. More validation and presentation to be done. There have been about 40 contributors brought into Wikisource for the first time who will be "active" on the English Wikisource stats, and also a few who will be considered "very active" this month. The Wikimedia Indonesia project team are complaining that this was too successful (too many participants and they finished the initial proofreading earlier than expected). We are now scanning a Sundanese text, and looking for suitable Indonesian texts to scan and transcribe (finding PD non-fiction texts in Indonesian language is hard). John Vandenberg(chat)13:45, 12 July 2012 (UTC)
You might also want to search under "Malay language", because that's what Indonesian language are generally referred to prior to 1945 (even though some might argue that the birth of Indonesian language is 1928), plus, the working language at that era was Dutch, which almost none of younger generation familiar with. Bennylin (talk)
Using smart phone
Latest comment: 12 years ago2 comments2 people in discussion
I use a smart phone, moon+reader.
The moon+reader's Internet Library have the project guntenberg. But not Wikisource.
I can see A Study in Scarlet at Project Guntenberg.
I can see A Study in Scarlet at Wikisource, also.
So, I understand "Wikisource = Project Guntenberg"
Wikisource and Project Gutenberg are different web sites. I don't think Moon+ Reader supports Wikisource, and we can't do anything about it. Maybe if you contact the developer of Moon+ they can add support for Wikisource. An contact email is listed at the bottom of the Moon+ Reader website. Prosody (talk) 23:00, 1 July 2012 (UTC)
Tact needed
Latest comment: 12 years ago4 comments3 people in discussion
I undid some edits from a User that I took to be spamming; but in hindsight, it would probably have been better to place a note on their Talk page to let them know that 'self-advertising'—to a certain extent—can best be done on their User page. Better left to someone with tools and tact! :) Thanks, Londonjackbooks (talk) 12:21, 4 July 2012 (UTC)
Thanks for handling this well. The user is part of a WMID competition, and they are required to give the host community project (i.e. en.ws) a short bio and indicate they are part of the WMID competition so the community knows who to blame if their contribs are problematic. John Vandenberg(chat)01:46, 7 July 2012 (UTC)
A database query syntax error has occurred
Latest comment: 12 years ago3 comments2 people in discussion
Ho hum it happened on this page before when I tried to add a section header it seems that it did add he section error even though it gave that same message. The problem now seems to have gone away. -- Philip Baird Shearer (talk) 14:29, 5 July 2012 (UTC)
Global issue. DB issues that have been occurring and staff were looking to resolve by fixing sql configuration. Message at wikimedia-tech irc channel says Status: UP - parsercache disabled (bugzilla:38202) — billinghurstsDrewth02:28, 6 July 2012 (UTC)
Facebook page
Latest comment: 12 years ago27 comments8 people in discussion
I am thinking along the lines of promoting WS and increasing visibility (search and otherwise), and want to suggest that we add Facebook to our toolset towards these ends. There is a facebook page already (with a measly 121 likes). (BTW does anyone know who runs the page?) Some things that come to mind are updates, for example regarding the PotM; and maybe advertising to people with related interests (requires a money-bearing member of WMF). Any other ideas? --EliyakT·C05:46, 6 July 2012 (UTC)
I think it could work (although do you mean working with/taking over the existing Facebook page or creating a new one?). Other ideas along similar lines: Could we set up pages on sites like Tumblr? Also, perhaps social networking links could be added to pages? I know this has been rejected on Wikipedia but Wikinews does it. It might be an easy way to get links to our works out on to the wider internet (or at least make it easier for people to do so). I am not strongly in favour of either but I think it's worth making the suggestions. - AdamBMorgan (talk) 13:10, 6 July 2012 (UTC)
I do not want my name on Facebook. I am familiar with Facebook. IF we connect to Facebook I respectfully request an alias of my choice. Otherwise, I like the idea of promoting WS on Facebook. William Maury Morris II (talk) 13:38, 6 July 2012 (UTC)
I don't think there is any need to have any user names on Facebook. When a page is used, the admin can post "as" the page, so it appears that the post was written by "Wikisource." I think the current Facebook page has some good content, and it would be good to work alongside the current admin. (also it owns the facebook.com/Wikisource vanity URL.) I think a good approach would be to appoint FB admins via a similar process to the current Admin vetting (all WS admins need not be FB admins and vice versa), and to have a Wikisource:WikiProject Facebook page with guidelines & suggestions for types of FB posts. With a few admins, the workload can be distributed enough so that there is no strain on any one person to keep up the frequency of posting. --EliyakT·C14:21, 6 July 2012 (UTC)
I went to the link show above (I am already on Facebook) and it indeed is awesome with just what little is there now. I noted that "Index:Life of Octavia Hill as told in her letters.djvu" is shown there among others. This really would be fantastic and the only drawback I see now is that I had to search for the English version of WS on FB. I was amazed at how many other nations participate and not only participate but participate a lot. I never roam from enWS except for esWS so I had no awareness how much others in other nations are doing as we do here. It's impressive and really gives the feeling of "International" which I do not get here. Here it seems as though everyone is in the USA although I knew a few aren't. FB is a great way to advertise Wikisource and someone is doing it whether we get involved or not. I was initially concerned because I have family and friends on Facebook, my real name, and photographs. I nominate AdamBMorgan to represent WS on FB because I have learned over a long period of time that I can trust him. William Maury Morris II (talk) 14:43, 6 July 2012 (UTC)
How would "y'all" (ya'll?) set this up? From what I saw it was very special but then there are so many nations involved. Aside from that "mailing-L" list it looks confusing to find and navigate only in the English section. One of the things I have always liked is reading short *summaries of books*. We don't have that on WS but we could have it on enWSFB. Eliyak, I second your nomination by AdamBMorgan. William Maury Morris II (talk) 03:50, 8 July 2012 (UTC)
I would think the various Wikisources can each have their own WikiProject Facebook (I will hold off on actually creating the WS-en page until I hear from LA2). Facebook pages have a very interesting feature I just became aware of - posts can be targeted to those who speak a particular language! This is very exciting, because it means that the various language Wikisources can post on the same FB page, as long as they target their posts to speakers of that language. Multi-language posts would be cumbersome (and require a polyglot), and posts in various languages would cause people to hide WS from their news feeds. This is an excellent solution (thanks anonymous FB programmer). There are certain details which will need to be determined in practice (do the targeting settings need to be set once per user, or each time a post is made?) Certain general posts might still be targeted to everyone, and would probably be in English, that being the most international language. --EliyakT·C06:16, 8 July 2012 (UTC)
If LA2 does not respond, what happens to the existing facebook page? Can we as a community reclaim it? If Eliyak creates a new facebbok page, how does control of the page transfer to someone else in the community if Eliyak disappears? Jeepday (talk) 10:40, 8 July 2012 (UTC)
The facebook page has many admins (me included); unless we all die together in some freak virtual-book-virus outbreak, we should be fine. I'm happy to give FB adminhood to anyone here who is sane and a bit FB savvy. John Vandenberg(chat)13:34, 12 July 2012 (UTC)
Facebook (and Google+) pages work a little differently than Twitter. It is possible to appoint multiple "managers", as well as multiple "content creators". The managers all have absolute control over the page, while content creators can post. I would only appoint very trusted users as managers, since those users would in have the ability to "self-destruct" the page by either taking it over entirely or deleting it. I think we would want 3 of these managers for redundancy in case of the absence of 1 or 2. I am not as familiar with Google+ pages, but I know there can also be multiple managers.
Our Twitter profile seems to be occupied by "dr.nate" and we will need to contact WMF to get help getting this account recovered for our own use. Also, wikisource@gmail.com is taken by someone(?). I had wanted to use that email for social media logins where necessary. Instead I created wikisource.social@gmail.com. I will gladly make the password available (see also next paragraph).
I think we should get started appointing trusted users to Social Media Manager roles. I originally thought to make these rights and information available to all admins, but I know we have had occasional trouble with admins in the past, and don't want to enter a situation where something irrevocable might be done with the social media manager powers. Therefore I am suggesting that the social media manager role be given by vote, only when there are at least 8 unanimous votes in favor. --EliyakT·C17:08, 8 July 2012 (UTC)
I have nominated myself as the first manager. (I already have control of a new Google+ page, but will gladly relinquish it if I am not duly appointed.) I kindly request at least two additional self-nominations to the social media manager role. --EliyakT·C17:24, 8 July 2012 (UTC)
To note that both Stewards and CheckUsers have wikis available where passwords can be stored for future recall as needed. Not saying that you should, just that it is a potential. — billinghurstsDrewth17:28, 8 July 2012 (UTC)
I like Wikisource:Social media as the project name. If we have 3 users assigned to each media (same or different) and/or give the Stewards/CheckUsers the password (keep it updated with changes) that should address my concerns about ongoing management. In practice it would essentially add a requirement that a Steward or CheckUser be one of the assigned users to the media (need not actively generate content, but should provide over-site). Admins can be anonymous users but I believe both stewards and check user require ID verification. So that give some security, though I am note sure how you could recover if one of the team went rouge and changed the password. JeepdaySock (talk) 15:35, 9 July 2012 (UTC)
I made the project page the other day at Wikisource:WikiProject Social media, containing some basic info. I think everyone involved in this conversation should meet the criteria to be a social media "manager," so please go nominate yourselves and/or vote for managers so that we can get this project started. We may also want to add a watchlist notice so that we can make it to the voting threshold more quickly. --EliyakT·C17:12, 9 July 2012 (UTC)
"Users with disciplinary history should not be made contributors." I emphatically disagree with that statement if it includes a situation I got into here. I have proven myself worthy in work since about 1969 here on WS and I have completed several books. I would like to know my position in this ASAP. Aside from that has anyone looked up "gutenberg" on FB? It does exceedingly well and one of the areas I liked was an area on Gutenberg's New Books. After browsing, one can easily spot the "new books" completed in this specific area. Gutenberg does not have the image beside text shown on its pages so WS has an advantage there. Eliyak, do you know the format that WS will have on FB? How soon can you get started? Kind regards, William Maury Morris II (talk) 18:23, 9 July 2012 (UTC)
By disciplinary history I meant users who had been locally or globally blocked, banned, or otherwise disciplined. I didn't mean that they were involved in a dispute or investigation which resulted in no action taken. I should clarify that, thank you. --EliyakT·C18:49, 9 July 2012 (UTC)
Project Gutenberg has a separate page just for new texts. I would suggest we start with a single page. I see that there is an app we can add a RSS feed. See this example facebook page to see how it would look (note the "New Works" button. --EliyakT·C20:24, 9 July 2012 (UTC)
I think it looks very good. I also like the idea of a seperate page for New Texts. What often concerns me is any serious confusion of paths to follow as one roams a library that looks more like a maze than being orderly and easy to understand. Perhaps we should use the Dewey (sp) decimal system. A very serious part is the introduction or "About us". People glance at things, they will not stay long, so in that there has to be something (image) that really catches the eye. My son owned an ISP (Cornerstone Networks (Va.) with connections all the way to Washington state where I was living at that time)for many years and made big money when he sold it to the local telephone company so I learned that people will glance at something only a few seconds and leave if there is not something good to "catch the eye." The WS "Iceberg" catches my eye! It is a fact before my eyes that 3/4 of an iceberg is underwater as that image shows. Kind regards, William Maury Morris II (talk) 20:51, 9 July 2012 (UTC)
I nominate Chris55 talk because he is a fantastic organizer from the beginning as attested to here on WS. Naturally, he can decline but excellent people are needed to get WS on FB started and they need not continue if so desired once WS on FB is organized and underway. It can be a short-term work for WS just to get it organized and underway. I will gladly contribute with what I can. I have always felt that WS was not known to most people and that it needed, and still needs, to be known to the people. They need to know it exists! Respectfully, William Maury Morris II (talk) 19:58, 9 July 2012 (UTC)
I also like Wikisource:Social media for the name. I see no reason to have the word "project" in the name. I ask, why should "project" be in the name? I wish this could get started soon. It's frustrating knowing there is already activity well underway for WS on FB as well as Project Gutenberg which is doing exceedingly well. I don't care about being a manager but I would like to see us begin on this. I was once an administrator on a talk list and there were 4 of us as administrators. We use names admin1, admin2, admin3, admin4, and came in to work when we could. By using the names shown and taking one that wasn't being used, we thereby alternated so that posters to the list never knew which administrators were online. Sometimes I would be #2, #4, #3 &c -- whichever one I chose that wasn't being used. It worked. Problems were cast aside without people knowing who to curse elsewhere. Not even I know the other 3 administrators nor did they know me. The head administrator took care of that. For 400+ people online the process worked well. Whatever the name of this project is going to be it should be kept short and basic. Not everyone knows what "wikisource" is much less by adding to WS itself. I have also worked as a administrator(owner) and "SigOp" on BBS's in the days before people knew what "Internet" meant. Computers are addictive! I already have a special name and special email for WS on FB William Maury Morris II (talk) 04:35, 11 July 2012 (UTC)
I haven't heard back from him. (I tried via email) Could you have him send me an email or tell us the best way to be in touch? Thanks Birgitte. --EliyakT·C16:30, 13 July 2012 (UTC)
javascript workaround for edit page image failure
Latest comment: 12 years ago1 comment1 person in discussion
For those who dabble in javascript and are as frustrated as I am at the ongoing problems with edit page images failing to display, the following function replaces the page thumb with the same image at half the size. Just hook it to a button in whatever framework you're using, and you're good to go.
It can be invoked more than once if necessary, but so far for me a single call has not failed to fix the problem.
function halve(){
var thumbElement = document.getElementById("ProofReadImage");
if (thumbElement == null) return;
var match = thumbElement.src.match(/-([0-9]+)px/);
if (match == null) return;
thumbElement.src = thumbElement.src.replace(match[0], "-"+(match[1]/2)+"px");
}
(Yes, I know it will break if pointed at a page with "-1000px" in the title. Go ahead and fix it if you care that much....)
Latest comment: 12 years ago6 comments5 people in discussion
I've started working on transcribing the Pentagon Papers. While working on the Index pages, I've discovered that it contains memos and the like that include handwritten notes (such as Page:Pentagon-Papers-Index.djvu/4). I'm planning to insert images of the signatures, but I wasn't sure how best to denote when text is handwritten. Furthermore, there's a page that consists of a memo with circled/struck-out bits. I've formatted it like so, but I was wondering if there's a better way to go about it.
Sorry if I'm missing anything; I searched for any discussion on the matter, but found little. It appears that some proofreaders are using formatting like (handwritten), though it seems like it would be hard to denote where the handwriting begins and ends. I rather like the suggestion at Index talk:The Origins of Totalitarianism.djvu of using grey text color, though I don't know if people would be opposed to forcing a text color. Thoughts? – GorillaWarfare(talk)20:06, 7 July 2012 (UTC)
In the past I've used {{popup note}}. The dotted underline doesn't seem too conspicuous and the hover text makes it clear to someone just reading the transcluded main namespace text that it's handwritten. Prosody (talk) 20:12, 7 July 2012 (UTC)
I'm with Prosody on this one. It is the best overall solution that I've seen in use to date as well. I'd italicize the handwritten text even when it is in print letters just to give it that extra slight diferentiation from the typed text, but that is just my personal preference. Also, you might want to take a look at {{SigR}} & {{SigL}} to see if they are any help to you when it comes to images & signatures. -- George Orwell III (talk) 23:07, 7 July 2012 (UTC)
How the work is annotated can depend on a number of things especially in the context of the annotation and/or who made annotation. Really is a "horses for courses" approach. You can also look to use an in situ grouped reference that can be headed something like "Handwritten annotations" that clumps them at the end of the work. — billinghurstsDrewth13:06, 8 July 2012 (UTC)
History of Parliament: The Commons 1790-1820 crown copyright question
Latest comment: 12 years ago5 comments3 people in discussion
History of Parliament: The Commons 1754-1790 was first published 1964 by Her Majesty's Stationery Office under crown copyright. If I understand correctly that means it will fall into public domain 50 years after publication. Does that mean that i can upload it 1914? --P. S. Burton (talk) 10:23, 8 July 2012 (UTC)
Bit of a tricky one, and probably worth asking the owners of the copyright, or finding someone who knows the work and can do some research into its publication. It may be 50, or it may be 70 years, as crown copyright and how the British Government's handling of such has variance depending on the work and the circumstances of its publishing, the changes in the 1988 Act may indicate that as this is a history where the author assigned the copyright to the Crown (as per last sentence at w:Crown_copyright#United_Kingdom). — billinghurstsDrewth13:00, 8 July 2012 (UTC)
Thanks. Tricky indeed. However I think that their is a chance that the work will be pd 2014. "A document is Crown copyright if it is made by . . . an officer or servant of the Crown in the course of his duties. This means that the Crown holds copyright in documents of any date created by, for example: civil servants, serving forces personnel, most court staff and so on. The Crown also holds copyright in works which it has commissioned and where it has had an influence in the work’s creation. If a work has been commissioned by the Crown and has then been prepared independent of it, copyright will reside with the author unless the work is first published by the Crown."[13] Anyhow I will have plenty of time before that to find out.—P. S. Burton (talk) 14:54, 8 July 2012 (UTC)
1964 works come PD in 2015 (where fifty years is the rule) as copyright dates are like horses' birthdays—all fall on the same day—which for books is 1 Jan the year following publication. Re the author and their occupation, yes, BUT, you will need to see what it says at the commencement of the work, and there may have even been a commercial contract, none of which should be taken for granted. PRO should have something, and worthwhile running a check through A2A to see. First of all, find out who was the author. Never presume. — billinghurstsDrewth18:05, 8 July 2012 (UTC)
An odd instance of the Millennium Bug appears to have struck this thread. I believe previous comments may have meant 2014 and 2015. Otherwise copyright is even more complicated than I thought. :) - AdamBMorgan (talk) 00:42, 9 July 2012 (UTC)
Advice / help wanted - British Official History of World War I
Latest comment: 12 years ago5 comments4 people in discussion
Dear all, a question for you! Wikimedia UK is currently running a number of activities related to World War I and the forthcoming centenary. One of our ideas is to digitise the British Official History of World War I, which is out of copyright but doesn't seem to be freely available yet. This is quite a large project - there are 14 volumes for the Western Front itself, plus 5 cases of maps. Here are a few questions I thought you might be able to help me with:
I see Help:DjVu files suggests using DjVuLibre or Any2DJVu to create DjVus with OCR layers. How time-consuming is it likely to be to do this with 14 700-page books, and do you expect we'd run into any technical hitches on the way?
Will the OCR layers produced by these services be as good as the OCRs produced by commercial digitisation services?
Is there anyone active on Wikisource who thinks this is a cool idea they'd love to get involved with? If so, please shout :-)
Sounds interesting, and a good opportunity for Wikisource too. In my opinion:
I would actually recommend uploading the page scans to the Internet Archive. They then generate DjVu files (as well as PDF etc) with OCR layers.
No. A commercial service (or the aforementioned Internet Archive) will have better OCR software.
I'm interested.
NB: Getting all 28 volumes proofread in time might be tricky, even with two years to work on it. Will Wikimedia UK be promoting this at all? - AdamBMorgan (talk) 22:42, 8 July 2012 (UTC)
This is interesting and a quick scan of Google books and the Internet Archive suggests that the scans of "History of the Great War Based on Official Documents" have not been done, publically at least. That in itself is a big job for which you might need to involve Google or some other large body's help.
I recently added a category to the Wikisource's Portal:Poetry for WWI poetry which includes a huge range from the Prince of Wales 1914 collection to Wilfred Owen. Maybe we need a range of sources, to take account of John Keegan comment about the above: "the compilers... have achieved the remarkable feat of writing an exhaustive account of one of the world's greatest tragedies without the display of any emotion at all." Chris55 (talk) 23:25, 8 July 2012 (UTC)
Thanks both! Chris - just to clarify - we would arrange for the digitised (at least of the Western Front volumes, which are on someone's bookshelf). There is already a digitized version but the publishers of the digitisation assert copyright over the digitized volumes. But the work is important enough that we can pay for it to be scanned in.
Any idea how good the Internet Archive's OCR is? If there's any advantage to doing it, we might as well upload it there as well as Commons. The digitised text is still of very great value as a WWI resource even if it isn't all present on Wikisource.
That said, it would certainly be interesting getting it all proofread in time - I can definitely see Wikimedia UK arranging a few "proofreadathons", and the project is the kind of thing that could potentially attract a few new Wikisourcians! The Land (talk) 18:12, 9 July 2012 (UTC)
I would have thought that there are numbers of UK universities that would have assisted in the scanning, or even someone like http://www.british-history.ac.uk. In all these cases it is to ensure that you get the scans as high quality graphics. FWIW, in all these bits, I will help, though wouldn't commit to more. There are numbers of ways that we can systematically help, 1) we would look to set up this as a project and add it to {{active projects}}, 2) I would recommend that we look to have one volume done in the proofread of the month, 3) After a PotM time, we have the project as a feature similar to the NARA records. To note that it won't be quick, and it will need someone to coordinate and spruik, though once you get the vols going, it will progress. If there are lots of maps, then doing a similar type project approach at Commons will be useful. Image processing takes time. I have the contact details for someone at IA, I will drop that to you via email. — billinghurstsDrewth14:30, 10 July 2012 (UTC)
Wikisource:Adminship
Latest comment: 12 years ago1 comment1 person in discussion
Wikisource is for the most part a very friendly place. We have a number of regular volunteers who more then meet the requirements for adminship who have not yet made the leap. You don't have to know everything, or be a techno geek, just meet some easy criteria. While we do have annual confirmation it mostly just a matter of is the person still active, default is to keep. Take a look at current Confirmation discussions unless your dead (and maybe even then, for the first year anyhow) we would like to keep you as an admin. There are no required duties, there are no scheduled times to be active, it is just the community saying we have been working with this person for while and they "are known in the community and whose edits and contributions have proven trustworthy". If you are not an admin and want to be one, talk to me or anyone at Wikisource:Administrators (try to pick a live one :). If you can think of a non-admin you have been interacting with whose "edits and contributions have proven trustworthy" talk to them about it. You can nominate yourself or some else (with their permission). I personally like to nominate admins, so if your at all nervous about nominating yourself, let me know. JeepdaySock (talk) 16:04, 9 July 2012 (UTC)
value of money
Latest comment: 12 years ago6 comments3 people in discussion
If it were an Australian dollar something would be amiss because they use the British monetary system of pounds, stirling, sixpence, and a farthing or two. Perhaps these days they use the "Euro" and I forgive those fellows for driving on the wrong side of the road. :0)
Latest comment: 12 years ago3 comments2 people in discussion
In the course of trying to improve Help:Searching I installed a Wikisource search engine plugin for Firefox which I found via Mycroft. It's marked as being from Opensearch.org but "This plugin/provider has not been verified" and I couldn't find it there. It's credited to Charles Nadolski and seems to work fine but I don't want to document it until it's confirmed (e.g. does it work in IE and Chrome?). Anyone know anything about it? Chris55 (talk) 10:26, 10 July 2012 (UTC)
Chris55, the search engine you placed on the Portal:Southern Historical Society Papers works very well with IE8 & Firefox 13.0.1 both of which I use. Aside from that, I admire other work I have seen that you did. Respectfully, Maury (William Maury Morris II (talk) 13:48, 12 July 2012 (UTC)
Thanks. Billinghurst has pointed out a problem with content where pages are transcluded into the main space. This is the subject of a bug report to mediawiki and means that you don't get all the results you should, but it seems to be better than nothing and will hopefully be resolved. Chris55 (talk) 11:04, 14 July 2012 (UTC)
Keyboard shortcuts
Latest comment: 12 years ago9 comments4 people in discussion
On My Preferences there is a gadget on editing tools, "Keyboard shortcuts to type special characters (works in Firefox, Chrome). [example : ^ae -> æ ]", I have looked around a little and I am not finding a list of what those shortcuts might be. Does anyone know where a list of them can be found?JeepdaySock (talk) 14:51, 13 July 2012 (UTC)
Thanks, I added a hyper link to the listing. I was thinking about using this gadget for Macrons on Latin for beginners but, Macrons are not part of the code and after looking and thinking about it not sure they would be a good choice as the obvious short cut would be case "-a" : m = "ā"; break;, and I am not sure that would be helpful as Latin for beginners and many other works are full of hyphenated characters that don't want to be converted to macrons. Clearly I have never used the gadget and am clueless so don't hesitate to point out if I am missing the obvious. Jeepday (talk) 09:44, 14 July 2012 (UTC)
I could see issues with the pipe, and I am to lazy for _a, but I like the =a. Can we try the =a format and see if anyone has a problem? Can you make the changes? macron's ā Ā ē Ē ī Ī ō Ō ū Ū ȳ Ȳ. Jeepday (talk) 23:39, 14 July 2012 (UTC)
Don't forget Category:Diacritic templates. For most of the needed I just do something like {{subst:a:}} to get ä. I just created a subst: button for my toolbar to make it easier. Plus if other use the diacritics and leave them in place as {{a:}}, no worries as every so often I run a bot through to explode them, it is a pretty easy task. — billinghurstsDrewth15:19, 15 July 2012 (UTC)
Bloody good quality scans, this is a beaut. Now we just need to work out how to capture the images. Anyone got the skills? Clues? Tools?
Sadly, Google does not seem to want them downloaded. And, they are serving the high-resolution images in square pieces, a la Google Maps. It would seem not to be possible at this time. But, maybe someone has a way. --EliyakT·C14:59, 15 July 2012 (UTC)
I agree with what Eliyak has stated but if there is an excellent article it can always be typed out. Any important image can probably be taken by a screen-shot. It isn't set so that you can have a large image of one page. If you shrink the pages they lose resolution. William Maury Morris II (talk) 15:15, 15 July 2012 (UTC)
Wow. Everything I looked at content-wise was crisp and clear... nicely done indeed. I question if we really want to try and host some of those pages though - they seem too large for anything but coordinate mapping and block-by-block viewing. That grayscale background layer would make conversions to djvu a real pain in most cases. -- George Orwell III (talk) 17:08, 15 July 2012 (UTC)
From the help FAQ: "News Archive Search does not currently offer a direct way to download or print articles, pages, or pictures from digitized newspapers included in our index." Hesperian00:52, 16 July 2012 (UTC)
How to add reports in a larger collection
Latest comment: 12 years ago3 comments2 people in discussion
Also, once I have added the files, what are the next steps to help their progression to becoming proofread and published (I am new to this, but am eager to learn)?Jssteil (talk) 03:47, 17 July 2012 (UTC)
Thanks! So, I should go ahead with the larger document? It throws me off because each chapter has its own set of authors. Where would be a good place to see a "How To" tutorial or cheat sheet to help me with this process?Jssteil (talk) 04:23, 17 July 2012 (UTC)
/* The Book With All Blank Pages */
Latest comment: 12 years ago9 comments4 people in discussion
Index:Pathfinder of the Seas.pdf This book shows all pages as blank except for a few illustrations. However, the text was transferred to Wikisource. Does anyone have the knowledge as to how to remedy this Index of blank pages? As is, it cannot be validated. I thank anyone who has such skills and helps set this book up properly—IF it can be done at all. I downloaded it from Internet archives and uploaded it to Commons. Then AdamBMorgan tried to transfer it all to WS but again, there are no images but the text is there. William Maury Morris II (talk) 08:11, 17 July 2012 (UTC)
Chris55, If I upload another of the same file should I rename it or not? The original name was alpha-numeric so I changed the name to "Pathfinder of the Seas". The actual title is longer, Matthew Fontaine Maury Pathfinder of the Seas. Google files are so strange I figured just renaming the original file caused the present problem. Thank you for your help. Kindest regards, William Maury Morris II (talk) 09:09, 17 July 2012 (UTC)
Took a(nother) shot in the dark and uploaded and successfully installed the .djvu version as Index:The Pathfinder of the Seas.djvu. I was told by WMM2 that it didn't work before, but now it seems OK. While I am in the dark why it didn't work before, all I've done is set the resolution to 999px. Aside from that, I dislike working with .pdf due to my previous bad experience with Google's contribution to PSM. — Ineuw talk13:29, 17 July 2012 (UTC)
If we are going to use the DjVu file, the work already completed on the PDF version can be moved over to the DjVu by bot rather than starting from scratch. - AdamBMorgan (talk) 17:23, 17 July 2012 (UTC)
Latest comment: 12 years ago23 comments9 people in discussion
We are all typing way too much around here wrt header. There is much more functionality in PP than I believe most of us understand. I plan on fleshing out a better help page but here is a sample diff. It can do much more than just the simple cases like this.. But I want spread this awareness of the basics right away while I work on getting a help document together. All of the normal parameters will work to override the ones filled in from the index page template. It magically knows the prev and next, but like anything else it can be overridden for strange cases. We probably have some templates we like to use inside the notes field that will not work out-of-the-box, but getting them to work is so easy even I can do it! So let's all edit with less tedious copy-pasta and more magic software. And even better things are in pipeline. Might I suggest Magic Index Pages? And if you find this helpful, be sure to thank User:Tpt. Not all the magic was his work, but the future magic will be and he took the time to sit me down at a laptop and make certain I really understood how magical the software was so I could share it with all of you. And even though he speaks English better than I speak software, communicating with me was still a task. One he easily could have have decided was too much trouble and simply chose to leave off with the message to "use headers" he had given me at the WS dinner. One lesson I am certain of from Wikimania, is that I am wanting as a technical liaison for en.WS, so some more should mark their calendars for Hong Kong. And I can't really covey well enough how much of a hit Wikisource was at the conference, but I will leave you with this wordcloud from the Unnconference were everyone in the room added three words.BirgitteSB18:35, 17 July 2012 (UTC)
I have seen this in action, and was initially sceptical of how robust it is and still unsure about how flexible it can be. On the other hand, it plays to my belief that metadata for a scan-based book all belongs on the Index page. For "simple" works, it appears to work just fine. Documentation for other cases (for example, being able to add authors of individual sections) would make me a very happy bunny, and probably remove any last vestiges of ludditeism!
Thanks for the wordcloud, I am interested to see that some of the biggest words are "metadata" and "technology", and very excited to see "Wikisource" up there at the top! Inductiveload—talk/contribs22:25, 17 July 2012 (UTC)
I can see this is all very sensible but am lost at an earlier stage. I can't find where <pages> is documented. Is it in mediawiki or is this a Wikisource adaptation of some more general mechanism? All I've found is the rather breathless stuff in Help:Proofreading which which needed some sorting out. From mw:Manual:Tag extensions it should be at mw:Pages but it's not there. Chris55 (talk) 00:01, 18 July 2012 (UTC)
Its not documented because it was still experimental at best the last time it came up here on en.WS. The only blurb about it is indeed found on MediaWiki:Proofreadpage header template. -- George Orwell III (talk) 02:19, 18 July 2012 (UTC)
Hmmm that's a good one. I thought it was because there was no base page but the same thing happened even after I hastily created one. Anyone? -- George Orwell III (talk) 03:01, 18 July 2012 (UTC)
My wild guess is that it has to do with the page numbers being linked instead of the descriptive titles on Index:Our Philadelphia (Pennell, 1914).djvu. I was told the magic all comes from the index. Well I was probably told exactly how it works, but the most I understood was that the magic comes from the index. The documentation on fr.WS didn't look half bad from someone only able to half read French. I plan on working on documentation this weekend. It does do more stuff and seems flexible to variation. BirgitteSB03:18, 18 July 2012 (UTC)
Yeah, you've got to link titles only on the Index ToC. There's a working example at The Fraud of Feminism (index) (title page isn't transcluded yet, chapters are). This excites my imagination though--suppose we also kept the information about what pages chapters span on the Index (right now it's in the pages tag in the transcluded page). Then it would be super easy to link together pages numbers in indices among other things. Prosody (talk) 09:19, 18 July 2012 (UTC) No, wait, pages are linked on Wayfarer in China. Huh. (updated 09:37, 18 July 2012 (UTC))
My issue with the magical header is that it probably works okay for a limited set of subpages, however, for root pages where we have modified the fields that can be put into the header (portal/wikipedia/...) there is no ability to add those, which would also apply for many biographical works that we host. — billinghurstsDrewth14:13, 18 July 2012 (UTC)
If we have to add each and every parameter to 2 MediWiki files just to manually add via the pages command line most of what is currently handled by default using the straight header template, then how can anyone say this approach is not flawed? I get it everybody is crazy for coco-puffs in the quest to somehow attach metadata to works but that should be done to the uploaded file itself & not through the bastardization of namespaces by scripting or whatever at somepoint in the PR regime afterward. -- George Orwell III (talk) 00:42, 19 July 2012 (UTC)
This isn't about metadata at all as a far as I am concerned. I don't see how using header=1 changes anything about metadata (but maybe you know something i do not). It is about not having to copy-pasta all previous/next fand section ields. That is the big diffrence in my wiki-experience. Secondarliy it is a more streamlined edit, and easier to teach as you only type things out when you want to do something non-standard. The metadata, I like a more robust solution for. (Which is another topic entirely and requires substantial development.) I don't realy see what is so flawed about needing to make two once-only edits whenever you we want to set-up something new. Isn't it more flawed to type out or paste the text on every single page?--BirgitteSB01:11, 19 July 2012 (UTC)
Reading through all this (as amateur editor) and still trying to figure out how the Magic grabs the section/chapter headings. I tried some changes to my TOC to no avail... Looked at Prosody's TOC example as comparison, but I am still missing something, and can only assume it has to do with my formatting as opposed to others? unless it is something else entirely that I would love for someone to point me to :) Londonjackbooks (talk) 01:18, 19 July 2012 (UTC)
I think you just needed to purge the page to clear the version that the server had stored away temporarily. The "clock and purge" gadget is useful for this. Inductiveload—talk/contribs01:52, 19 July 2012 (UTC)
One thing I'm concerned about with magical headers is that it might make the searching problem with transcluded pages worse. Will it mean that some of the basic metadata won't be visible (e.g. names of authors) because the data isn't there physically on the page and therefore the limited searching capabilities will be even further eroded? Once the mediawiki bug is sorted this won't matter, but there's no news on that yet. Chris55 (talk) 10:12, 19 July 2012 (UTC)
I am not sure how exactly you might test that, but I should test it using by looking at the fr.WS. I am reasonably certain that they all use header=1 over there.--BirgitteSB13:27, 19 July 2012 (UTC)
I just did a search for "A Child in Philadelphia" (Ch. 2 of my example—the only page I performed Magic on), and came up with next/prev chapters, but not the actual chapter-in-question. I always thought if you could see it, you could search it... no? I also tried to search for phrases within a couple different chapters, but the only results that came up were from Index pages and not Mainspace pages. Londonjackbooks (talk) 13:58, 19 July 2012 (UTC)
Internal searches read the wikitext and do not "follow" <page> tags, so anything transcluded with them will not be searchable. (NB: Transclusion with curly-brackets is followed, such as with templates, mostly because Wikipedia uses that method, but that doesn't help here.) External searches, such as Google, read the generated HTML, so they pick up anything visible on the page. As such, internal search will almost certainly not pick up the magic header or its contents, while Google searches will pick up the magic header and its contents. That said, if you are searching for, say, an author name, you probably want the author page anyway; which should link to the work with the magic header. A compatible search function would be nice but I don't think magic headers break it significantly more than it was already. - AdamBMorgan (talk) 16:52, 19 July 2012 (UTC)
Another example for Birgitte is: search for "Kinship Rivers" and you won't find it in the main namespace, whereas a search for "Kinship" brings it up as no. 1. Sorry to be rather late on this. Chris55 (talk) 08:28, 23 July 2012 (UTC)
Moving Text .djvu vs .pdf
Latest comment: 12 years ago6 comments3 people in discussion
Can only the proofread pages be moved? Even if it overwrites the few pages I proofread in the .djvu version, I can easily re-create them. Pages that haven't been created are not relevant. I think this is what WMM2 means. Realizing of course that it may be confusing to receive requests from two editors for the same job. Personal translator of WMM2 wishes :-D — Ineuw talk05:03, 18 July 2012 (UTC)
Sorry to reply so late. Real Life gets in the way sometimes. But yes, Ineuw explained it correctly. He and I work on each other's works so he knows what I work on and corrects my errors and validates just as I do with his work with the PSM volumes. I must not be very good at communicating. At the very top I wrote, "Is it possible to move the proofread pages from" and gave the link afterwards. So, is it possible to do what Ineuw has explained? I think it is only about 40 pages or less that was proofread (colored yellow). I did that work from a file on my computer. "WMM2" --William Maury Morris II (talk) 05:32, 18 July 2012 (UTC)
Done, all the text should now be at the djvu. The soft redirects will be tidied by bot in a couple of months. I would leave the index there for now with a notice not to use it, since otherwise you can't see all the pages awaiting clearance. It can be deleted when it won't leave orphans. Inductiveload—talk/contribs00:56, 19 July 2012 (UTC)
Thank you, Inductiveload. I also thank all others through this struggle. However, on my home page a note was left for me by George Orwell III, saying that book is not US Gov't public domain and is under copyright. Therefore, it has to be terminated. With a WS public domain "billinghurst...sigh", I join in with my own deep sigh... --William Maury Morris II (talk) 06:48, 19 July 2012 (UTC)
The September Dossier
Latest comment: 12 years ago11 comments6 people in discussion
Hi.
I mainly contribute to the English Wikipedia and am a complete novice here so I thought i'd ask for some help and advice; I apologize if this is the wrong place for such a request.
Unfortunately, as a work of UK Government, this falls under Crown Copyright, which (for published works) expires 50 years after publication. The Open Government Licence is unlikely to apply, as this was introduced in 2010, and the Dossier is from 2002.
It is very appropriate for Wikisource, and if it turns out to be freely licensed, it can be added. The "best" way to do this is to find a scan (usually PDF or DJVU) of the real document, or some other primary source and upload that to Commons (or Wikisource if it cannot be hosted at Commons). This can then be proofread. Failing that, copy-pasting the text from some reliable source and adding formatting and metadata is better than nothing.
One thing that you could do if you want is attempt to persuade the UK Government to release this document retrospectively under the OGL. I have no idea if this possible, either theoretically or practically, however. Inductiveload—talk/contribs22:19, 17 July 2012 (UTC)
There's no problem with the text: there's a link to a copy on the BBC website at the bottom of the article which I've just downloaded and could possibly compare with the copy I downloaded at the time! There's no copyright statement in the document and I wonder why the BBC can still host it if it is copyright. Chris55 (talk) 00:14, 18 July 2012 (UTC)
I don't know the answer to that specifically but here in the US most news agencies ahave standing agreeements with news gathering organizations such as Associated Press and Rueters so maybe the same hold true for gov't entities there. The real point I'd like to make though is that bad actors engaged in questionable copyright practices elsewhere does not always amount to justification for hosting the same here on en.WS. -- George Orwell III (talk) 02:01, 18 July 2012 (UTC)
I agree with you, but I was thinking of documents covered by Category:PD-UK-EdictGov which include, for instance, the Freedom of Information Act 2000. I did try to establish what this covered but w:UK copyright law is a minefield! It seems to me intuitive that it should cover items like this that were issued for public consumption and were never intended to be sold by w:HMSO. I wouldn't want the BBC to be included in the list of 'bad actors':-) I'll continue to search. Chris55 (talk) 08:16, 18 July 2012 (UTC)
Oh I totally agree with you that at face value one would think publication was meant for public consumption.... but we've been down this road before concerning UK gov't works - the right to free and unfettered access for one subject's consumption doesn't necessarily mean the same thing as the free and clear reproduction by 3rd parties for hosting elsewhere (such as on en.WS). -- George Orwell III (talk) 09:19, 18 July 2012 (UTC)
Something like this might be possible in principle, though it might have to be a new licence category. The website theyworkforyou.com which reproduces Hansard reports of parliament to allow voters to check up on their MPs was originally refused permission to do so but were fin ally granted it when they applied. Both Open Government and Open Parliament licences have to be granted explicitly and the recent w:Protection of Freedoms Act 2012 specifically excludes these from the right of re-use. I'd be prepared to make such an application but it would be important to get the weight of Wikipedia behind it. Chris55 (talk) 15:09, 18 July 2012 (UTC)
Not sure what weight Wikipedia or Wikisource could or would "put behind" the request. If the license is ok, anybody can add it to Commons and Wikisource and it will stay. It’s all about, licensing and individuals motivated to contribute. If I were going to pursue (which I am not), I would ask as person without regard to Wiki status. The real question is about releasing with license that is compatible with GFDL & CC-BY-SA. Even if it is released, it may or may not make it’s way here. JeepdaySock (talk) 16:19, 18 July 2012 (UTC)
Well I'm not a lawyer and certainly no expert in copyright law, but from brief lookaround it seems that parliament has pussy-footed around the issue without doing much real at all when it comes to government statements, except for the future. Even the FOI legislation I downloaded had a clear crown copyright declaration. I'd question most of what has been put on Wikisource in this area. The theyworkforyou approach seems a possible line of action but only a concentrated effort would work. In this respect the implicit link in many people's minds with another Wiki-labelled organisation is rather damaging. But the FCO has clearly removed the dossier from its website (and the wayback machine won't show it) and would probably like to forget all about it, which is why it is important to have it here. Chris55 (talk) 19:06, 18 July 2012 (UTC)
Having looked again at this I can't see why it shouldn't be published under {{PD-EdictGov}}. 'It says Such documents include "judicial opinions, administrative rulings, legislative enactments, public ordinances, and similar official legal documents."' as the US does not consider this copyrightable. If no-one disagrees, I'll put it up. Chris55 (talk) 17:44, 24 July 2012 (UTC)
Renumbering Pages
Latest comment: 12 years ago3 comments2 people in discussion
Hello, I have looked everywhere and cannot find information on what I am trying to do. I want to have the page numbering in this document's index page reflect the real numbering within the document (Cover, i, ii, iii...1, 2, 3...).
Thank you! I knew I had seen it somewhere while looking it up on my phone while away from my desk, but I couldn't replicate the search results once I got back on the computer. I really appreciate the help!Jssteil (talk) 14:18, 18 July 2012 (UTC)
Maintenance of the Month
Latest comment: 12 years ago6 comments4 people in discussion
Following on from the Reform Month 2012 suggestion earlier this July, we now have Wikisource:Maintenance of the Month almost ready to go. This will hopefully be something like Wikisource:Proofread of the Month although aimed at maintaining and improving the project, from basic gnoming and gap-filling to upgrades and reforms. This month the goal of the project is setting up the project itself:
Next month will probably be a big effort to improve categorisation of our works. We have a list of suggestions culled from a few other areas. If you have additional ideas, add them to the list or discuss them on the talk page. If you want to keep informed of the month's task, the {{MotM}} template will be updated each month with the pertinent information. If you want to help set this up, there's probably a lot still to do, otherwise we'll hopefully see you in August for the categorisation. - AdamBMorgan (talk) 22:12, 18 July 2012 (UTC)
I would like to say that there was actually an editor at Wikimania, who in the Q&A section of a WS session, complained about the state of the help pages on en.WS. Many in the audience seemed to be in agreement. I felt badly for Italian and French Wikisource presenters who kindly spoke of what a small community we are compared to Wikipedia. I will be working on help pages for a while, it now seems imperative to me they recieve some attention. But having a collaborative maintenance project is wonderful and I really appreciate what you've done to launch it.BirgitteSB00:13, 19 July 2012 (UTC)
Yes, our help pages are pretty bad. This can be September's task. It's a little more involved than categorisation but we should be warmed up by then. I've been trying to improve the help pages, and Chris55 is currently working on it, and it can be harder than it looks. Focussing the community on the problem should help that. - AdamBMorgan (talk) 11:27, 19 July 2012 (UTC)
Really? I feel that help pages on the English Wikisource are well-organized, helpful, and clever, but the best thing about them is that they are few! See you at the project's discussion page.--Erasmo Barresi (talk) 19:08, 19 July 2012 (UTC)
There are gaps. We still lack full documentation for Index pages and the existing page required updating (the updating has been done now and I have started Help:Index pages, albeit with little content so far). We have also had a problem that a lot of documentation starts at the intermediary or advanced level, completely skipping beginners and novices. The gaps are in the policy pages as well. Works have been deleted as extracts or syntheses of other works but we do not strictly ban them. (Syntheses could be covered by an interpretation of "no original works" but it is not spelled out anywhere and the originality of a synthesis is debateable.) I've learned things from reading Scriptorium, Proposed deletions etc that are not covered in any official documentation in the Wikisource/Help namespaces. I think the best word to explain some parts of Wikisource is "arcane," that is "requiring secret knowledge to be understood." We should fix that. - AdamBMorgan (talk) 12:01, 20 July 2012 (UTC)
not sure I would call it secret knowledge, just really hard to find. As Adam says, most everything is or has been on Scriptorium, and if you ask about anything, someone who knows will answer. The transition from the knowledge of experienced editors and Scriptorium to help pages has been lacking, but MotM is well on the way to fixing it. There has been a lot of interest in the project and it is looking very much like it will be a huge help for Help:JeepdaySock (talk) 15:30, 20 July 2012 (UTC)
Statement of Permission
Latest comment: 12 years ago13 comments4 people in discussion
I wish to announce to everyone here that I telephoned Making of America, Cornell University, NY and have gotten permission to use the following work [14] dated 1855. I have a kinsman in this work and he is Lieutenant John Minor Maury (USN), son of John Minor Maury (Sr.) who died and thus John Minor Maury (II) was raised by his uncle, Commodore Matthew Fontaine Maury (USN). This is the story of the 1854 Darien Exploring Expedition that I have been aware of for decades. The author was Joel Tyler Headley. These images are not in .PDF or .DJVU format so I will have to collect them and place them in .PDF format, unload to Commons and somehow get the file on Wikisource. This expedition was an American 1st in crossing the Isthmus of Darien. This expedition is similar to the expedition where then "Lieutenant" Matthew Fontaine Maury Supt, Naval Observatory, thought of and set up Lieutenant William Lewis Herndon (USN) (1st cousin to M. F. Maury and brother-in-law) to explore the Valley of the Amazon along with Lieutenant Lardner Gibbon (USN). Matthew set up several expeditions for the United States Navy while he himself worked on several other projects that brought him fame in his day. Once I get the preliminary work done I will need help from someone to download the .djvu version. I have no idea how to do that with a .djvu file and I have tried several times. I can read them but I don't know how to download .djvu files. I only know how to work on Commons with .PDF files. --William Maury Morris II (talk) 19:38, 20 July 2012 (UTC)
I think that if you upload the PDF document to IA, they will process it to all types of documents like djvu, .JP2, HTML, etc. From there, we can get the djvu and upload it to the commons.— Ineuw talk20:08, 20 July 2012 (UTC)
Yes, IA will. I have uploaded .PDF files to Commons in the not so distant past. I just have problems downloading a .djvu file and then getting it to WS to work on. Respectfully, --William Maury Morris II (talk) 20:18, 20 July 2012 (UTC)
It's Internet Archive that does the conversion to .djvu, etc. If you have the .PDF then upload it there and let me know. I will take it from there on.— Ineuw talk20:57, 20 July 2012 (UTC)
I know that, "It's Internet Archive that does the conversion to .djvu, etc." I wrote, "Yes, IA will" (convert). ... but Ineuw, once you get it on Wikisource, I want it back! You can do those terrible "sketched" images if you want. I will try to remember my log on information and upload the .PDF asap (hopefully in a few minutes. I have been looking over Maximilian "of Mexico" texts I want to do afterwards. --William Maury Morris II (talk) 21:16, 20 July 2012 (UTC)
If the original work is a PDF, you should not convert to DJVU. DJVU introduces a whole new level of compression on top of that already present in the PDF which is considerable. DJVU compression is very damaging to images in general, and IA compression is brutal (because heavy DJVU compression sometimes works on the level of individual letters rather than pixels, I have seen PDF->DJVU conversions actually contain textual mistakes when two glyphs look similar in the scan). The only thing a DJVU made from a PDF is really good for is the text layer. Inductiveload—talk/contribs23:02, 20 July 2012 (UTC)
Right. If you can highlight & copy text with whatever it is you use to view PDFs in general, then the PDF most likely has its own "brand" of hidden text layer that will come up just like the DjVu text layers do when you go to create a page from the PDF in the Page: namespace. There are exceptions to this but lately IA seems to go a step beyond the usual reproduction of a non-layered, black-and-white PDF (i.e. the bogus puke yellow or baby-poo brown backgrounds are removed from the scanned pages) compared to the original by running an additional OCR on PDFs lacking a reliable hidden text layer to begin with.
The only remaining benefit (in current terms) of DjVu over PDF would be when the PDF is over the 100Mb Commons limit for uploads and converting it to DjVu would bring the file size under that limit. PDFs are superior in the way they store metadata as well. -- George Orwell III (talk) 00:23, 21 July 2012 (UTC)
Should have read this earlier. Please read my related post below. In any case, I wanted the .JP2 files for the images, which I already downloaded.— Ineuw talk02:43, 21 July 2012 (UTC)
My concern is getting the images on WS without them being blurred from IA conversion processes. I don't mind if the text is scrambled because I can type the book in. However, I suspect you gentlemen are aware of and thinking of something beyond this. To know what format the images were in take a look at the link above number [1]. However, I batch converted .those .GIFs to .JPGs and placed them all in a .PDF file. What format is suggested for batch conversion from .GIF to what? .JP2 ? --William Maury Morris II (talk) 04:38, 21 July 2012 (UTC)
This is the first page format 00443.tif100 I saved it as page 443.gif and all are in this format as shown in the link above to the images. Sorry I haven't been back here sooner here but I had to take a nap.--William Maury Morris II (talk) 04:47, 21 July 2012 (UTC)
Latest comment: 12 years ago7 comments3 people in discussion
Uploaded to the commons this IA file: Index:Darien Exploring Expedition.djvu and upon seeing the quality of the print, I quickly uploaded the PDF version as well. Unfortunately, there is no text layer in the .pdf file, so I was wondering if someone has the time and the inclination to move the .djvu text layer to the .pdf version. When it's done, I will ask for the deletion of the .djvu file.
a DjVu text-layer and a PDF text-layer are not interchangeable. The only thing they really have in common is that they are both hidden behind the foreground-layer (in other words the scanned black text). As per the above, 2.2 minutes after IA completed the PDF with good-images/no-text, they uploaded a 2nd PDF with poor-images/OCR'd text. I uploaded that one over the first. Create all the pages and then revert back to the original on commons. -- George Orwell III (talk) 03:19, 21 July 2012 (UTC)
The one word answer to the text layer issue is "ignorance". I am creating the pages as instructed by GO3, but will keep in mind the OCR option within WS because I am not sure if the text is garbled or not.
As for the list. . . I am referring to the page where new additions are to be listed (added manually). — Ineuw talk03:45, 21 July 2012 (UTC)
Well that text-layer is nothing to brag about. Too many chefs but nobody who can really cook it seems. The DjVu text layer "seems" superior to both the IA generated & local OCR button generated ones. I'll help copy and paste if need be at this point. -- George Orwell III (talk) 04:04, 21 July 2012 (UTC)
Your kind offer is noted and declined. Downloaded the text file and will add it page by page when proofreading. I am getting pretty good at it by now.— Ineuw talk04:13, 21 July 2012 (UTC)
Latest comment: 12 years ago2 comments2 people in discussion
If you build or work on author pages take a look at the {{Authority control}} template and the gadget that makes it work really easy. It is under "In development" with the description "Add a toolbox link to select and import a variety of authority control data from VIAF". Jeepday (talk) 10:10, 21 July 2012 (UTC)
This is Max Klein's project. He is the Wikimedian in residence at OCLC. He edits as w:User:Maximilianklein or w:User:Maximiliankleinoclc. I am certain he would love to talk to anyone about it. Unfortunately I only heard the blurb introduction to project, so I don't understand a lot of details. But I did talk with Max on several occasions, he has done a great deal of GLAM outreach and is easy to talk to. So don't hesitate to approach him if you are interested in this topic.--BirgitteSB13:22, 21 July 2012 (UTC)
Request from Wiktionary
Latest comment: 12 years ago5 comments2 people in discussion
Hi, Wikisource! I'm from Wiktionary, where I'm currently working to improve coverage of terms in Tok Pisin using the Tok Pisin Bible as a source for supporting quotations. All these template-formatted quotations, however, lack English translations. To fix this, I'm hoping to link to Wikisource's most recent English Bible that is completely translated, or even better, transclude from it, if that's possible. The only thing is, I need to be able to link to specific verses in the text. Can we modify Template:verse over here or find another technical solution so that is possible? Thanks so much Metaknowledge (talk) 18:49, 23 July 2012 (UTC)
{{verse}} already creates an anchor, if that's all you need. For example, to link to Matthew 3:16 in the American Standard Bible, use Bible (American Standard)/Matthew#3:16 (or, on Wiktionary, [[s:Bible (American Standard)/Matthew#3:16]]). I don't think you can transclude between projects but linking should be OK. - AdamBMorgan (talk) 20:35, 23 July 2012 (UTC)
That's wonderful! Thank you so much! As a side note, I am trying to ask the Bible Society of Papua New Guinea if they can release the Tok Pisin Bible under a Wikisource-compatible license. I could not contact them, and so I tried asking the sister organization the American Bible Society, but they have not responded. Do you have any ideas of how I might proceed to try to contact them directly? Metaknowledge (talk) 02:28, 24 July 2012 (UTC)
I can't help with that, I'm afraid. I don't have any experience in that area, although other users may be able to help you. The Internet Archive has a seven-page extract of a Tok Pisin Bible but it doesn't show a licence. That version apparently comes from the Long Now Foundation, who might be able to help you with licensing. Otherwise, maybe an occasional reminder or follow up call to either of the Bible Societies will get a response. - AdamBMorgan (talk) 17:02, 24 July 2012 (UTC)
Latest comment: 12 years ago12 comments5 people in discussion
When reading (and printing) a tooltip can easily remain hidden. Lieutenant Maury My question is how can this be bettered so that a full name can be seen? I wonder if a pop-up can be applied so that when reading one can see that full name? People do not run a mouse over the text to see that question mark used with tooltip and the full name can therefore remain invisible when using a tooltip. --William Maury Morris II (talk) 12:46, 24 July 2012 (UTC)
If you want it to be seen without a mouseover, and I am assuming you don’t want to do something like Lieutenant Maury (Lieutenant John Minor Maury). Then it sounds like you are asking for an always on floating comment. Ignoring the technician challenges; how could this be done, without blocking other text? JeepdaySock (talk) 14:42, 24 July 2012 (UTC)
Ho ho! You're asking me!? Jeepday, you are one of the wizards here not "I". I have no idea as to the answer of your question. In looking over WS on FB, I as a reader wonder about that question I brought here earlier. All too often initials are used in books but what is behind those initials? I will state that there are worlds of history, science, and more mystery behind initials. Yet most histories that lay behind mere initials remain forgotten as generations pass away and thus the history becomes unknown. The books I refer to are WS books shown on FB. So, the solution must be here on WS, if there is a solution — but I have always believed in solutions — it is a matter of knowledge and seeking solutions for answers. Wonderful worlds of knowledge and pleasure in reading are hidden by mere initials. Respectfully, --William Maury Morris II (talk) 15:07, 24 July 2012 (UTC)
In the above "tooltip", the book I am presently working with, a true story of an USN expedition that was about connecting the Atlantic and Pacific oceans — only the last name is shown and not even his initials. I just happen to know this history and his last name (my middle name as shown here) and how they connect to a lot more history kind of like Internet itself with links shown. Today we are casual about the Panama canal but in the not so distant past England and the USA as well as other nations sought the pathway through the Isthmus of the Darien and almost went to war as to who would get that finding and rights to building and thus billions of dollars a year transporting goods back and forth. So, in those times it was of paramount interest to many nations who were ready to go to war over it. It is all found in people of long ago via their initials or a hint of a first, middle, or last name. BTW, Aspinwall, uninteresting to me as just another name at first, is the last name of a man involved in the Panama expeditions and in due time he was involved in the prevention of cruelty to animals and the SPCA was created do to his works. --William Maury Morris II (talk) 15:43, 24 July 2012 (UTC)
There's really not an easy technical solution here, since we're appropriating an existing HTML tag (the title tag). A script could possibly be worked up so that when people print a page, the tooltip is displayed afterwards, but for just reading? Not really, especially when it can become redundant (like JeepdaySock's example illustrates). EVula// talk //16:49, 24 July 2012 (UTC)
(edit conflict) I am referring to your perception of how the solution would work. In the tool tip above when you mouse over, several words are obscured by the pop-up. If you could magically have anything you wanted, what would the display look like to show the information? JeepdaySock (talk) 16:51, 24 July 2012 (UTC)
Okay, let's consider this, Lieutenant Maury can a tooltip show a different colored line, such as red, or a darker blue, &c., like a "hotlink" in html when it is moused over? --William Maury Morris II (talk) 13:44, 25 July 2012 (UTC)
I suppose none of this is really of any value. The question mark that pops up when someone mouses over the dotted faint blue line is probably the best situation although this assuming a reader on WS or WS-FaceBook will see the faint dotted blue line (can that blue be made darker?) and then do a mouseover. I was trying to make it a bit more obvious that there is more information behind initials in this particular situation. Kindest regards to everyone, --William Maury Morris II (talk) 15:08, 25 July 2012 (UTC)
I was reading MSNBC.com moments ago and noticed they have active links underlined in blue (other text is black) and upon mouseover that active, or hotlink, turns red. It catches the eye better than tooltip used on WS editing of text beside books. --William Maury Morris II (talk) 19:28, 25 July 2012 (UTC)
On a different tangent, reference-based annotations might work. This uses the same system as a Wikipedia reference. So, it will be "Lieutenant Maury<ref>Lieutenant John Minor Maury{{user annotation}}</ref>". The note(s) will appear at the end, or wherever you put the <references/>, {{reflist}} or {{smallrefs}}. In this case "Lieutenant John Minor Maury (Wikisource contributor note)". The number after the name will be more visible; which is part of why this is a little contentious; you are adding something to the original text. {{tooltip}} does not interfere with the text but this does (slightly). The {{user annotation}} template might help. We should try to revive the annotation policy at some sage. - AdamBMorgan (talk) 21:40, 25 July 2012 (UTC)
I like Adam's suggestion, though this won't really affect what I work on. I know that in discussing annotations, their was an option where the reader could toggle wikisource editors notes in the display options. That could leave the text clean for those that prefer that, and annotated for those that prefer that. - Theornamentalist (talk) 21:54, 25 July 2012 (UTC)
Adam does have an excellent point and I am somewhat familiar with it. I learned tooltip from Adam (copying him) and have used it a fair amount to get rid of mere initials on things I felt were important. User:Ineuw and I were working on something and Ineuw pointed out that I "tend to annotate" so he showed me with an example what Adam has stated above. Part of the reason, oh, I see I have written it in the above. Anyway, there were two Lieutenants in the USN named John Minor Maury. One was Matthew Fontaine Maury's brother and is on WP but the one who was on the United States Darien Exploring Expedition of 1854 was a nephew and has basically been lost in history as much as he was lost in the Darien jungle. But that expedition, although ill-fated and headed by Lieutenant Isaac Strain was an American 1st in crossing the Darien Isthmus. This John Minor Maury [nephew] survived and became a hero. When I first learned this I wondered how and I had no family resources on that except a quaint little brief statement from his cousin's book, Maj Gen Dabney Herndon Maury's "Recollections of a Virginian in the Mexican, Indian and Civil Wars (on-line) where he writes a short piece about "Jack Maury" climbing the church steeple and the citizens saying he "would come to no good" but M.Genl. Dabney Herndon Maury stated that "Jack" had become a "hero" on an expedition. That raised my curiosity and I sought information over a long period of time. WS didn't exist back that far. Virginia families, like many others families elsewhere tend to repeat family names throughout history and it can get confusing. I thank the both of you for your help and wonderful knowledge and for sharing what you know. Respectfully, --William Maury Morris II (talk) 22:25, 25 July 2012 (UTC)
Spell Checker
Latest comment: 12 years ago5 comments3 people in discussion
What browser and operating system do you use? My spell checker (I'm on a Mac, so it's built into the OS) has nothing to do with this site specifically. EVula// talk //23:38, 27 July 2012 (UTC)
I thought there was a spell checker on our WS editor. I am using firefox, version 14.0.1, that is set to automatically upgrade. I'll have to figure out how to keep the spell checker always on because when editing text on WS it isn't on unless I click it on. I use more than one computer in our house. This one is Windows XP. Thank you both. Kindest regards, --William Maury Morris II (talk) 11:24, 28 July 2012 (UTC)
Latest comment: 12 years ago1 comment1 person in discussion
This is the first active month for the new Maintenance of the Month project and we aim to check and categorize as many works as possible on Wikisource.
The details and guidelines are available here, or follow the link in the template. There are lists available of all the base pages on Wikisource, which all need to be checked to see if they are fully and correctly categorized and, if not, this needs to be fixed. This is an aspirational goal but we should be able to get a lot done in the month; the task can be continued and re-visited later. For bonus work, other small fixes or tagging for future maintenance can be done at the same time. The task for September is set to be Help Pages, adding new ones and improving the ones we have already. - AdamBMorgan (talk) 18:12, 1 August 2012 (UTC)
EPIC/Oxford study on Wikipedia quality
Latest comment: 12 years ago6 comments2 people in discussion
Question: The last link on the second page is broken; it seems that the text "#?32" gets inserted at the end of the URL, even though it is not there in the page text. Any ideas why this might be happening? -Pete (talk) 14:14, 3 August 2012 (UTC)
A: That is an example of why NOP is better applied in certain cases at the end of a page rather than at the top of the next page to force a clean LF & CR (a line break without <br >) -- George Orwell III (talk) 15:25, 3 August 2012 (UTC)
Latest comment: 12 years ago2 comments2 people in discussion
If someone would want to, or be willing to, look over my proofread pages on Index:Decline and Fall of the Roman Empire vol 1 (1897).djvu, that would be great and I would really be thankful. I am not trying to just get the book validated quickly, I just feel I could learn from someone noticing certain things I do wrong.
I took a look at the first page, and made a few adjustments, and validated. Nothing huge; I added the {{RunningHeader}} template, which was missing -- but I see you've used it on other pages, so I guess that was just an oversight. I also provided a link for context, as a suggestion; some editors do more of this than others, personally I think it adds a great deal of value to a Wikisource transcription to link important concepts to Wikipedia or Wikisource resources. Do as you see fit though :) Keep up the great work! -Pete (talk) 16:13, 3 August 2012 (UTC)
Proofreading project
Latest comment: 12 years ago4 comments3 people in discussion
I've become concerned that despite the impressive mechanism set up for proofreading and validating texts, the index files are getting away from us. More and more are being created which aren't getting proofread and validated. The reason must be that we don't have enough proofreaders and a large part of that reason is, I believe, that we aren't presenting people with a good range of works to be proofread.
I've written an essay on Improving the proofreading rate which includes lists of the target index files broken down in a way that make a better approach to this. To get this up and running will require some help from others and I'm therefore proposing a Proofreading WikiProject to sort out the best way of doing it and to get it started.
Yes, sir, I have a comment or three. I do not often look to see how many awards? have been given to whomever. But I recall what Napoleon once said to one of his generals when asked why he (Napoleon) gave out so many medals. Napoleon said, this tiny medal of little monetary value is worth 10,000 troops. That isn't the exact quote and it can probably be looked up. The point about this here and now connecting to the above situation is to give out new and special awards to proof-readers and validators. Then watch and see the ill situation above change or not change. There is nothing to lose in trying this but something possibly may be gained. If it doesn't work then there is no need for the different awards for proofreading and validating. Many works not validated but proofread are accepted as finished. Still, when I look through those I can find mistakes or something left out. Every page should be both proofread and validated before being accepted as a completed new text. This is just my opinion and we all have our opinions. Kind regards to everyone, Maury (William Maury Morris II (talk) 00:51, 4 August 2012 (UTC)
Yes, we need some quite specific tools for Wikisource - counting particular types of edits, those that advance the state of a page (proofed and validated) and of an index (proofed and done). If we can, at least semi-automatically, give recognition to people after, say, 10, 100 and 1,000 such edits, and also provide feedback on the completion of works in which they've been involved, I think it would certainly help to get people committed. As you point out, we don't have proper guidelines for when works are finished. It's not always easy, for instance, to spot missed graphics. Chris55 (talk) 08:15, 8 August 2012 (UTC)
My thought is that having several works (even hundreds or thousands) that have been scanned and index set up for proofreading is good. Those parts are technically challenging to accomplish while proofreading is a great place to start for a new person. This is particularly good for Wikisource if enough ground work is done so that work is likely to show up on Google search, bringing in new proofreaders. Jeepday (talk) 10:31, 5 August 2012 (UTC)
Line breaks in categories?
Latest comment: 12 years ago4 comments2 people in discussion
Is anyone else getting line breaks in category names? I've seen it quite a few times over the last few days on Author pages. Author:Lucy Aikin, for example, has two. Both Category:Authors-Ai and Category:Early modern authors appear with a break (before "Ai" and "authors" respectively). Author:Julius Caesar only has one, with the line break coming after Category:Soldiers, so that the entire row of categories appears with twice the line height and "Soldiers" hovers above the rest of the text. All the categories still work, so there is no functional problem here, but it looks odd. - AdamBMorgan (talk) 22:19, 4 August 2012 (UTC)
Two things off the top of my head.... first - do you have 'show hidden categories' set to on somewhere in your user preferences? If you don't, maybe you should. Second, the category bar is really an item list (<LI>) that uses CSS class & id settings to "flatten" itself into a horizontal list. Do you have anything in your personal .js or .css that might be affecting list-items this way?
I do not see such line-breaks in either example by the way. No matter what browser window size or font setting I apply, the line breaks are always at the max text limit and always before the short-line item separator. -- George Orwell III (talk) 22:48, 4 August 2012 (UTC)
I do have hidden categories shown and I don't think anything in my personal js or css would cause this (besides which, I haven't changed either recently). I thought it might be HotCat at first, but turning it off didn't change anything. As long as this isn't happening to anyone else, I'll ignore it. - AdamBMorgan (talk) 23:24, 4 August 2012 (UTC)
Concur. The other thing that might be a factor is the skin applied. I have Vector applied and I'm not seeing anything unusual in the way of line-breaks or text wrapping. -- George Orwell III (talk) 00:06, 5 August 2012 (UTC)
Random sidebar links
Latest comment: 12 years ago5 comments3 people in discussion
I don't think these do what a uninitiated visitor would expect them to do. I think random book should select a random non-subpage from the main namespace. Dunno about random page. Prosody (talk) 22:43, 4 August 2012 (UTC)
The proposal hasn't been applied yet just closed apparently. If it is applied, it would change "Random book" to "Random transcription" and "Random page" would be limited to the main namespace and renamed "Random work". I don't think it has a function to exclude subpages but I would apply it to the latter if it existed. - AdamBMorgan (talk) 23:28, 4 August 2012 (UTC)
OK; thanks Adam. While I'm indifferent to the proposal itself, I do have a problem with it being closed in roughly a week's time instead of the usual 30 days or so from the last meaningful comment made. The fact Prosody comments here clearly shows the discussion could have benefited from further input given more time. In addition, what is there doesn't really show broad enough agreement or consensus (imho that is). -- George Orwell III (talk) 00:02, 5 August 2012 (UTC)
Latest comment: 12 years ago4 comments4 people in discussion
Does AutoWikiBrowser count as a bot? That is, do I need a bot account with a bot flag to use this software on Wikisource? I feel this is something I should already know. However, it only just occurred to me after making a few AWB edits. I don't think of it as a bot and it isn't covered anywhere but technically it is a "semi-automated [process] that edit[s] pages on Wikisource" as stated on Wikisource:Bots. - AdamBMorgan (talk) 00:18, 5 August 2012 (UTC)
I hadn't thought of this until I saw this here, but I too would love to know the answer. I'm used to running AWB on enwiki where a bot flag is not necessary for using it; it didn't occur to me that Wikisource might have different protocols. – GorillaWarfare(talk)20:43, 5 August 2012 (UTC)
I am not familiar enough with semi-automated nor automated tools to know off hand how they should be qualified. I suppose there are two points I would imagine to be significant. Do you review the each edit made with the tool? Do your tool-related edits make recent changes and watchlist less useful? If the answer are Yes and No, I can't see why it would need a bot flag--BirgitteSB00:57, 6 August 2012 (UTC)
AWB operates differently in user mode and bot mode. When in user mode, AWB sets up the edit, but the user must manually click the save button to approve it. There is an expectation that the user will properly review each edit before clicking save. Under those conditions, it is not regarded as a bot. Hesperian01:02, 6 August 2012 (UTC)
Promoting Wikisource, FaceBook , &c.
Latest comment: 12 years ago5 comments3 people in discussion
I have done a lot of shopping today, including groceries, and I always strike up conversations with people who appear friendly. This always leads to me mentioning Wikipedia and Wikisource. Most of the people I talk to are familiar to some extent with Wikipedia but it is rare (none today) to find anyone who knows about Wikisource. I explain the differences and make a suggestion to look for Wikisource and it's free books. When someone appears very interested I explain not only the differences but the processes. In short, many know of Wikipedia but very few ever heard of Wikisource. It is disheartening. We need better public relations. Perhaps Wikipedia gets that by asking for donations so often or perhaps WP existed and got all the press before WS—I do not know. I do not know if WS on Face Book is helping yet. Is there anyone here that watches the stats? Are we growing in any area? Kind regards to all, Maury (William Maury Morris II (talk) 03:26, 5 August 2012 (UTC)
Wikimedia provides a bunch of stats here. Of interest: our average number of page views has increased a good bit so far this year over last year, the number of active and very active editors has decreased substantially. Phe also has statistics and graphs relating to proofread page, which show that there's been a big increase in PP transcluded pages, but the number of non-transcluded pages is still growing, and that the bulk of pages aren't proofread and that there hasn't been a big takeoff in proofreading and validating like at German or Spanish WS (although we have several times more pages). Prosody (talk) 01:29, 6 August 2012 (UTC)
Thank you for the information on stats. I am most concerned about English and Spanish WS but Spanish Wikisource has a kind of, well, wicked, administrator and I don't like to waste my time with those types. There is always work to be done elswhere. Maury, (William Maury Morris II (talk) 03:23, 7 August 2012 (UTC)
Wikisource has a page on Facebook, but so far it has only got some 147 fans. Still, it wasn't Facebook or ad campaigns that helped Wikipedia become popular. It was rich content, visible to search engines. When people google for something odd and find the answer in Wikisource, that is when Wikisource becomes popular. It needs a whole lot more of useful content, but the sad fact is that Wikisource is still very tiny. --LA2 (talk) 02:50, 7 August 2012 (UTC)
I know that Wikisource has a page on Facebook and my face shows on that link you provided. I am wearing a black t-shirt and have a Texas tan (brown but w/blue eyes) I agree that WS is still "very tiny" but with enough work in the right places it can grow rapidly, or at least that is my belief. I have a lot of links from FB to WS but I believe I am going to have to create an administrator page which I really didn't want to do. Still, I may deem it a necessity and hope for the best. I think that people simply want a good reference (WP) to topics for reports and casual reading as opposed to more lengthy and unillustrated longer reading on WS. --Maury (William Maury Morris II (talk) 03:23, 7 August 2012 (UTC)
1996
Latest comment: 12 years ago5 comments4 people in discussion
Think about the technology to do that feat George. Just consider the millions of pieces of code if nothing else. Silicon Valley and silicon chips can come later on Mars from it's minerals. Too, most of sand is silica used in making glass but combined with other minerals it can be used for many things. Sure, I like science, it makes life better. William Maury Morris II (talk) 17:54, 8 August 2012 (UTC)
Years
Latest comment: 12 years ago2 comments2 people in discussion
Hi. How to behave with the year field in header (and following categorization) when a work is a collection of other works published in years different from the year of the collection itself?--Mpaa (talk) 10:27, 6 August 2012 (UTC)
I tend to use the date of publication for the basepage. Sometimes I add a different year to a subpage, often as a category rather than in the header. If so, I might leave a note in the notes field of the header, and occasionally in a HTML comment by the category, just to be clear about what I'm doing to any future editors. For example, The Shunned House: 1937 in the header and, in this case, the 1928 works category on the redirect page. That's just my approach, however. - AdamBMorgan (talk) 17:18, 6 August 2012 (UTC)
Adding different edition of a book?
Latest comment: 12 years ago2 comments2 people in discussion
When a book (say, "ABook") exists in Wikisource but is marked Template:no source and I found a different edition .djvu on the Internet Archive, is it better to create a new page "ABook (edition B)" for that edition and use that for proofreading, rather than throwing out all the old contents of "ABook" and replace it with the (has source, but unproofread OCR-quality) new content? - Juxtap (talk) 15:50, 6 August 2012 (UTC)
It can depend on the page and the state of the text. The best option is probably starting the new "ABook (edition B)" page for your proofreading. That said, I have overwritten some "no source" works in the past if I have a sourced and proofread edition of the text ready (especially if I cannot determine the source of "ABook"). In the meantime, however, I would suggest working on "Edition B." Things can always be changed later but it will be easier to overwrite the text at that time than it would be to overwrite it now and then attempt to recover it later (for whatever reason). - AdamBMorgan (talk) 17:26, 6 August 2012 (UTC)
Substantial foreign language scans on English Wikisource
Latest comment: 12 years ago8 comments4 people in discussion
I don't see any problem with the existing arrangement. Where the other language is on separate pages (as is the case with the Tractatus and possibly with Omar Khayyam), those pages can be marked as not needing proofreading as Mpaa has kindly done. German wikisource hasn't posted the Tractatus (in either the original or the two-language version) so it wasn't possible to transclude (or desirable IMO). Chris55 (talk) 09:03, 7 August 2012 (UTC)
What I am asking is if it would be necessary to make all the pages visible in the languages they were written in. It would of course be proper that the specific pages were proofread by a German speaker (in the English subdomain) and then linked to from the German subdomain; no problems with copyright could exist, and I'm sure that translingual transclusion is certainly possible: similarly with the Persian. I don't think it would be for anyone's benefit that the Index: page should have to be duplicated in another subdomain: the interfaces should be similar enough that anyone will come to en: and proofread the whole thing, then link to it from their language. Mahir256 (talk) 03:00, 8 August 2012 (UTC)
I would assume it's technically possible and that it works properly. That's great--though why haven't our more acquainted editors been more aware of the solution, instead of marking each foreign page as 'not needing of proofreading'? Mahir256 (talk) 07:55, 9 August 2012 (UTC)
I was aware that cross-wikisource transclusion was possible and searched the de wiki before requesting those pages to be marked. The reason that document was originally published in a 2-language form was not for the benefit of German-speakers (and the original will have different pagination) but because of the extreme technical precision of the original language. The translation here was regarded as too literal and eventually gave way to another (still in copyright). If someone is willing to proofread the German it could be moved to wikisource.org. I will enquire on German wikisource. Chris55 (talk) 08:32, 9 August 2012 (UTC)
OK after digging about, I am sure I was thinking of bugzilla:9890. I have no idea what the bug is really about, despite reading it twice. It is listed on a the Wishlist for Wikisource and for years I have been thinking it was about this situation.
The policy at oldWS states they accept texts in languages that do not have their own subdomains. This also fits my recollection of what they were doing before. I would be surprised if they would take a German/English text. As we both have larger communities than oldWS. Which isn't to say that oldWS can't be the solution here! But care and groundwork is needed--BirgitteSB02:44, 10 August 2012 (UTC)
Wikipedia down
Latest comment: 12 years ago1 comment1 person in discussion

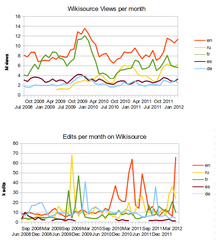

 Done with #switch. --Eliyak T·C 18:35, 1 July 2012 (UTC)
Done with #switch. --Eliyak T·C 18:35, 1 July 2012 (UTC)
 Oppose - I see no reason to grant the flag to another person who hardly contributes to en.WS directly in spite of having a "presence" here over the past few months by cleaning up double redirects (something that was handled just as well if not better by the regulars who do contribute here on an almost daily basis I might add). -- George Orwell III (talk) 07:47, 2 July 2012 (UTC)
Oppose - I see no reason to grant the flag to another person who hardly contributes to en.WS directly in spite of having a "presence" here over the past few months by cleaning up double redirects (something that was handled just as well if not better by the regulars who do contribute here on an almost daily basis I might add). -- George Orwell III (talk) 07:47, 2 July 2012 (UTC)
 — billinghurst sDrewth 13:56, 15 May 2011 (UTC)
— billinghurst sDrewth 13:56, 15 May 2011 (UTC)




 to represent WS on FB because I have learned over a long period of time that I can trust him. William Maury Morris II (talk) 14:43, 6 July 2012 (UTC)
to represent WS on FB because I have learned over a long period of time that I can trust him. William Maury Morris II (talk) 14:43, 6 July 2012 (UTC)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[12]](https://upload.wikimedia.org/wikipedia/commons/thumb/6/61/A_dictionary_of_the_Sunda_language_of_Java.djvu/page41-5100px-A_dictionary_of_the_Sunda_language_of_Java.djvu.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}